Baixado 402 vezes




![Matlab
Matlab (M a t r i x L a b o r a t o r y ) é uma linguagem para computação científica com estrutura
otimizada para a realização de operações com matrizes. O ambiente Matlab é composto
por uma série de funções pré-definidas para cálculo, leitura e escrita de arquivos e
visualização. Este conjunto de funções pode ser facilmente extendido por t o o l b o x e s
dedicadas. Há t o o l b o x e s para finanças, tratamento de sinais, econometria e redes neurais.
Para ilustrar a forma como matrizes podem ser tratadas pelo Matlab utilizamos o
quadrado mágico de Dührer que é utilizado como exemplo no G e t S t a r t que acompanha
o software. Na linha de comando do Matlab entramos:
> A = [16 3 2 13; 5 10 11 8; 9 6 7 12; 4 15 14 1]
A=
16 3 2 13
5 10 11 8
9 6 7 12
4 15 14 1
Após este comando a matriz A fica armazenada no W o r k s p a c e do Matlab conforme
ilustrado abaixo.
Criado por Renato Vicente 4 27/01/06](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-4-320.jpg)


![O Matlab possui uma função específica para a criação de quadrados mágicos de qualquer
dimensão, esta função é
> B=magic(4)
B=
16 2 3 13
5 11 10 8
9 7 6 12
4 14 15 1
É possível reordenar as colunas de B para reobtermos A utilizando o comando
> B(:,[1 3 2 4])
ans =
16 3 2 13
5 10 11 8
9 6 7 12
4 15 14 1
Netlab
O Netlab é uma t o o l b o x para Redes Neurais para Matlab disponibilizada gratuitamente
no site do Neural Computing Research Group da Univerisdade de Aston
(www.ncrg.aston.ac.uk). Esta t o o l b o x toran a implementação de modelos baseados em
Redes Neurais muito simples. Os códigos produzidos em Matlab podem então ser
convertidos em executáveis utilizando o M a t l a b C o m p i l e r . Como um primeiro contato
com o Netlab escreveremos sua versão para o clássico "H e l l o W o r l d ".
Começamos por gerar de um conjunto de dados fictícios para treinamento de nossa
Rede Neural. Para isso vamos supor que a função que queremos inferir é
f ( x) = sin (2π x ) . No entanto, só temos acesso a uma versão corrompida por ruído
gaussiando desta função assim, nosso conjunto de dados é "gerado" da seguinte forma:
tn = sin(2π xn ) + σε n
,
ε n ~ N (0,1)
onde N(0,1) é uma distribuição normal com média nula e variância unitária.
No Matlab teremos
1 x=[0:1/19:1]';
2 ndata=size(x,1);
3 t=sin(2*pi*x) + 0.15*randn(ndata,1);
Criado por Renato Vicente 7 27/01/06](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-7-320.jpg)
![unidades na camada escondida seja adequada. No Netlab podemos definir uma
arquitetura de rede em uma única linha de comando.
4 net=mlp (1, 3, 1, 'linear')
net =
type: 'mlp'
nin: 1
nhidden: 3
nout: 1
nwts: 10
actfn: 'linear'
w1: [-1.6823 -0.5927 0.1820]
b1: [-0.1300 -0.1185 -0.0827]
w2: [3x1 double]
b2: 0.2541
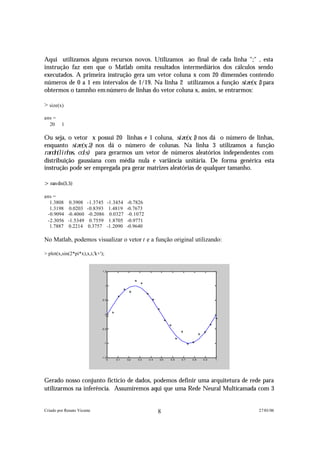
A função m l p do Netlab cria uma estrutura que especifica completamente a arquitetura
e os parâmetros iniciais da Rede Neural. Assim a rede possui n i n = 1 entrada, n h i d d e n = 3
unidades na camada interna, n o u t = 1 saída e n w t s = 1 0 parâmetros entre pesos sinápticos e
limiares. Os parâmetros são iniciados em valores aleatórios. Graficamente teremos:
Cada unidade possui uma entrada extra denotada por uma seta que regula o l i m i a r d e
d i s p a r o de cada um dos neurônios. Cada neurônio da camada escondida gerado pela
função m l p implementa uma f u n ç ã o d e t r a n s f e r ê n c i a s i g m o i d a l do tipo tanh(b + ∑ w j x j ) .
