Transferir como PDF, PPTX




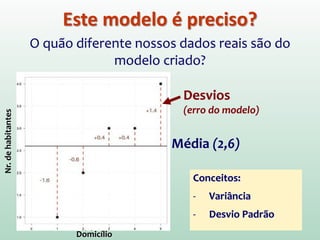
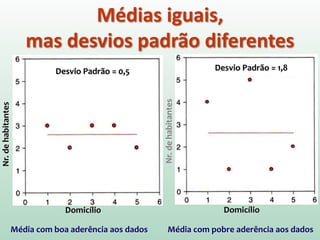




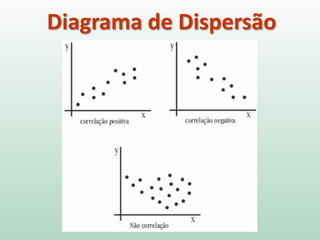



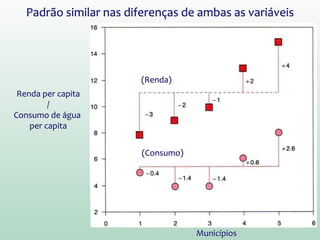


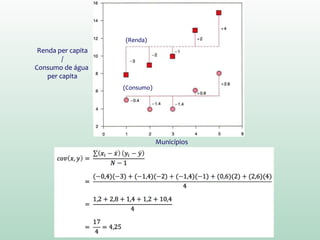






















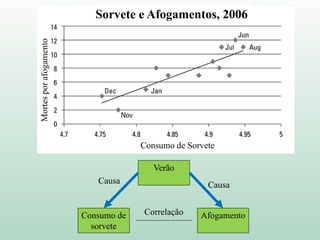


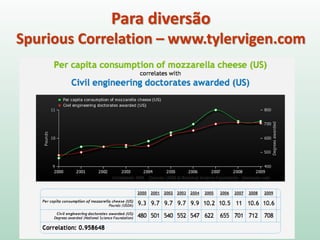
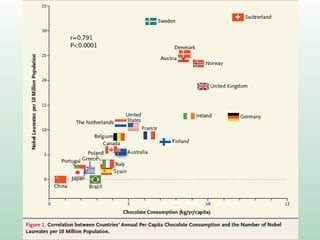





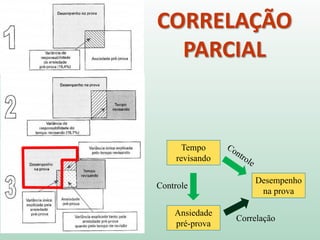
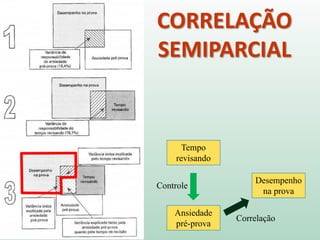

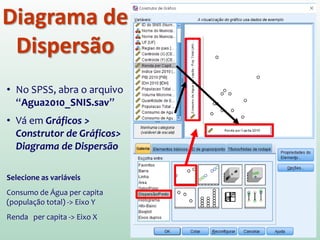
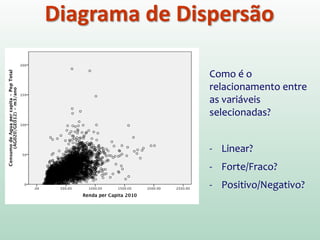
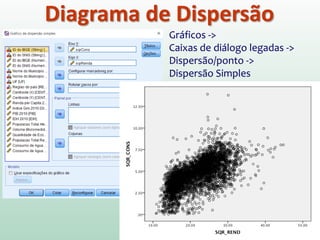
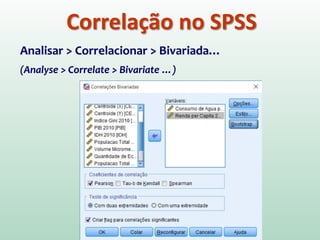
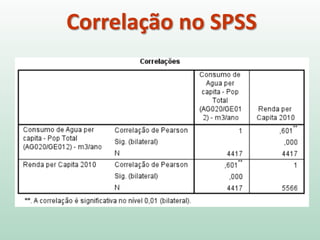


1) O documento discute o conceito de inferência estatística e como ela pode ser usada para estimar parâmetros populacionais a partir de amostras. 2) A média é apresentada como um modelo estatístico comum e como sua precisão pode ser medida pelo desvio padrão. 3) A correlação é introduzida como uma medida do relacionamento linear entre variáveis e como ela pode ser representada graficamente através de diagramas de dispersão.











































































































