O documento discute conceitos estatísticos básicos como média, mediana, moda, desvio padrão e variância. Explica a diferença entre testes paramétricos e não paramétricos e como eles são usados para testar hipóteses estatísticas.
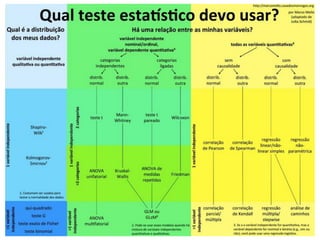
O que éestatística?
• Estatística é a ciência que se ocupa de coletar, organizar, analisar e
interpretar dados para que se tomem decisões.
Média
• Valor que “representa” vários outros.
Ex: Qual foi sua média em fisiologia no segundo semestre?
Suas notas: 9,3; 6,2; 8,5; 5,2.
• “S” = Soma das notas
• “n” = número de notas que você teve
• “M” = Média.
M = S/n = 9,3 + 6,2 + 8,5 + 5,2/4 = 7,3
4.
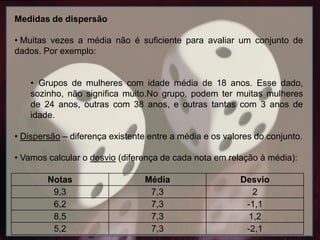
Medidas de dispersão
•Muitas vezes a média não é suficiente para avaliar um conjunto de
dados. Por exemplo:
• Grupos de mulheres com idade média de 18 anos. Esse dado,
sozinho, não significa muito.No grupo, podem ter muitas mulheres
de 24 anos, outras com 38 anos, e outras tantas com 3 anos de
idade.
• Dispersão – diferença existente entre a média e os valores do conjunto.
• Vamos calcular o desvio (diferença de cada nota em relação à média):
Notas Média Desvio
9,3 7,3 2
6,2 7,3 -1,1
8,5 7,3 1,2
5,2 7,3 -2,1
5.
• Outro dadoimportante em estatística: Soma dos desvios ao quadrado.
• Cada desvio é elevado ao quadrado e, em seguida, somados.
Variância
• Soma dos quadrados dos desvios dividida pelo número de ocorrências
• V = 11,06/4 = 2,765
Notas Média Desvio Quadrado dos
desvios
9,3 7,3 2 4
6,2 7,3 -1,1 1,21
8,5 7,3 1,2 1,44
5,2 7,3 -2,1 4,41
Soma dos quadrados dos desvios 11,06
6.
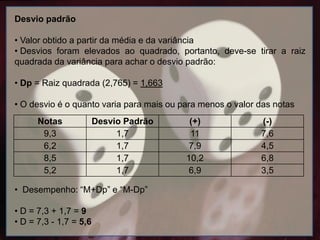
Desvio padrão
• Valorobtido a partir da média e da variância
• Desvios foram elevados ao quadrado, portanto, deve-se tirar a raiz
quadrada da variância para achar o desvio padrão:
• Dp = Raiz quadrada (2,765) = 1,663
• O desvio é o quanto varia para mais ou para menos o valor das notas
• Desempenho: “M+Dp” e “M-Dp”
• D = 7,3 + 1,7 = 9
• D = 7,3 - 1,7 = 5,6
Notas Desvio Padrão (+) (-)
9,3 1,7 11 7,6
6,2 1,7 7,9 4,5
8,5 1,7 10,2 6,8
5,2 1,7 6,9 3,5
7.
Erro Padrão deEstimativa
• Amostra qualquer de tamanho “n” – Média aritmética populacional
• Outra amostra aleatória – Média aritmética difere da primeira amostra
• Variabilidade das médias – Erro padrão
(precisão do cálculo da média populacional)
• Sx = s/raiz quadrada (n)
• Sx = erro padrão
• s = desvio padrão
• n = tamanho da amostra
• Observação: quanto melhor a precisão no cálculo da média
populacional, menor será o erro padrão.
8.
• Exemplo 1:Numa população obteve-se o desvio padrão de 3,52 com
uma amostra aleatória de 76 elementos. Qual o provável erro padrão?
