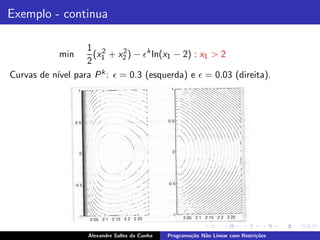
O documento descreve os conceitos fundamentais da programação não linear com restrições, incluindo:
1) Definição do problema de otimização sobre um conjunto convexo com restrições não lineares;
2) Condições de otimalidade para problemas convexos;
3) Noções de pontos estacionários e restrições ativas e inativas.




![Condi¸˜es de Otimalidade
co
Proposi¸˜o
ca
Seja x ∗ um m´
ınimo local de f em um conjunto convexo X . Ent˜o:
a
1 ∇f (x ∗ )′ (x − x ∗ ) ≥ 0, ∀x ∈ X
2 Se f for convexa sobre X , ent˜o a condi¸˜o acima ´ uma condi¸˜o
a ca e ca
suficiente para x ∗ minimizar f em X .
Prova
Parte 1 Suponha ∇f (x ∗ )′ (x − x ∗ ) < 0, para algum x ∈ X . Pelo Teorema
do Valor Central, temos que para todo ǫ > 0, existe s ∈ [0, 1] tal que:
f (x ∗ + ǫ(x − x ∗ )) = f (x ∗ ) + ǫ∇f (x ∗ + sǫ(x − x ∗ ))′ (x − x ∗ )
Pela continuidade de f , temos que para ǫ > 0 suficientemente pequeno,
∇f (x ∗ + sǫ(x − x ∗ ))′ (x − x ∗ ) < 0 e ent˜o f (x ∗ + ǫ(x − x ∗ )) < f (x ∗ ).
a
Como o conjunto X ´ convexo, temos que x ∗ + ǫ(x − x ∗ ) ´ vi´vel para
e e a
todo ǫ ∈ [0, 1] e ent˜o contradizemos a otimalidade de x
a ∗.](https://image.slidesharecdn.com/restrita-01-120327145714-phpapp02/85/Alexandre-8-Nao-Linear-Restrita-5-320.jpg)













![Caracteriza¸˜o da dire¸˜o vi´vel
ca ca a
Conforme j´ mencionamos, no caso onde X ´ convexo, uma dire¸˜o
a e ca
vi´vel d
a k em x k pode ser caracterizada da seguinte maneira:
d k = γ(x k − x k ), γ > 0
onde x k ´ algum ponto vi´vel.
e a
O m´todo opera ent˜o de acordo com a seguinte itera¸˜o:
e a ca
x k+1 = x k + αk d k , α ∈ [0, 1],
onde a dire¸˜o d k al´m de vi´vel, deve ser de descida:
ca e a
∇f (x k )′ (x k − x k ) < 0, x k ∈ X
Observe que pela convexidade de X , x k + αk (x k − x k ) ∈ X para
qualquer α ∈ [0, 1].
Al´m disto, se d k = γ(x k − x k ) ´ uma dire¸˜o de descida e x k ´ n˜o
e e ca e a
estacion´rio, temos a garantia de existir um αk para o qual
a
f (x k+1 ) < f (x k ).](https://image.slidesharecdn.com/restrita-01-120327145714-phpapp02/85/Alexandre-8-Nao-Linear-Restrita-19-320.jpg)

![M´todo de Dire¸˜es vi´veis: determina¸˜o do passo
e co a ca
Minimiza¸˜o exata: αk = arg min
ca α∈[0,1] f (x
k + αd k )
Armijo: Fixados escalares β, σ > 0 tais que β ∈ (0, 1) e σ ∈ (0, 1),
fazemos αk = β mk , onde mk ´ o primeiro inteiro n˜o negativo m tal
e a
que:
f (x k ) − f (x k + β m d k ) ≥ −σβ m ∇f (x k )′ d k
Ou seja, tentamos sucessivamente os passos αk = 1, β, β 2 , . . . at´
e
satisfazer a condi¸˜o acima.
ca](https://image.slidesharecdn.com/restrita-01-120327145714-phpapp02/85/Alexandre-8-Nao-Linear-Restrita-21-320.jpg)







