Transferir como PDF, PPTX













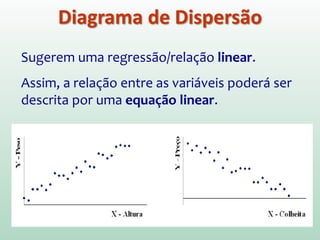

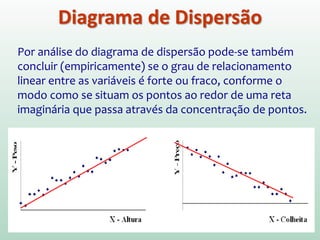
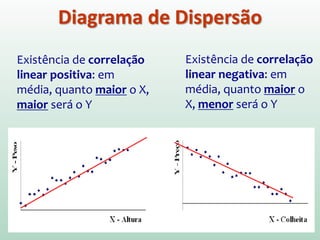








![Em particular, o método dos mínimos
quadrados requer que a soma dos n desvios
quadrados, denotado por Q, seja mínima:
2
10
1
][ ii
n
i
XYQ ββ −−= ∑=
Estimação dos Parâmetros](https://image.slidesharecdn.com/10regressaopartei-160804214203/85/Regressao-Linear-I-26-320.jpg)


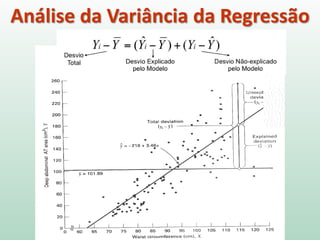
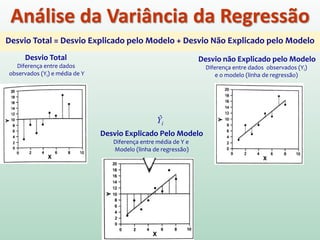
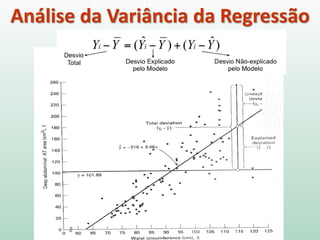







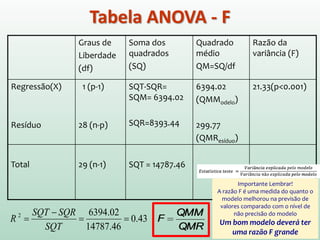



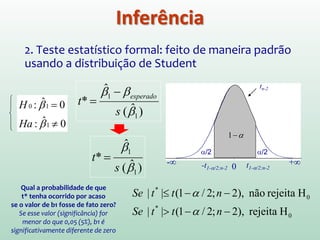











1) O documento apresenta os conceitos e métodos de regressão linear, incluindo estimação de parâmetros, avaliação do ajuste do modelo e interpretação dos resultados. 2) A regressão linear é usada para modelar a relação entre uma variável dependente e uma ou mais variáveis independentes através de uma equação linear. 3) A qualidade de ajuste do modelo é avaliada por meio da análise da variância, que parte a soma dos quadrados total em parte explicada pelo modelo e parte residual.






























































