• Sx = n/raiz quadrada (n)
• Sx = 3,52/raiz quadrada (76)
• Sx = 3,52/8,717797887081347
• Sx = 0,404 (a média pode variar para mais ou para menos nesse valor)
• Exemplo 2: Numa população obteve-se desvio padrão de 1,43 com uma
amostra aleatória de 134 elementos. Sabendo que para essa mesma
amostra obteve-se uma média de 7,75, determine o valor mais provável
para a média dos dados.
•Sx = n/raiz quadrada (n)
•Sx = 1,43/raiz quadrada (134)
•Sx = 0,123
• Média = 7,75 +/- 0,12 (a média pode ser 7,87 ou 7,63)
9.
Média x Mediana
•Média – Soma das observações divididas pelos nos de observações.
• Média de: 3, 3, 4, 5, 5, 5, 6, 8, 9 = (3+3+4+5+5+5+6+8+9)/9 = 5,33
• Mediana = Número que ocupa a posição central da série de
observações.
• Determine a mediana das duas séries de dados:
(a) 8, 4, 9, 5, 5.
(b) 7, 5, 2, 4, 5, 9.
Respostas:
(a) Para séries pares
4, 5, 5, 8, 9 (o valor em negrito é a mediana)
(b) Para séries ímpares
2, 4, 5, 5, 7, 9 = (2+4+5+5+7+9)/2 = 16
*** Média + Desvio padrão.
*** Mediana + Erro padrão.
10.
Diferença entre Medianae Moda
• Mediana = Número que ocupa a posição central da série de
observações.
• Moda = Valor que detém o maior número de observações; o valor que
ocorre com maior frequência num conjunto de dados (valor mais comum).
É especialemnte útil quando os valores ou observações não são
numéricos, uma vez que mediana e média podem não ser bem definidas.
• Amodal – não possui moda
{1,5,9,2,6,3,4,8,7}
• Multimodal – possui mais do que dois valores modais.
{1,1,2,5,5,3,4,7,7,8,9}
• Bimodal – possui dois valores modais
{1,4,7,7,9,9}
{pêra, uva, laranja, pessego, pessego, pessego, abacaxi}
11.
Teste t-Student
• Testede hipóteses – Conceitos estatísticos para rejeitar ou não uma hipótese
nula, ou seja, quando a estatística do teste, na verdade, segue uma distribuição
normal, mas a variância da população é desconhecida.
Hipótese nula – Apresentada sobre determinados fatos estatísticos, e cuja
falsidade de um determinado teste de hipóteses tenta-se provar. Geralmente a
hipótese nula afirma que não existe relação entre dois fenômenos medidos.
Ex: (1) Um aumento de 5% no preço de um determinado produto não afetará
adversamente as vendas dele. (2) O aumento da diferença de potencial não afeta
a corrente em um condutor.
• Hipótese que pretende-se confrontar com os dados.
• Quando não é possível ou viável observar toda a população – observação de
uma amostra aleatória da população (parâmetro mais frequente – média +
desvio padrão).
• Muitas vezes a hipótese nula consiste em afirmar que os parâmetros ou
características matemáticas de duas ou mais populações são idênticos, ou seja,
uma igualdade (hipóteses simples).
12.
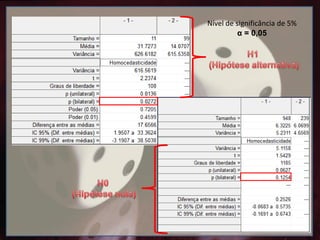
Hipótese Nula (H0)
•Duas amostras aleatórias de caranguejos. Uma amostra oriunda do Manguezal do
Portinho da Praia Grande e a outra amostra oriunda do Manguezal Guaratuba de Bertioga.
Queremos ver se existe diferença no tamanho dos indivíduos dessas duas populações. A
hipótese nula seria - "que a média do tamanho dos indivíduos amostrados da população de
Praia Grande é a mesma dos indivíduos amostrados em Bertioga.“
H0: u1 = u2
• u1 = a média do tamanho dos indivíduos da população 1
• u2 = a média do tamanho dos indivíduos da população 2
H0: u1-u2 = 0 (α = 0,05)
* α - nível de significância mais comumente aceito.