j
Já o neurônio da camada de saída implementa a função de transferência especificada na
função m l p , no caso, uma função linear. Assim, a arquitetura da Rede Neural que
utilizaremos representa a seguinte família de funções:
3
y( x, w, b ) = b2 + ∑ w2 l tanh(b1l + w1l x) .
l =1
O terceiro passo consiste no treinamento desta rede utilizando os dados fictícios
contidos no conjunto de treinamento. Para isso o Netlab utiliza a infra-estrutura de
algoritmos de otimização do Matlab. Primeiro é necessário armazenar as configurações
padrão dos otimizadores do Matlab:
Criado por Renato Vicente 9 27/01/06](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-9-320.jpg)
![5 options=foptions;
A seguir personalizamos algumas destas opções:
6 options(1) = 0;
Este comando evita que os algoritmos de otimização exibam na tela a evolução passo a
passo da função custo sendo minimizada.
7 options(14) =100;
Esta instrução limita em 100 passos os ciclos de otimização. Agora podemos treinar nossa
rede utilizando a função n e t o p t do Netlab:
8 [net, options] = netopt(net, options, x, t, 'scg');
Warning: Maximum number of iterations has been exceeded
A função n e t o p t otimiza os parâmetros da rede definida pela estrutura n e t , utilizando as
opções de otimizador defindas em o p t i o n s e utilizando os dados de entrada contidos no
vetor x e de saída contidos no vetor t . O último argumento em n e t o p t especifica o tipo
de algoritmo a ser utilizado na otimização, no exemplo, 's c g ' significa s c a l e d g r a d i e n t . A
função retorna uma mensagem de aviso indicando que a otimização foi terminada devido
ao limite de 100 passos de otimização.
Neste momento já obtivemos no W o r k s p a c e do Matlab uma estrutura n e t com
parâmetros otimizados assim:
> net.w1
ans =
-5.2017 0.8701 1.5318
> net.w2
ans =
2.6033
1.0716
3.4209
> net.b1
ans =
2.4785 -0.6179 -0.3766
> net.b2
ans =
-0.7588
Criado por Renato Vicente 10 27/01/06](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-10-320.jpg)
![O quarto passo consiste em utilizarmos a rede recém treinada. Para isso utilizamos a
função m l p f w d do Netlab, assim se quisermos saber qual seria a saída para a entrada
x = 0 . 5 6 5 , calculamos:
>mlpfwd(net,0.565)
ans =
-0.4632
Para analisarmos visualmente a qualidade de nosso modelo para os dados representamso
em um gráfico previsões para várias entradas e o valor "real":
9 plotvals=[0:0.01:1]';
10 y=mlpfwd(net,plotvals);
11 plot(plotvals, y, 'ob',plotvals,sin(2*pi*plotvals));
1.5
1
0.5
0
-0.5
-1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Na figura acima as previsões aparecem como circunferências e o valor "real" como uma
linha cheia. A qualidade da previsão irá depender da Rede Neural empregada e do nível
de ruído dos dados.
Criado por Renato Vicente 11 27/01/06](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-11-320.jpg)




![Discutiremos quatro técnicas implementadas pelo Netlab:
1. Gradient Descent
2. Gradiente Conjugado
3. Gradiente Conjugado Escalado
4. Quase-Newton
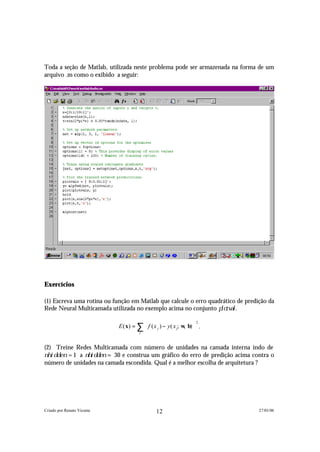
Para exemplificarmos como Netlab pode ser usado para otimizar funções utilizaremos
um de seus programas de demonstração denominado demopt1. O programa demopt1
demonstra a otimização da seguinte função:
y ( x1 , x2 ) = 100( x2 − x12 ) 2 + (1 − x1 ) 2 , (1.21)
conhecida como função de Rosenbrock utilizando quatro técnicas diferentes.
