Baixado 20 vezes



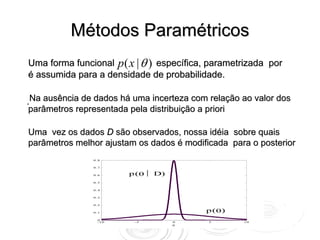





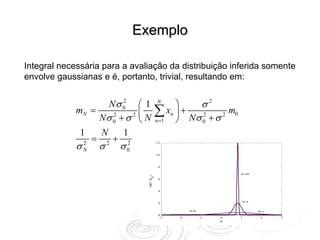



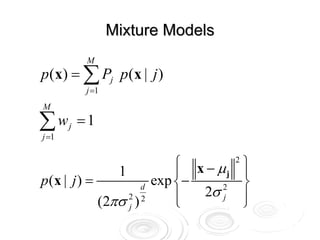








O documento discute métodos para estimar densidades de probabilidade a partir de dados, incluindo métodos paramétricos bayesianos, métodos de núcleo e misturas de distribuições. O algoritmo EM é descrito como uma abordagem para inferir parâmetros de misturas de distribuições maximizando a verossimilhança dos dados.











![[Robson] 7. Programação Não Linear Irrestrita](https://cdn.slidesharecdn.com/ss_thumbnails/irrestrita01-120311165949-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Robson] 5. Análise de Sensibilidade](https://cdn.slidesharecdn.com/ss_thumbnails/sensibilidade-120311174016-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Robson] 4. Dualidade](https://cdn.slidesharecdn.com/ss_thumbnails/dualidade-120311163806-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Alexandre] 8. Não Linear Restrita](https://cdn.slidesharecdn.com/ss_thumbnails/restrita-01-120327145714-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


































