• Duas decisões podem ser tomadas:
(1) Rejeitar a hipótese nula
(2) Não rejeitar a hipótese nula – Salienta-se que não rejeitar a hipótese nula significa
apenas que não se conseguiu, através dos dados disponíveis, demonstrar a sua
falsidade, o que difere completamente de provar a sua veracidade.
Analogia: Nos processos judiciais, a hiótese nula seria que o réu é inocente. Durante o julgamento
tenta-se provar a falsidade desta hipótese, ou seja, que o réu é culpado. Entretanto no caso de não
conseguir provar a culpa, isso não significa que o réu seja inocente; significa apenas que não foram
encontradas provas suficientes. O fato de não se poder “aceitar” a hipótese nula, porém apenas
“não a rejeitar”, tem a ver com os erros que podem ser cometidos ao rejeitar ou não rejeitar a
hipótese.
13.
Hipótese Alternativa (H1)
•Hipótese contraditória a hipótese nula.
• A escolha do par hipótese nula/hipótese alternativa depende do
contexto do problema, do parâmtero que se deseja testar e das
conclusões a que se pretende chegar. Deve-se sempre levar em conta
que a hipótese nula é sempre formulada sob a forma de igualdade.
• Hipótese nula (H0: u = 0)
• Hipótese alternativa (H1: u # 0; H1: u < 1; H1: u > 1)
• Cada par de hipótese nula/hipótese alternativa conduz a um teste de
hipóteses diferente. Uma diferente hipótese alternativa pode conduzir a
uma decisão diferente em comparação a hipótese nula.
14.
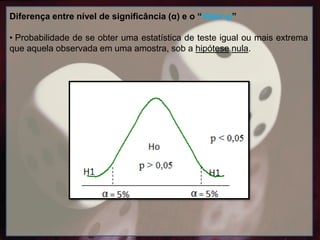
Diferença entre nívelde significância (α) e o “Valor-p”
• Não confundir nível de significância com probabilidade de significância
• Ex: Ao fazer um teste com uma média, se fosse possível repetir um
número muito grande de amostras para calcular a média, em
aproximadamente 5% dessas amostras, seria rejeitada a hipótese nula
quando esta é verdadeira.
Experimento real:
1 amostra qualquer 5% onde a hipótese nula é realmente verdadeira.
95% onde a hipótese nula é realmente falsa.
* Estabelece-se o intervalo de confiança
• Intervalo de confiança de 95% - equivalente a um Erro do Tipo 1 (5%).
• Tem-se a confiança que o intervalo contêm o parâmetro estimado.
• Uma vez que reporta-se um intervalo numérico, o parâmetro populacional
desconhecido ou está dentro do intervalo ou fora; não existe uma
probabilidade desse intervalo conter o parâmetro. *Necessidade testes!
15.
Diferença entre nívelde significância (α) e o “Valor-p”
• Probabilidade de se obter uma estatística de teste igual ou mais extrema
que aquela observada em uma amostra, sob a hipótese nula.
16.
Teste t-Student (Testede hipóteses) – Conceitos estatísticos para
rejeitar ou não uma hipótese nula, ou seja, quando a estatística do teste,
na verdade, segue uma distribuição normal, mas a variância da
população é desconhecida.
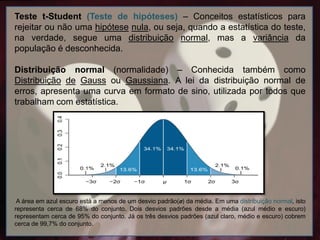
Distribuição normal (normalidade) – Conhecida também como
Distribuição de Gauss ou Gaussiana. A lei da distribuição normal de
erros, apresenta uma curva em formato de sino, utilizada por todos que
trabalham com estatística.
A área em azul escuro está a menos de um desvio padrão(σ) da média. Em uma distribuição normal, isto
representa cerca de 68% do conjunto. Dois desvios padrões desde a média (azul médio e escuro)
representam cerca de 95% do conjunto. Já os três desvios padrões (azul claro, médio e escuro) cobrem
cerca de 99,7% do conjunto.
17.
Variância
• A variânciade uma variável aleatória é uma medida da sua dispersão estatística,
indicando quão longe em geral os seus valores se encontram do valor esperado.