No Matlab podemos visualizar a superfície definida pela função acima com um único
comando:
> ezsurfc ('100*(x1-x2^2)^2+(1-x1)^2',[-2, 2],[-2,2] )
Criado por Renato Vicente 10/06/02
18](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-18-320.jpg)
![Alternativamente, podemos utilizar a seguinte sintaxe menos direta:
1 x1=-2:0.01:2;
2 x2=-2:0.01:2;
3 [sx1, sx2] =meshgrid (x1,x2);
As instruções acima geram matrizes que contém o produto cartesiano dos vetores x1 e
x2, assim se digitarmos
> [sx1(10,23) sx2(10,23)]
ans =
-1.7800 -1.9100
Veremos um par específico de valores.
A função de Rosenbrock pode ser calculada de duas formas:
> Y= 100*(sx1-sx2.^2).^2 +(1-sx1).^2;
> size(Y)
ans =
401 401
onde utilizamos ".^ " com um ponto antes da operação para elevarmos cada componente
das matrizes X1 e X2, sem "." teríamos calculado um produto matricial. Note que a
resposta é uma discretização da superfície com 401 por 401 pontos.
Para exemplificar o cálculo com e sem ".":
>A=[0 1; 1 0]
A=
0 1
1 0
Um produto matricial será:
> A^2
ans =
1 0
0 1
ou
> A*A
ans =
1 0
0 1
Criado por Renato Vicente 10/06/02
19](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-19-320.jpg)
![Componente a componente teremos
> A.^2
ans =
0 1
1 0
Uma outra forma de avaliarmos a função de Rosenbrock é utilizarmos diretamente a
função do Netlab chamada rosen:
> Y1=rosen([sx1(:),sx2(:)]);
Esta operação retorna um vetor com 401 x 401 valores:
> size(Y1)
ans =
160801 1
Este vetor pode então ser convertido em uma matrz com as dimensões apropriadas
utilizando:
> Y1=reshape(Y1,length(x1),length(x2));
Esta instrução converte um vetor em uma matriz com o número de linhas igual ao
número de dimensões do vetor x1 (length(x1)) e o número de colunas igual ao número
de dimensões do vetor x2 (length(x2)). A matriz é preenchida coluna a coluna conforme o
exemplo a seguir:
>A=[1 2 3 4 5 6 7 8 9 10 11 12];
>A=reshape(A,4,3)
A=
1 5 9
2 6 10
3 7 11
4 8 12
Para plotarmos a superfície podemos utilizar a seguinte instrução :
>surf(x1,x2,Y)
Podemos também plotar curvas de nível da superfície:
> l=-1:6;
>v=2.^l;
>contour(x1,x2,Y,v)
Criado por Renato Vicente 10/06/02
20](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-20-320.jpg)
![Os mínimos da função são (-1,1) e (1,-1).
As funções de otimização do Netlab utilizam a seguinte sintaxe:
> [x, options, errlog, pointlog] = nome ('function', x, options, 'grad');
São quatro as funções de otimização: quasinew (Quase-Newton), conjgrad (gradiente
conjugado), scg (gradiente conjugado escalado) e graddesc (Gradient Descent). Os
argumentos das funções são, respectivamente: a função que se quer otimizar 'function', o
ponto inicial x, o vetor de opções de otimização options e o gradiente da função que se
quer otimizar 'grad'.
As saídas destas funções são, respectivamente: o resultado da otimização x, o vetor de
opcções de otimização atualizado após o processo options, os valores de erro após cada
ciclo errlog e a trajetória percorrida no espaço dos parâmetros pointlog.
O vetor options contém parâmetros para operação da rotina de otimização e parâmetros
específicos para cada algoritmo:
options(1) : 1 para mostrar na tela os valores de erro, 0 para exibir apenas mensagens de
aviso e -1 para não exibir nada;
options(2): Valor da precisão absoluta requerida para encerrar o processo de otimização.
Se xt +1 − xt < options (2) então esta condição é satisfeita.
options(3): Valor da precisão requerida na função otimizada. Se
function(xt +1 ) − function(xt ) < options(3) então a condição é satisfeita. Se esta e a
condição acima forem satisfeitas a otimização é encerrada.
