Transferir como PDF, PPTX






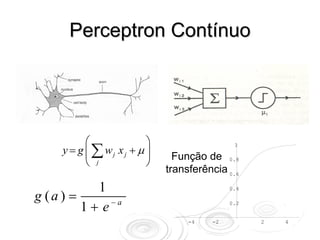
![Gradient Descent
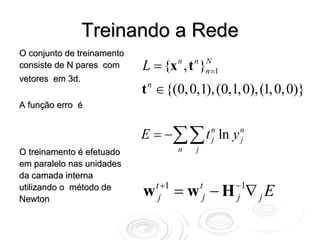
1 N
A função erro é E (w ) = ∑ [ yn (w ) − tn ]2
2 n =1
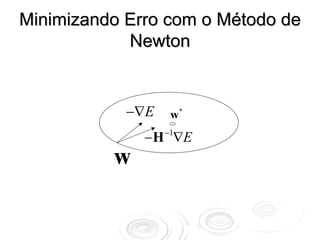
Correção na direção de
maior decréscimo w t +1 = w t − η ∇E Wt
do erro
N
∇ E = ∑ x g ′( w ⋅ x ) ( y n − t n )
n n
n =1](https://image.slidesharecdn.com/rnaula1-120812131145-phpapp01/85/Redes-Neurais-classificacao-e-regressao-7-320.jpg)



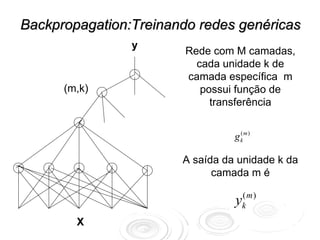
![Exemplo 2:
Regressão não-linear em 1 dimensão
y
y = ∑ w(2) tanh( w(1) x)
j j
j
Exemplos gerados por :
tn = sen(2π xn ) + ruido
Função Erro dada por:
x 1 N
E (w ) = ∑ [ yn (w ) − tn ]2
2 n =1](https://image.slidesharecdn.com/rnaula1-120812131145-phpapp01/85/Redes-Neurais-classificacao-e-regressao-15-320.jpg)
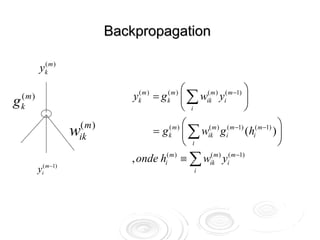

![Backpropagation
Apresenta-se um exemplo
( x, t )
Calculam-se as saídas yk m )
(
Calculam-se os “erros” da δ (M )
k = (t − yk )[ g (M )
k ]′
camada de saída dados por
Propagam-se estes erros para
camadas interiores usando:
δ k( M −1) = (∑ wlkM )δ l( M ) )[ g k( M −1) ]′
(
l](https://image.slidesharecdn.com/rnaula1-120812131145-phpapp01/85/Redes-Neurais-classificacao-e-regressao-19-320.jpg)



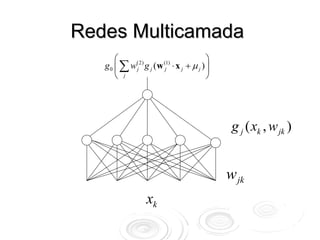
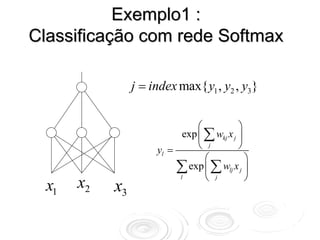
O documento discute redes neurais para classificação e regressão. Brevemente descreve a história das redes neurais, como elas podem ser usadas para classificação e regressão, e aplicações como detecção de fraude e previsão de riscos. Também resume perceptrons, redes multicamadas, e o algoritmo backpropagation para treinamento de redes neurais.













![[Robson] 7. Programação Não Linear Irrestrita](https://cdn.slidesharecdn.com/ss_thumbnails/irrestrita01-120311165949-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Robson] 5. Análise de Sensibilidade](https://cdn.slidesharecdn.com/ss_thumbnails/sensibilidade-120311174016-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

































