Variável aleatória – pode ser entendida como uma variável quantitativa, cujo
resultado (valor) depende de fatores aleatórios.
• A variância não é medida ponto a ponto (é a "distância média") entre a média das
amostras e seus pontos...
Ex: Temos dois pontos 1 e 3, a média é 2 e a variância é 1, pois cada um dos
pontos está distante em uma unidade da média.
Homo e heterocedasticidade (medida de dispersão da variância, não tem nada a
ver com o valor do “p”. O “p” valida se uma hipótese é nula ou alternativa)
HETEROCEDASTICIDADE - Forte dispersão dos dados em torno de uma reta.
* Uma distribuição de frequências em que todas as distribuições condicionadas têm
desvios padrão diferentes.
HOMOCEDASTICIDADE - Os dados regredidos encontram-se mais
homogeneamente e menos dispersos (concentrados) em torno da reta de
regressão do modelo.
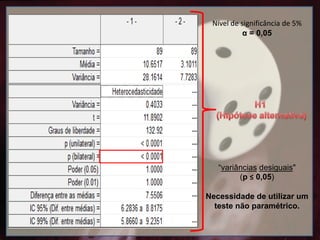
Nível de significânciade 5%
α = 0,05
“variâncias desiguais"
(p ≤ 0,05)
Necessidade de utilizar um
teste não paramétrico.
20.
Testes paramétrico enão paramétrico
PARAMÉTRICO: Refere-se a média e ao desvio-padrão, que são parâmetros que
definem as populações que apresentam distribuição normal.
NÃO PARAMÉTRICO: Refere-se a mediana e erro padrão.
Razão para a transformação dos dados
• Quando algum dos requisitos para o emprego da estatística paramétrica
(normalidade da distribuição dos erros, homogeneidade das variâncias e
aditividade dos efeitos dos fatores de variação) não puder ser preenchido
pelos dados da sua amostra experimental, o pesquisador ainda pode tentar o
recurso da transformação dos dados, antes de optar pela aplicação da estatística
não-paramétrica. É um recurso que sempre vale a pena tentar, porque a
estatística paramétrica é evidentemente mais poderosa que a não-paramétrica.
• A estatística não-paramétrica foi desenvolvida como um recurso complementar,
destinado a suprir a necessidade de testes estatísticos nos casos em que alguma
restrição desaconselhava o uso da estatística paramétrica, ou quando a própria
natureza dos dados, muitas vezes não exatamente numéricos, vedava a
aplicação desta.
21.
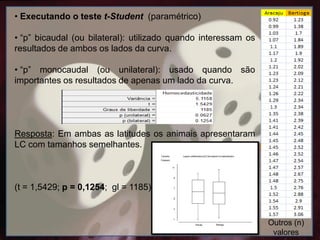
• Executando oteste t-Student (paramétrico)
• “p” bicaudal (ou bilateral): utilizado quando interessam os
resultados de ambos os lados da curva.
• “p” monocaudal (ou unilateral): usado quando são
importantes os resultados de apenas um lado da curva.
Resposta: Em ambas as latitudes os animais apresentaram
LC com tamanhos semelhantes.
(t = 1,5429; p = 0,1254; gl = 1185)
Outros (n)
valores
22.
.
.
Amostragem de dadosnão paramétricos
• Teste t-Student (independência).
• Programa mostra: “variâncias desiguais" (p ≤ 0,05)
• Aplicação da estatística não-paramétrica.
Teste Mann Whitney (Teste U) - Os valores de “U” calculados pelo teste
avaliam o grau de entrelaçamento dos dados dos dois grupos após a
ordenação.
• Determinada população tende a ter valores “extremos”.
• Distribuições não normais (mistura de distribuições normais).
Resposta: Existe diferença na densidade
populacional das duas latitudes. A
diferença mediana de Uca
leptodactylus é maior em Aracaju do
que em Bertioga.
( Mann-Whitney: U = 582; p<0,0001).
Outros (n)
valores
23.
.
.
ANOVA (Análise deVariância) – Teste F
• Visa fundamentalmente verificar se existe uma diferença significativa entre as
médias e se os fatores exercem influência em alguma variável dependente. Dessa
forma, permite que vários grupos sejam comparados a um só tempo (fatores
podem ser de origem qualitativa ou quantitativa), porém a variável dependente
deverá necessariamente ser contínua*.