Criado por Renato Vicente 10/06/02
21](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-21-320.jpg)


![>ezsurfc ('10*x1^2+x2',[-1, 1],[0,10] )
O gradiente da função acima é ∇E = (10 x1 ,1) , assim, se iniciarmos a otimização fora do
eixo x1 = 0 teremos fortes oscilações em decorrência da grande curvatura de uma das
direções:
O termo de momento neste caso adicionará uma certa inércia à direção (0,1)
aumentando a taxa de convergência.
Uma outra forma de reduzirmos o número de passos necessários para convergência é a
redução do número de dimensões do problema apenas à direção do gradiente pela
introdução de um algoritmo de otimização unidimensional a cada passo de otimização.
Criado por Renato Vicente 10/06/02
24](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-24-320.jpg)
![Nesta variante a cada passo encontramos a amplitude do deslocamento na direção do
gradiente , assim:
w t +1 = w t − λ *∇E (w t ) , (1.34)
onde λ * é definido como o mínimo de:
E (λ ) = E (w t − λ∇E ( w t )) . (1.35)
De forma equivalente, escolhemos λ de forma a termos:
dE (λ )
= −∇E (w t +1 ) ⋅∇E (w t ) = 0 , (1.36)
dλ
ou seja, gradientes sucessivos ortogonais. A minimização unidimensional em (1.35) pode
ser realizada utilizando uma busca linear. Utilizando esta forma é possível aumentar
consideravelmente a velocidade de convergência do gradient descent. O incoveniente deste
algoritmo está na condição (1.36) que força movimentos em zig-zag no espaço de
parâmetros.
Neste ponto, vale a pena discutirmos um pouco algoritmos de busca linear. O Netlab
utiliza um algoritmo proposto por Brent1 bastante eficiente e robusto que não utiliza o
gradiente unidimensional da função na otimização . O algoritmo de Brent consiste em:
1. Encontrar 3 pontos a<b<c, tais que E(b)<E(a) e E(b)<E(a) .
2. Ajustar uma parábola passando pelos pontos a,b e c.
3. Minimizando a parábola para encontrar d.
4. Repetindo o processo para pontos d e escolhendo entre a,b,c os dois com menor
erro.
Em Netlab uma busca linear é implementada pela função a seguir:
> [x, options] = linemin(f, pt, dir, fpt, options);
Onde f é a função a ser minimizada, pt é o ponto inicial, dir é a direção que define a
linha de busca, fpt é o valor da função no ponto de início e options é o vetor de opções de
otimização. O ponto de mínimo é dado por pt+x.*dir.
Como exemplo apresentamos a seguir otimização da função de Rosenbrock empregando
Gradient Descent seguirá os seguintes passos:
1 options = foptions;
Para importar configurações padrão para o otimizador.
1
Brent, R. 1973, Algorithms for Minimization without Derivatives. Englewood Cliffs, NJ: Prentice-Hall.
Criado por Renato Vicente 10/06/02
25](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-25-320.jpg)
![2 options(1) = -1;
3 options(3) = 1e-8;
4 options(7)=1;
5 options(14) = 100;
Nada é exibido na tela , a precisão requerida para as variações na função otimizada é de 10-
8
, a otimização empregará a variante com busca linear e o número total de iterações é
fixado em 100. O vetor options inicia o processo na seguinte configuração:
>options(1)
ans =
-1
>options(2)
ans =
1.0000e-004
>options(3)
ans =
1.0000e-008
>options(9)
ans =
0
>options(10)
ans =
0
>options(11)
ans =
0
>options(14)
ans =
100
Assim a otimização deve encerrar quando as precisões fixadas forem atingidas ou quando o
número de iterações chegar a 100. Para vermos todas as outras opções disponíveis basta
utilizarmos o comando:
> help graddesc
GRADDESC Gradient descent optimization.
Description
[X, OPTIONS, FLOG, POINTLOG] = GRADDESC(F, X, OPTIONS, GRADF) uses
batch gradient descent to find a local minimum of the function F(X)
whose gradient is given by GRADF(X). A log of the function values
after each cycle is (optionally) returned in ERRLOG, and a log of the
points visited is (optionally) returned in POINTLOG.
Note that X is a row vector and F returns a scalar value. The point
at which F has a local minimum is returned as X. The function value
at that point is returned in OPTIONS(8).
GRADDESC(F, X, OPTIONS, GRADF, P1, P2, ...) allows additional
Criado por Renato Vicente 10/06/02
26](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-26-320.jpg)
![arguments to be passed to F() and GRADF().
The optional parameters have the following interpretations.
