Baixado 427 vezes





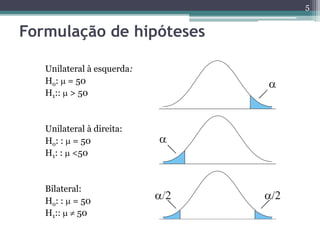
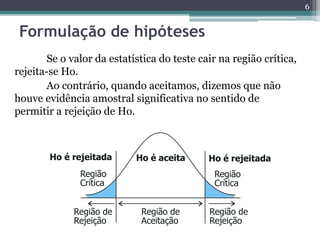









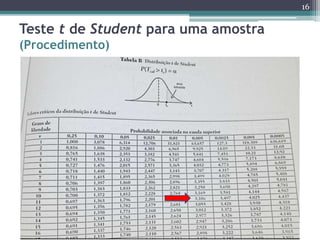


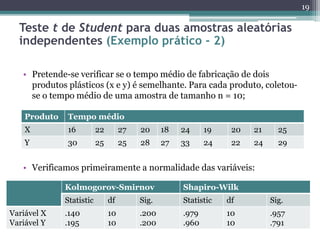

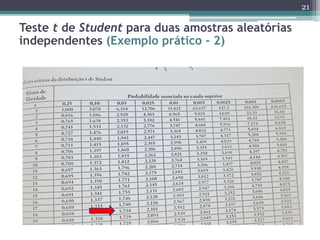




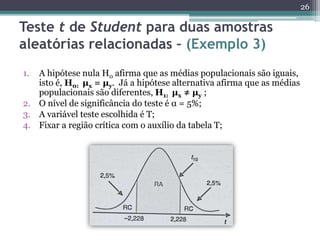






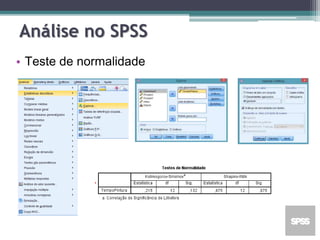
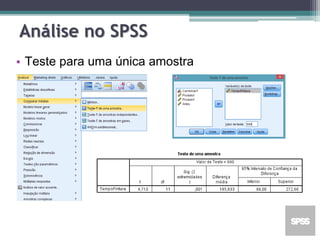
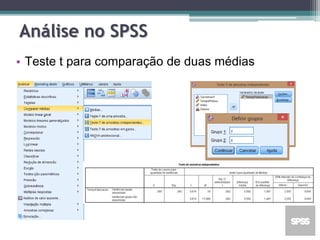
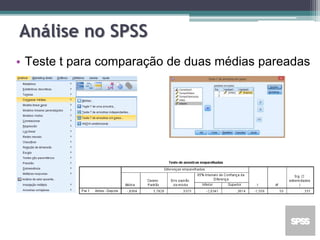



Este documento apresenta uma agenda para um curso ou palestra sobre testes paramétricos. A agenda inclui introdução aos testes paramétricos, formulação de hipóteses, tipos de erros, testes de normalidade, teste t de Student para uma e duas amostras e aplicações computacionais. Exemplos práticos são fornecidos para ilustrar os procedimentos dos testes t.



































