*Qualquer valor numérico em um determinado intervalo ou coleção de intervalos.
Ex: Lançamento de um disco – distância classificatória máxima de 50m e
distância classificatória mínima de 20m. Tem-se que 20 ≥ X ≤ 50. Esse intervalo
permite infinitas interpretações. O disco poderia cair, por exemplo em 49 metros,
52 centímetros e 20 milímetros.
• Teste paramétrico (variável de interesse deve ter distribuição normal) e os
grupos devem ser independentes.
24.
.
.
ANOVA (Análise deVariância)
• Compara várias médias ao mesmo tempo - variável contínua x variável categórica.
• Nos diz se existe diferença entre pelo menos um par de médias das categorias de
exposição (diferentes tratamentos).
Diferença entre Teste t-Student x Análise de Variância (ANOVA)
• Se H0 não for rejeitada, não é preciso fazer mais nada.
• Se H0 for rejeitada, testamos dentro dos subgrupos de médias se há alguma que
seja diferente das demais.
Pressupostos para a realização da ANOVA
• Distribuição aproximadamente normal
• Variância dos dados é semelhante para todos os grupos comparados
• Observações são independentes
(Infinitas interpretações) (Salinidade e temperatura)
25.
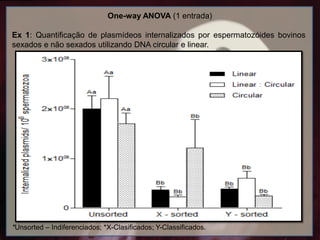
One-way ANOVA (1entrada)
Ex 1: Quantificação de plasmídeos internalizados por espermatozóides bovinos
sexados e não sexados utilizando DNA circular e linear.
*Unsorted – Indiferenciados; *X-Clasificados; Y-Classificados.
26.
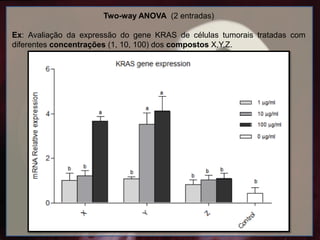
Two-way ANOVA (2entradas)
Ex: Avaliação da expressão do gene KRAS de células tumorais tratadas com
diferentes concentrações (1, 10, 100) dos compostos X,Y,Z.
27.
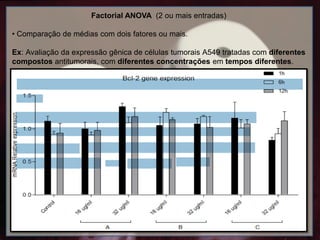
Factorial ANOVA (2ou mais entradas)
• Comparação de médias com dois fatores ou mais.
Ex: Avaliação da expressão gênica de células tumorais A549 tratadas com diferentes
compostos antitumorais, com diferentes concentrações em tempos diferentes.
28.
Testes post-hoc (“aposteriori”) [ANOVA]
• São realizados apenas se houver diferenças significativas entre as médias
(p < 0,05)
• Identificam onde está a diferença e quais são os grupos que diferem.
• Existem diversos testes post-hoc. Ex:
• Tukey [mais usado e mais exigente]
• SNK (Student-Newman-Keuls)
•Distribuição aproximadamente normal
(SIMÉTRICA)
• Variância dos dados é semelhante
para todos os grupos comparados
• Observações são independentes
29.
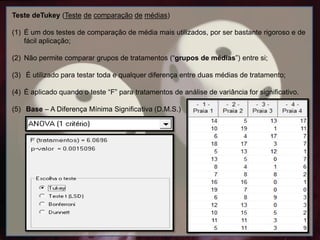
Teste deTukey (Testede comparação de médias)
(1) É um dos testes de comparação de média mais utilizados, por ser bastante rigoroso e de
fácil aplicação;
(2) Não permite comparar grupos de tratamentos (“grupos de médias”) entre si;
(3) É utilizado para testar toda e qualquer diferença entre duas médias de tratamento;
(4) É aplicado quando o teste “F” para tratamentos de análise de variância for significativo.
(5) Base – A Diferença Mínima Significativa (D.M.S.)