OPTIONS(1) is set to 1 to display error values; also logs error
values in the return argument ERRLOG, and the points visited in the
return argument POINTSLOG. If OPTIONS(1) is set to 0, then only
warning messages are displayed. If OPTIONS(1) is -1, then nothing is
displayed.
OPTIONS(2) is the absolute precision required for the value of X at
the solution. If the absolute difference between the values of X
between two successive steps is less than OPTIONS(2), then this
condition is satisfied.
OPTIONS(3) is a measure of the precision required of the objective
function at the solution. If the absolute difference between the
objective function values between two successive steps is less than
OPTIONS(3), then this condition is satisfied. Both this and the
previous condition must be satisfied for termination.
OPTIONS(7) determines the line minimisation method used. If it is
set to 1 then a line minimiser is used (in the direction of the
negative gradient). If it is 0 (the default), then each parameter
update is a fixed multiple (the learning rate) of the negative
gradient added to a fixed multiple (the momentum) of the previous
parameter update.
OPTIONS(9) should be set to 1 to check the user defined gradient
function GRADF with GRADCHEK. This is carried out at the initial
parameter vector X.
OPTIONS(10) returns the total number of function evaluations
(including those in any line searches).
OPTIONS(11) returns the total number of gradient evaluations.
OPTIONS(14) is the maximum number of iterations; default 100.
OPTIONS(15) is the precision in parameter space of the line search;
default FOPTIONS(2).
OPTIONS(17) is the momentum; default 0.5. It should be scaled by the
inverse of the number of data points.
OPTIONS(18) is the learning rate; default 0.01. It should be scaled
by the inverse of the number of data points.
See also
CONJGRAD, LINEMIN, OLGD, MINBRACK, QUASINEW, SCG
Definimos o ponto inicial como:
5 x = [-2,3];
Criado por Renato Vicente 10/06/02
27](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-27-320.jpg)
![A otimização propriamente dita pode ser implementada em uma linha :
6 [x,options,errgd,trajgd]=graddesc('rosen',x,options,'rosegrad');
O resultado final da otimização está longe do valor correto:
>x
x=
-0.5424 0.2886
A figura a seguir ilustra a trajetória percorrida durante o processo de otimização:
>a = -1.5:.02:1.5;
>b = -0.5:.02:2.1;
>[A, B] = meshgrid(a, b);
> Z = rosen([A(:), B(:)]);
> Z = reshape(Z, length(b), length(a));
> l = -10:6;
> v=2.^l;
> contour(a, b, Z, v);
> hold on;
> plot(trajgd(:,1), trajgd(:,2), 'b-', 'MarkerSize', 6)
> title('Gradient Descent')
Exercícios
(1) Repita a otimização acima para o gradient descent sem termo de momento com
os seguites valores para learning rate η = 0.001,0.01, 0.5 . Construa o gráfico
acima em cada um dos casos. Repita os experimentos adicionando momentos
µ = 0.1, 0.5 .
Criado por Renato Vicente 10/06/02
28](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-28-320.jpg)




![4. Calcule w 2 = w1 + α1d1 ;
5. Pare se os critérios de convergência foram satisfeitos
6. Calcule ∇E (w 2 ) ;
7. A nova direção é dada por d 2 = −∇E (w 2 ) + β1d1 , com β1 definido pela relação de
Polak-Ribiere.
8. Vá para o passo 3 para o novo d.
Utilizemos agora a implementação em Netlab do algoritmo de gradiente conjugado para
otimizarmos novamente a função de Rosenbrock. Começamos por verificar as opções
de otimização disponíveis para a função conjgrad:
> help conjgrad
CONJGRAD Conjugate gradients optimization.
Description
[X, OPTIONS, FLOG, POINTLOG] = CONJGRAD(F, X, OPTIONS, GRADF) uses a
conjugate gradients algorithm to find the minimum of the function
F(X) whose gradient is given by GRADF(X). Here X is a row vector and
F returns a scalar value. The point at which F has a local minimum
is returned as X. The function value at that point is returned in
OPTIONS(8). A log of the function values after each cycle is
(optionally) returned in FLOG, and a log of the points visited is
(optionally) returned in POINTLOG.
CONJGRAD(F, X, OPTIONS, GRADF, P1, P2, ...) allows additional
arguments to be passed to F() and GRADF().
The optional parameters have the following interpretations.
