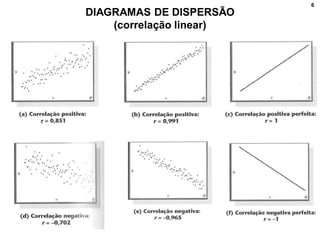
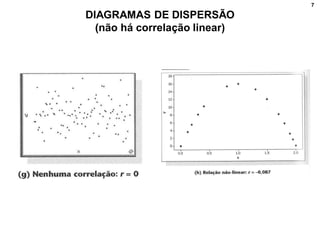
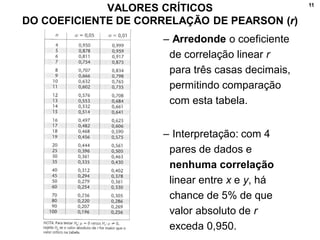
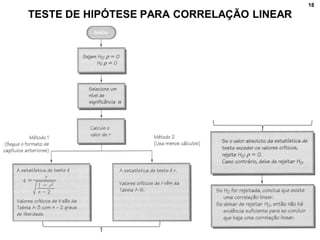
1. O documento discute correlação, análise fatorial e regressão. Apresenta conceitos básicos e métodos para analisar a relação entre variáveis e prever valores de variáveis.
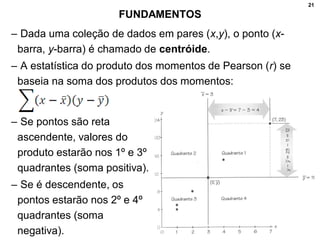
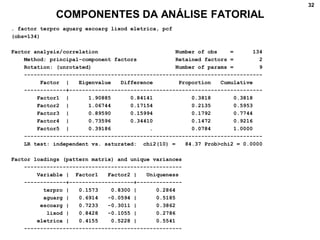
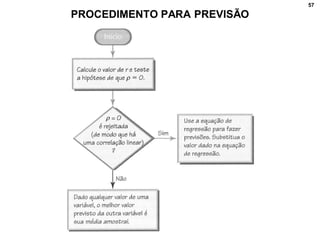
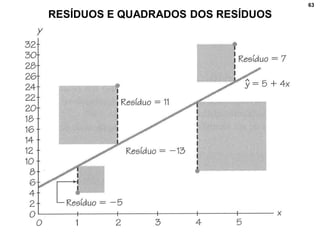
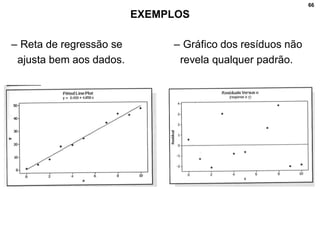
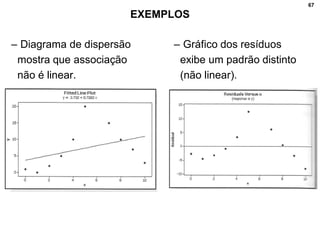
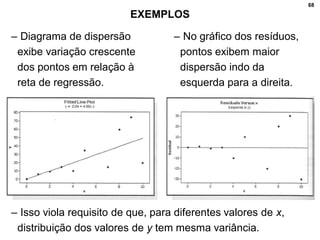
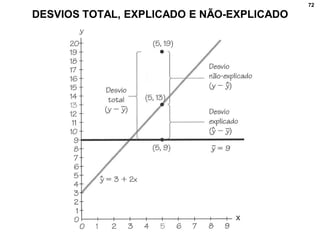
2. Inclui explicações sobre coeficiente de correlação, diagramas de dispersão, análise fatorial, regressão linear e testes de hipóteses para correlação.
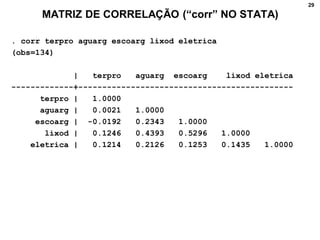
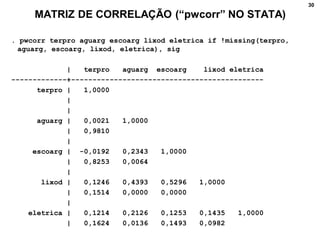
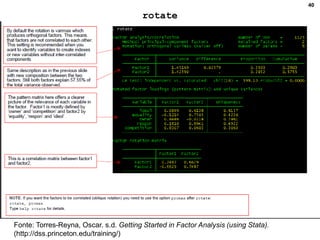
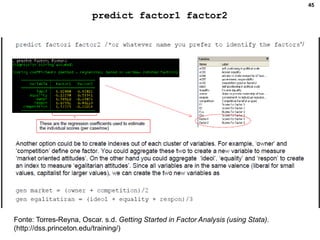
3. Fornece detalhes técnicos sobre cálculos e comandos no Stata para realizar análises estatísticas destes métodos.