One-way ANOVA (1entrada)
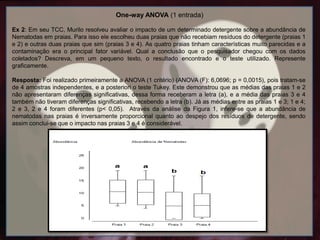
Ex 2: Em seu TCC, Murilo resolveu avaliar o impacto de um determinado detergente sobre a abundância de
Nematodas em praias. Para isso ele escolheu duas praias que não recebiam resíduos do detergente (praias 1
e 2) e outras duas praias que sim (praias 3 e 4). As quatro praias tinham características muito parecidas e a
contaminação era o principal fator variável. Qual a conclusão que o pesquisador chegou com os dados
coletados? Descreva, em um pequeno texto, o resultado encontrado e o teste utilizado. Represente
graficamente.
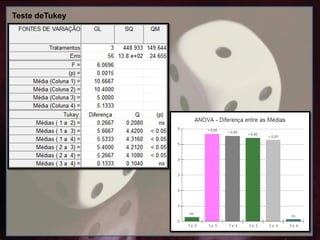
Resposta: Foi realizado primeiramente a ANOVA (1 critério) (ANOVA (F): 6,0696; p = 0,0015), pois tratam-se
de 4 amostras independentes, e a posteriori o teste Tukey. Este demonstrou que as médias das praias 1 e 2
não apresentaram diferenças significativas, dessa forma receberam a letra (a), e a média das praias 3 e 4
também não tiveram diferenças significativas, recebendo a letra (b). Já as médias entre as praias 1 e 3; 1 e 4;
2 e 3, 2 e 4 foram diferentes (p< 0,05). Através da análise da Figura 1, infere-se que a abundância de
nematodas nas praias é inversamente proporcional quanto ao despejo dos resíduos de detergente, sendo
assim conclui-se que o impacto nas praias 3 e 4 é considerável.
32.
Teste SNK (Student-Newman-Keuls)
•Procura contornar os inconvenientes do teste t-Student, quando mais de dois
tratamentos estão envolvidos no experimento.
• O teste procura ajustar o valor de “t” de acordo com as distâncias entre as
médias ordenadas dos tratamentos.
Definição: Uma relação decrescente de “t” médias (n médias), duas delas
(y1 e y2) possuem significância se o valor calculado em módulo para tsnk for
maior ou igual ao valor tabelado para o nível de significância α (costuma ser
α = 0,05) com graus de liberdade* para resíduo e uma distância i entre as
médias (i = p + 2). [p = número de médias existentes entre as duas médias [+2]
comparadas na relação decrescente.
Definições para grau de liberdade:
* Graus de liberdade (gl): Número de classes de resultados menos o número de
informações da amostra que é necessário para o cálculo dos valores esperados
em cada classe (número de classes – 1).
Ex : Qual o grau de liberdade de uma herança genética onde existem duas
características (uma recessiva e outra dominante)?
[Resposta: gl = n-1, portanto gl = 2-1 = 1]
33.
** No casode dados tabelados, deve-se considerar apenas a área dos dados,
dessa forma gl = (número de linhas -1 x número de colunas -1)
*** Em estatística usa-se gl = n-2 (dois refere-se a linha + coluna)
Ex: Qual o grau de liberdade de um n = 272?
[Resposta: gl = 272-2 = 270]
• Observação: Usa-se o valor de “gl” para encontrar o valor do “t” tabelado em
análises estatísticas de regressão múltipla. Com o valor do “t” calculado + o valor
do “t” tabelado vemos quais hipóteses (nula ou alternativa) validar.
NÃO CONFUNDIR ‘Teste t-Student ‘ de ‘Teste t’ usado em análise de regressão.
34.
Amostragem de dadosnão paramétricos
• ANOVA
• Programa mostra que a distribuição não é normal (assimétrica).
• Aplicação da estatística não-paramétrica.
Teste Kruskal Wallis (One-Way ANOVA) [Teste H] – Usado para testar a
hipótese nula de que todas as populações possuem funções de distribuição iguais
contra a hipótese alternativa de que ao menos duas populações possuem funções
de distribuição diferentes.
