Transferir como PDF, PPTX



![Previsão: aproximação
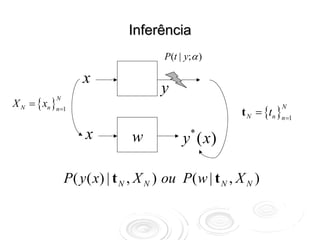
xN +1 ∉ X N w ±δ w
*
y ( xN +1 ) ± δ y
*
P(t N | w, X N ) P( w)
P( w | t N , X N ) =
P (t N | X N )
E ( w) = − ln [ P(t N | w, X N ) P( w) ]
w* = arg min E ( w)
⎡ 1 ∂2E ⎤
wamostrado de P(w*| tN , XN )exp ⎢− ∑(wj − wj *) (wk − wk *)⎥
⎢ 2 jk
⎣ ∂wj∂wk ⎥
⎦](https://image.slidesharecdn.com/rnaula4-120812131512-phpapp02/85/Redes-Neurais-Processos-Gaussianos-4-320.jpg)
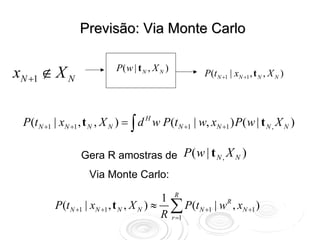
![Métodos Não-Paramétricos
P [ t N | y ( x), X N ] P [ y ( x) ]
P [ y ( x) | t N , X N ] =
P (t N | X N )
Probabilidade no espaço de
funções
P [ y ( x) ]](https://image.slidesharecdn.com/rnaula4-120812131512-phpapp02/85/Redes-Neurais-Processos-Gaussianos-6-320.jpg)
![Gaussian Process (GP)
P [ y ( x) ] é uma gaussiana
1 ⎧ 1 −1 ⎫
P ( x) = exp ⎨− x ⋅ C x ⎬
2π C ⎩ 2 ⎭
Produto escalar
funcional
1 ⎧ 1 ⎫
P[ y ] = exp ⎨− y A y ⎬
Z ⎩ 2 ⎭
Operador Linear](https://image.slidesharecdn.com/rnaula4-120812131512-phpapp02/85/Redes-Neurais-Processos-Gaussianos-7-320.jpg)

![Splines e GPs
Regressão utilizando splines.
Encontrar uma função que minimize o funcional abaixo:
2
1 N
1 ⎡ d y( x) ⎤
p
E[ y ] = − β ∑ [ y(x ) − tn ] − α ∫ dx ⎢
2
dx p ⎥
n
2 n =1 2 ⎣ ⎦
AJUSTE AOS DADOS REGULARIDADE
ln P [ y | t N , X N , β , α ]
ln P [ y | α ]
ln P [ t N | y, X N , β ]](https://image.slidesharecdn.com/rnaula4-120812131512-phpapp02/85/Redes-Neurais-Processos-Gaussianos-9-320.jpg)
![Splines e GPs
α
∫ dx ⎡ D
2
ln P [ y | α ] = − ⎣
p
y ( x) ⎤
⎦
2
α
=−
2 ∫ dx D p y ( x) D p y ( x)
1 † ⎡ 1 p ⎤† 1 p
= − y α 2D α 2D y
2 ⎣ ⎦
A ( x , x′ )
1 ⎡ 1 ⎤
P[ y | μ , α ] = exp ⎢ − y − μ A y − μ ⎥
Z ⎣ 2 ⎦
com μ ( x) = 0](https://image.slidesharecdn.com/rnaula4-120812131512-phpapp02/85/Redes-Neurais-Processos-Gaussianos-10-320.jpg)
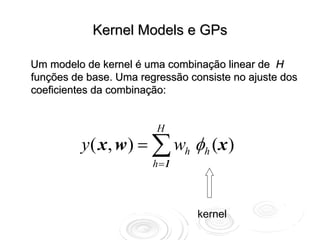


![Kernel Models
{ xn }n=1
N
Para qualquer conjunto de N vetores
P( w ) gaussiana implica em
P ( y ( x1 ), , y ( x N )) gaussiana
P[ y ] é um processo gaussiano](https://image.slidesharecdn.com/rnaula4-120812131512-phpapp02/85/Redes-Neurais-Processos-Gaussianos-14-320.jpg)


![Redes Neurais Multicamada e GPs
Uma rede neural com uma camada escondida e saída linear
representa a seguinte família de funções:
H
⎛ I ( 1) ( 1) ⎞
y ( x; w ) = ∑ wh tanh ⎜ ∑ whi xi + wh 0 ⎟ + w02 )
(2) (
h=1 ⎝ i =1 ⎠
Se uma distribuição a priori gaussiana para os parâmetros w é
assumida, P[y] tende para um processo gaussiano conforme
H →∞
(R. Neal, Priors for Infinite Networks)](https://image.slidesharecdn.com/rnaula4-120812131512-phpapp02/85/Redes-Neurais-Processos-Gaussianos-17-320.jpg)


[1] Processos Gaussianos são métodos não-paramétricos para inferência e previsão que modelam a distribuição de probabilidade sobre funções. [2] Kernel models e redes neurais multicamadas podem ser vistos como aproximações de processos gaussianos quando o número de parâmetros tende ao infinito. [3] Processos gaussianos permitem fazer previsões de novas observações de forma probabilística.
















![[Robson] 7. Programação Não Linear Irrestrita](https://cdn.slidesharecdn.com/ss_thumbnails/irrestrita01-120311165949-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Robson] 1. Programação Linear](https://cdn.slidesharecdn.com/ss_thumbnails/pl-111210174628-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Robson] 3. Método Simplex](https://cdn.slidesharecdn.com/ss_thumbnails/simplex-120311172412-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Robson] 5. Análise de Sensibilidade](https://cdn.slidesharecdn.com/ss_thumbnails/sensibilidade-120311174016-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















