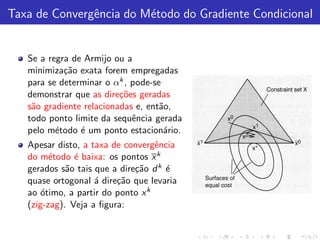

![O problema de projetar z ∈ Rn em X convexo, fechado
Proje¸˜o
ca
Consiste em encontrar um vetor x ∗ ∈ X , cuja distˆncia a z seja m´
a ınima:
minimize z −x
x ∈X
Alguns fatos sobre a proje¸˜o
ca
Para todo z ∈ Rn existe um x ∗ ∈ X unico que minimiza z − x
´
sobre todo x ∈ X . Este vetor ´ chamado proje¸˜o de z em X .
e ca
Usualmente denominamos x ∗ = [z]+ .
Dado z ∈ Rn , x ∗ = [z]+ se e somente se
(z − x ∗ )(x − x ∗ ) ≤ 0, ∀x ∈ X .
No caso de X ser um subespa¸o, x ∗ ∈ X ´ a proje¸˜o de z em X se e
c e ca
somente se z − x ∗ for ortogonal a X , isto ´: (z − x ∗ )x = 0, ∀x ∈ X .
e](https://image.slidesharecdn.com/restrita-01-120327145714-phpapp02/85/Alexandre-8-Nao-Linear-Restrita-31-320.jpg)
![Gradiente projetado
Vamos supor que o nosso problema de otimiza¸˜o seja
ca
minimize f (x)
Ax ≤ b
Ex = e
onde A ∈ Rm×n , E ∈ Rl×n , b ∈ Rm×1 , e ∈ Rl×1 e
X = {x ∈ Rn : Ax ≤ b, Ex = e}.
e que disponhamos de um ponto vi´vel x k na fronteira do conjunto de
a
viabilidade X .
Assuma ent˜o que A1 x k = b1 e A2 x k < b2 , onde A′ = [A′ , A′ ],
a 1 2
b ′ = [b1 , b2 ].
′ ′
Suponha tamb´m que f seja diferenci´vel em x k .
e a
Como fazemos para projetar −∇f (x k ) na face de X ativa em x k ?](https://image.slidesharecdn.com/restrita-01-120327145714-phpapp02/85/Alexandre-8-Nao-Linear-Restrita-32-320.jpg)
![Resolvemos o seguinte Problema de Otimiza¸˜o Quadr´tica
ca a
minimize x − (−∇f (x k ))
A 1 x = b1
A 2 x ≤ b2
Ex = e
cuja solu¸˜o (obtida analiticamente) ´ x ∗ = −P∇f (x k ) onde a matriz P
ca e
(chamada de matriz de proje¸˜o) ´ dada por:
ca e
P = I − M ′ (MM ′ )−1 M
e a matriz M corresponde ˜s linhas das restri¸˜es ativas em x k :
a co
M ′ = [A′ , E ′ ].
1](https://image.slidesharecdn.com/restrita-01-120327145714-phpapp02/85/Alexandre-8-Nao-Linear-Restrita-33-320.jpg)




![Caracteriza¸˜o de Dire¸˜es Vi´veis
ca co a
Proposi¸˜o
ca
Considere o poliedro X = {x ∈ Rn : Ax ≤ b, Ex = e} que definimos.
Suponha que x k ∈ X e que
A1 x k = b1 , A2 x k < b2 , A′ = [A′ , A′ ], b ′ = [b1 , b2 ].
1 2
′ ′
Ent˜o, um vetor d k ´ vi´vel em x k se e somente se A1 d k ≤ 0, Ed k = 0.
a e a
(A demonstra¸˜o ´ ´bvia).
ca e o](https://image.slidesharecdn.com/restrita-01-120327145714-phpapp02/85/Alexandre-8-Nao-Linear-Restrita-38-320.jpg)
![Gradiente projetado - X ´ um poliedro
e
Proposi¸˜o
ca
Considere o problema minx∈X definido acima. Assuma que x k seja um
ponto vi´vel tal que A1 x k = b1 e A2 x k < b2 , onde A′ = [A′ , A′ ],
a 1 2
b ′ = [b1 , b2 ]. Suponha tamb´m, que f seja diferenci´vel em x k . Ent˜o:
′ ′ e a a
1 Se P ´ uma matriz de proje¸˜o tal que P∇f (x k ) = 0, ent˜o
e ca a
d k = −P∇f (x k ) ´ uma dire¸˜o de descida de f em x k .
e ca
2 Al´m disto, se M ′ = [A1 , E ′ ] possui posto completo e se
e ′
P =I −M ′ (MM ′ )−1 M, ent˜o d k ´ uma dire¸˜o de descida, vi´vel.
a e ca a](https://image.slidesharecdn.com/restrita-01-120327145714-phpapp02/85/Alexandre-8-Nao-Linear-Restrita-39-320.jpg)