• Usado quando não há distribuição normal.
• Não coloca nenhuma restrição (ex: amostras independentes e normalmente
distribuídas) sobre a comparação.
• Quando o teste conduz a resultados significativos, pelo menos uma das
amostras é diferente das restantes.
• O teste não identifica onde ocorrem e quantas são as diferenças.
35.
Teste Kruskal Wallis(One-Way ANOVA) [Teste H]
O teste não identifica onde ocorrem e quantas são as diferenças.
Ex:
• Validou a hipótese alternativa (H1)
•Ao menos duas populações possuem funções de distribuição diferentes.
36.
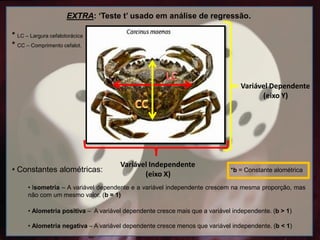
EXTRA: ‘Teste t’usado em análise de regressão.
* LC – Largura cefalotorácica
* CC – Comprimento cefalot.
• Constantes alométricas: *b = Constante alométrica
• Isometria – A variável dependente e a variável independente crescem na mesma proporção, mas
não com um mesmo valor. (b = 1)
• Alometria positiva – A variável dependente cresce mais que a variável independente. (b > 1)
• Alometria negativa – A variável dependente cresce menos que variável independente. (b < 1)
Variável Independente
(eixo X)
Variável Dependente
(eixo Y)
37.
Testando o valorda constante alométrica
Hipóteses estatísticas:
• Hipótese nula (H0) – Isometria [b=1]
• Hipótese alternativa (H1) – Alometria [b#1]
o Alometria positiva [b>1]
o Alometria negativa [b<1]
EXTRA: ‘Teste t’ usado em análise de regressão.
Outros (n) valores
38.
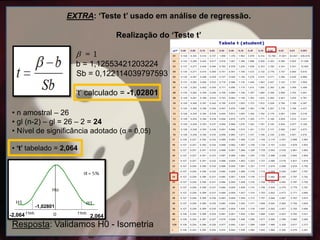
EXTRA: ‘Teste t’usado em análise de regressão.
Ex: Programa Statistica - Plotar dados (logaritimizados) - Clicar em "Statistics" -
"Multiple Regression" - Definir variáveis independentes e dependentes -
"Regression results“.
Dados fornecidos pelo programa:
• b = 1,12553421203224
• Sb (Erro padrão do b) = 0,122114039797593
Realização do ‘Teste t’
• – constante alométrica ( = 1)
• b – valor calculado para constante alométrica
• Sb – erro padrão da constante alométrica
• Grau de liberdade (gl = n-2)
39.
EXTRA: ‘Teste t’usado em análise de regressão.
Realização do ‘Teste t’
‘t’calculado > ‘t’ tabelado
Valida hipótese alternativa – H1 [crescimento alométrico]
‘t’ calculado < ‘t’ tabelado
Valida a hipótese nula – H0 [crescimento isométrico]
40.
EXTRA: ‘Teste t’usado em análise de regressão.
Realização do ‘Teste t’
= 1
b = 1,12553421203224
Sb = 0,122114039797593
‘t‘ calculado = -1,02801
• n amostral – 26
• gl (n-2) – gl = 26 – 2 = 24
• Nível de significância adotado (α = 0,05)
• ‘t’ tabelado = 2,064
Resposta: Validamos H0 - Isometria
2,064-2,064
-1,02801
















![Testes post-hoc (“a posteriori”) [ANOVA]
• São realizados apenas se houver diferenças significativas entre as médias
(p < 0,05)
• Identificam onde está a diferença e quais são os grupos que diferem.
• Existem diversos testes post-hoc. Ex:
• Tukey [mais usado e mais exigente]
• SNK (Student-Newman-Keuls)
•Distribuição aproximadamente normal
(SIMÉTRICA)
• Variância dos dados é semelhante
para todos os grupos comparados
• Observações são independentes](https://image.slidesharecdn.com/bioestatstica-140514071732-phpapp01/85/Bioestatistica-28-320.jpg)
![Teste SNK (Student-Newman-Keuls)
• Procura contornar os inconvenientes do teste t-Student, quando mais de dois
tratamentos estão envolvidos no experimento.