OPTIONS(1) is set to 1 to display error values; also logs error
values in the return argument ERRLOG, and the points visited in the
return argument POINTSLOG. If OPTIONS(1) is set to 0, then only
warning messages are displayed. If OPTIONS(1) is -1, then nothing is
displayed.
OPTIONS(2) is a measure of the absolute precision required for the
value of X at the solution. If the absolute difference between the
values of X between two successive steps is less than OPTIONS(2),
then this condition is satisfied.
OPTIONS(3) is a measure of the precision required of the objective
function at the solution. If the absolute difference between the
objective function values between two successive steps is less than
OPTIONS(3), then this condition is satisfied. Both this and the
previous condition must be satisfied for termination.
OPTIONS(9) is set to 1 to check the user defined gradient function.
OPTIONS(10) returns the total number of function evaluations
(including those in any line searches).
Criado por Renato Vicente 23/06/02
32](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-33-320.jpg)
![OPTIONS(11) returns the total number of gradient evaluations.
OPTIONS(14) is the maximum number of iterations; default 100.
OPTIONS(15) is the precision in parameter space of the line search;
default 1E-4.
See also
GRADDESC, LINEMIN, MINBRACK, QUASINEW, SCG
Primeiro inicializamos as opções de otimização carregando as opções de default com:
> options=foptions
options =
Columns 1 through 8
0 0.0001 0.0001 0.0000 0 0 0 0
Columns 9 through 16
0 0 0 0 0 0 0 0.0000
Columns 17 through 18
0.1000 0
Ajustamos então algumas destas opções:
>options(1)=-1;
Para não mostrarmos em tela a trajetória de otimização.
>options(3)=1e-8;
Se em dois passos consecutivos a função erro diferir em menos de 1e-8 e se o vetor de
parâmetros diferir em menos de 1e-2 (options(2) ) a otimização deverá ser encerrada.
>options(14)=100;
A otimização deverá parar se o número de iterações atingir 100.
Agora definimos o ponto inicial :
> x=[-2 3];
A otimização é realizada em uma única linha:
> [x,options,errgd,trajgd]=conjgrad('rosen',x,options,'rosegrad');
As saídas são
>x
x=
1.0000 1.0000
O ponto ótimo, que neste caso está correto !
>options
options =
Columns 1 through 8
-1.0000 0.0001 0.0000 0.0000 0 0 0 0.0000
Columns 9 through 16
0 526.0000 28.0000 0 0 100.0000 0 0.0000
Columns 17 through 18
0.1000 0
Criado por Renato Vicente 23/06/02
33](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-34-320.jpg)

![O Netlab oferece uma função que possibilita a verificação de um gradiente:
>gradchek([-2,3], 'rosen', 'rosegrad');
Checking gradient ...
analytic diffs delta
-806.0000 -806.0000 0.0000
-200.0000 -200.0000 0.0000
Na saída analytic fornece o valor calculado pela função rosegrad , diffs calcula o gradiente
numericamente utilizando a função rosen e delta mostra a diferença entre as duas formas de
cálculo.
Para visualizarmos a trajetória de otimização repetimos o procedimento utilizado quando
discutimos gradient descent:
>a=-1.5:.02:1.5;
>b=-0.5:.02:2.1;
> [A,B]=meshgrid(a,b);
>Z=rosen([A(:),B(:)]);
>Z=reshape(Z,length(b),length(a));
Criado por Renato Vicente 23/06/02
36](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-37-320.jpg)

![2. Se 0, 25 < ∆ j < 0, 75 então γ j +1 = γ j ;
3. Se ∆ j < 0, 25 então γ j +1 = 4γ j ;
4. Se ∆ j < 0 então γ j +1 = 4γ j e o passo de otimização não é efetuado;
O algoritmo de gradientes conjugados escalados adquire então a seguinte forma:
1. Escolha um ponto inicial no espaço dos parâmetros w1 ;
2. Inicialize o parâmetro de escala em γ 1 = 1 ;
3. Calcule o gradiente no ponto inicial e faça a primeira direção de otimização ser
d1 = −∇E (w1 ) ;
4. Para descobrir a amplitude do passo na direção d1 utilize (2.28) e (2.29);
5. Calcule w 2 = w1 + α1d1 ;
6. Pare se os critérios de convergência foram satisfeitos;
7. Calcule o parâmetro de comparação ∆ ;
8. Atualize o parâmetro de escala γ de acordo com as condições acima;
9. Calcule ∇E (w 2 ) ;
10. A nova direção é dada por d 2 = −∇E (w 2 ) + β1d1 , com β1 definido pela relação de
Polak-Ribiere;
11. Vá para o passo 3 para o novo d e para o novo parâmetro de escala γ .
A utilização do Netlab para otimização com gradientes conjugados escalados segue
exatamente os mesmos passos que utilizamos para gradientes conjugados.