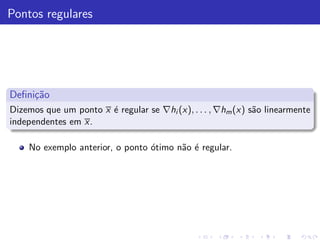





![Obtendo λ∗
Aplicando as CNPO a F k (x k ), temos:
0 = ∇F k (x k ) = ∇f (x k ) + k∇h(x k )h(x k ) + α(x k − x ∗ ) (9)
Pelo enunciado, temos que ∇h(x ∗ ) possui posto completo, igual a
m < n. Por continuidade, existe k suficientemente grande para o qual
o posto de ∇h(x k ) tamb´m ´ m. Logo [∇h(x k )′ ∇h(x k )]−1 ´ n˜o
e e e a
singular.
Pre multiplique (9) por [∇h(x k )′ ∇h(x k )]−1 e obtenha:
kh(x k ) = −[∇h(x k )′ ∇h(x k )]−1 ∇h(x k )′ ∇f (x k ) + α(x k − x ∗ )
Sabemos que k → ∞, x k → x ∗ e kh(x k ) converge para um valor
finito. Denonine ent˜o por
a
λ∗ = [∇h(x ∗ )′ ∇h(x ∗ )]−1 ∇h(x ∗ )′ ∇f (x ∗ )
Tome o limite em (9) quando k → ∞ e obtenha:
∇f (x ∗ ) + ∇h(x ∗ )λ∗ = 0](https://image.slidesharecdn.com/restrita-01-120327145714-phpapp02/85/Alexandre-8-Nao-Linear-Restrita-53-320.jpg)
![Vamos agora provar as condi¸˜es de 2a. ordem
co
Aplicando as CNSO a F k (x k ) temos (diferenciando (9)) que a matriz:
m
2 2
k k k k
∇ F (x ) = ∇ f (x )+ k∇h(x )∇h(x ) + k k ′
hi (x k )∇2 hi (x k )+ αI
i =1
(10)
´ semi-positiva definida, para todo k suficientemente grande e α > 0.
e
Tome qualquer y ∈ V (x ∗ ) isto ´ y : ∇h(x ∗ )′ y = 0 e considere que y k
e
seja a proje¸˜o de y no espa¸o nulo de ∇h(x k )′ , isto ´:
ca c e
(I − P)y = y k = y − ∇h(x k )[∇h(x k )′ ∇h(x k )]−1 ∇h(x k )y
As condi¸˜es necess´rias de primeira ordem garantem que
co a
∇h(x k )′ y k = 0 e como ∇2 F k (x k ) ´ semi-positiva definida, temos:
e
0 ≤ (y k )′ ∇2 F k (x k )y k
k )′ ∇2 f (x k ) + k m k 2 k k k 2
0 ≤ (y i =1 hi (x )∇ hi (x ) y + α y
(11)](https://image.slidesharecdn.com/restrita-01-120327145714-phpapp02/85/Alexandre-8-Nao-Linear-Restrita-54-320.jpg)








































![[Robson] 3. Método Simplex](https://cdn.slidesharecdn.com/ss_thumbnails/simplex-120311172412-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Robson] 7. Programação Não Linear Irrestrita](https://cdn.slidesharecdn.com/ss_thumbnails/irrestrita01-120311165949-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Robson] 1. Programação Linear](https://cdn.slidesharecdn.com/ss_thumbnails/pl-111210174628-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Robson] 6. Otimização de Grande Porte](https://cdn.slidesharecdn.com/ss_thumbnails/column-120310161439-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Alexandre] 2. Geometria](https://cdn.slidesharecdn.com/ss_thumbnails/geometria-120327135217-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Robson] 5. Análise de Sensibilidade](https://cdn.slidesharecdn.com/ss_thumbnails/sensibilidade-120311174016-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Robson] 4. Dualidade](https://cdn.slidesharecdn.com/ss_thumbnails/dualidade-120311163806-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