• O teste procura ajustar o valor de “t” de acordo com as distâncias entre as
médias ordenadas dos tratamentos.
Definição: Uma relação decrescente de “t” médias (n médias), duas delas
(y1 e y2) possuem significância se o valor calculado em módulo para tsnk for
maior ou igual ao valor tabelado para o nível de significância α (costuma ser
α = 0,05) com graus de liberdade* para resíduo e uma distância i entre as
médias (i = p + 2). [p = número de médias existentes entre as duas médias [+2]
comparadas na relação decrescente.
Definições para grau de liberdade:
* Graus de liberdade (gl): Número de classes de resultados menos o número de
informações da amostra que é necessário para o cálculo dos valores esperados
em cada classe (número de classes – 1).
Ex : Qual o grau de liberdade de uma herança genética onde existem duas
características (uma recessiva e outra dominante)?
[Resposta: gl = n-1, portanto gl = 2-1 = 1]](https://image.slidesharecdn.com/bioestatstica-140514071732-phpapp01/85/Bioestatistica-32-320.jpg)
![** No caso de dados tabelados, deve-se considerar apenas a área dos dados,
dessa forma gl = (número de linhas -1 x número de colunas -1)
*** Em estatística usa-se gl = n-2 (dois refere-se a linha + coluna)
Ex: Qual o grau de liberdade de um n = 272?
[Resposta: gl = 272-2 = 270]
• Observação: Usa-se o valor de “gl” para encontrar o valor do “t” tabelado em
análises estatísticas de regressão múltipla. Com o valor do “t” calculado + o valor
do “t” tabelado vemos quais hipóteses (nula ou alternativa) validar.
NÃO CONFUNDIR ‘Teste t-Student ‘ de ‘Teste t’ usado em análise de regressão.](https://image.slidesharecdn.com/bioestatstica-140514071732-phpapp01/85/Bioestatistica-33-320.jpg)
![Amostragem de dados não paramétricos
• ANOVA
• Programa mostra que a distribuição não é normal (assimétrica).
• Aplicação da estatística não-paramétrica.
Teste Kruskal Wallis (One-Way ANOVA) [Teste H] – Usado para testar a
hipótese nula de que todas as populações possuem funções de distribuição iguais
contra a hipótese alternativa de que ao menos duas populações possuem funções
de distribuição diferentes.
• Usado quando não há distribuição normal.
• Não coloca nenhuma restrição (ex: amostras independentes e normalmente
distribuídas) sobre a comparação.
• Quando o teste conduz a resultados significativos, pelo menos uma das
amostras é diferente das restantes.
• O teste não identifica onde ocorrem e quantas são as diferenças.](https://image.slidesharecdn.com/bioestatstica-140514071732-phpapp01/85/Bioestatistica-34-320.jpg)
![Teste Kruskal Wallis (One-Way ANOVA) [Teste H]
O teste não identifica onde ocorrem e quantas são as diferenças.
Ex:
• Validou a hipótese alternativa (H1)
•Ao menos duas populações possuem funções de distribuição diferentes.](https://image.slidesharecdn.com/bioestatstica-140514071732-phpapp01/85/Bioestatistica-35-320.jpg)
![Testando o valor da constante alométrica
Hipóteses estatísticas:
• Hipótese nula (H0) – Isometria [b=1]
• Hipótese alternativa (H1) – Alometria [b#1]
o Alometria positiva [b>1]
o Alometria negativa [b<1]
EXTRA: ‘Teste t’ usado em análise de regressão.
Outros (n) valores](https://image.slidesharecdn.com/bioestatstica-140514071732-phpapp01/85/Bioestatistica-37-320.jpg)

![EXTRA: ‘Teste t’ usado em análise de regressão.
Realização do ‘Teste t’
‘t’calculado > ‘t’ tabelado
Valida hipótese alternativa – H1 [crescimento alométrico]
‘t’ calculado < ‘t’ tabelado
Valida a hipótese nula – H0 [crescimento isométrico]](https://image.slidesharecdn.com/bioestatstica-140514071732-phpapp01/85/Bioestatistica-39-320.jpg)