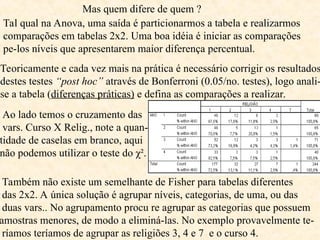
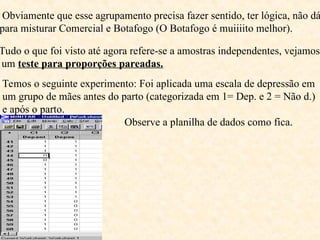
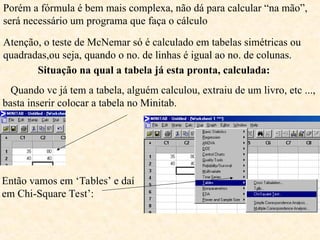
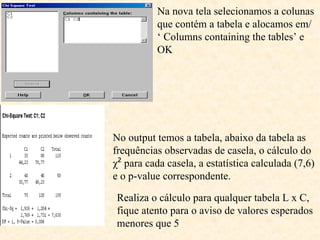
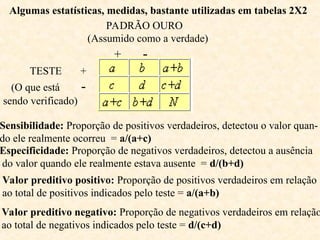
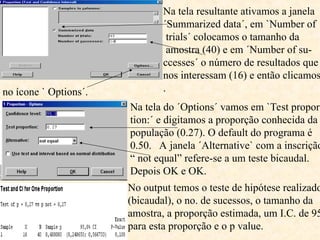
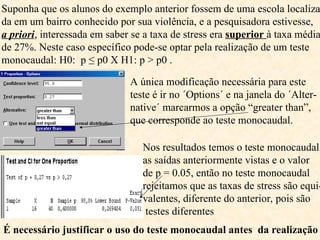
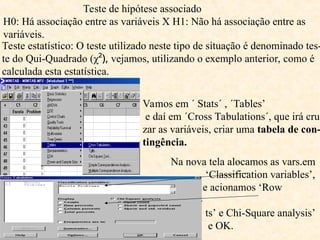
O documento aborda a análise de variáveis categóricas e numéricas, incluindo testes de hipótese como o teste de proporção e o qui-quadrado para comparar proporções entre grupos independentes. Ele detalha a execução desses testes, suposições necessárias, e oferece exemplos práticos de como realizar os cálculos utilizando software estatístico como o Minitab. Além disso, discute a interpretação dos resultados e casos em que deve ser aplicado o teste exato de Fisher em vez do qui-quadrado.






![As freq. esperadas para cada casela são estimadas do seguinte modo:
Cas. 1(linha) 1(coluna) = [Marg. linha 1 (32) * Marg. coluna 1 (40)]/ Total
(60) = (32*40)/60 = 21,33.
Cas. 1(linha) 2(coluna) = [Marg. linha 1 (32) * Marg. coluna 2 (20)]/ Total
(60) = (32*20)/60 = 10,67.
E assim por diante para cada uma das caselas da tabela.
O teste do χ² basicamente irá medir se a distância entre o observado e o
Além das frequências observadas existem as frequências esperadas, que
são calculadas a partir das marginais das linhas (32 e 26) e das margi-
nais das colunas (40 e 20)](https://image.slidesharecdn.com/aula-7-17-241126112013-0b3b4808/85/tipos-de-variables-estadisticas-ejemplosppt-10-320.jpg)