Baixar para ler offline














































![Efeitos Principais e Interação
• No desenho fatorial 22 podemos definir o efeito médio de um fator como a
mudança na resposta produzido pela mudança no nível do fator, tirando a média
sobre os outros níveis do outro fator.
• O efeito de A no nível baixo de B é
• O efeito de A no nível alto de B é
• O efeito médio da interação AB é a diferença média entre o efeito de A no nível
alto de B e o efeito de A no nível baixo de B
[a -(1)]
n
[ab- b]
n](https://image.slidesharecdn.com/apresentacaoeva-201026015116/85/Regressao-linear-50-320.jpg)












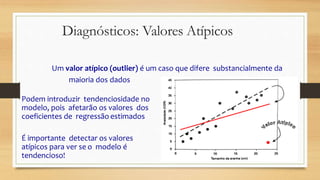
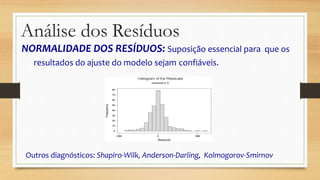
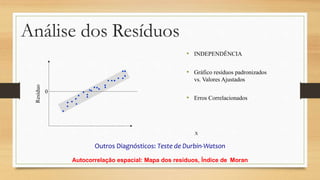
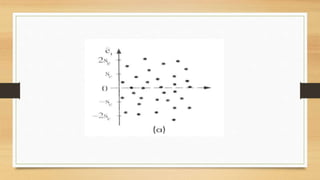
Este documento discute regressão linear, que analisa a relação entre uma variável resposta e uma ou mais variáveis preditoras. Apresenta modelos de regressão simples e múltipla, métodos de seleção de variáveis, diagnósticos de valores atípicos e pressupostos da regressão linear.













































![[Grupo 7] Conceitualização do Modelo.pptx.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/grupo7conceitualizaodomodelo-250829005610-621143ec-thumbnail.jpg?width=640&height=640&fit=bounds)