> options = foptions;
> options(1)=-1;
>options(3)=1e-8;
>options(14)=100;
> x=[-2 3];
> [x,options,errgd,trajgd]=scg('rosen',x,options,'rosegrad');
>x
x=
1.0000 0.9999
> options
options =
Columns 1 through 11
-1.0000 0.0001 0.0000 0.0000 0 0 0 0.0000 0 52.0000 78.0000
Columns 12 through 18
0 0 100.0000 0 0.0000 0.1000 0
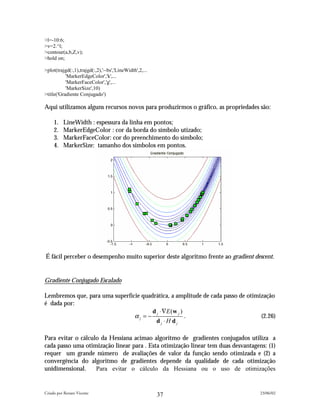
Note que a qualidade do resultado final é ligeiramente inferior àquela obtida com o
gradiente conjugado mas o número de avaliações de função foi reduzido de 526 para 52
ao deixarmos de utilizar otimizações unidimensionais. Para exibirmos a trajetória
Criado por Renato Vicente 23/06/02
39](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-40-320.jpg)


![>help quasinew
QUASINEW Quasi-Newton optimization.
Description
[X, OPTIONS, FLOG, POINTLOG] = QUASINEW(F, X, OPTIONS, GRADF) uses a
quasi-Newton algorithm to find a local minimum of the function F(X)
whose gradient is given by GRADF(X). Here X is a row vector and F
returns a scalar value. The point at which F has a local minimum is
returned as X. The function value at that point is returned in
OPTIONS(8). A log of the function values after each cycle is
(optionally) returned in FLOG, and a log of the points visited is
(optionally) returned in POINTLOG.
QUASINEW(F, X, OPTIONS, GRADF, P1, P2, ...) allows additional
arguments to be passed to F() and GRADF().
The optional parameters have the following interpretations.
OPTIONS(1) is set to 1 to display error values; also logs error
values in the return argument ERRLOG, and the points visited in the
return argument POINTSLOG. If OPTIONS(1) is set to 0, then only
warning messages are displayed. If OPTIONS(1) is -1, then nothing is
displayed.
OPTIONS(2) is a measure of the absolute precision required for the
value of X at the solution. If the absolute difference between the
values of X between two successive steps is less than OPTIONS(2),
then this condition is satisfied.
OPTIONS(3) is a measure of the precision required of the objective
function at the solution. If the absolute difference between the
objective function values between two successive steps is less than
OPTIONS(3), then this condition is satisfied. Both this and the
previous condition must be satisfied for termination.
OPTIONS(9) should be set to 1 to check the user defined gradient
function.
OPTIONS(10) returns the total number of function evaluations
(including those in any line searches).
OPTIONS(11) returns the total number of gradient evaluations.
OPTIONS(14) is the maximum number of iterations; default 100.
OPTIONS(15) is the precision in parameter space of the line search;
default 1E-2.
See also
CONJGRAD, GRADDESC, LINEMIN, MINBRACK, SCG
Criado por Renato Vicente 23/06/02
43](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-44-320.jpg)
![> options = foptions;
> options(1)=-1;
>options(3)=1e-8;
>options(14)=100;
> x=[-2 3];
> [x,options,errgd,trajgd]=quasinew('rosen',x,options,'rosegrad');
>x
x=
1.0000 1.0000
Utilizando o método trajetoria.m :
Criado por Renato Vicente 23/06/02
44](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-45-320.jpg)

![N2 + N
• Completa: A covariância utilizada tem parâmetros , ou seja, Ckl , j = σ kl , j .
2
2
Utilizando demgmm4.
Em Netlab podemos construir um GMM utilizando o comando gmm (dim, comp, covar)
que define uma estrutura com dim dimensões, comp componentes de mistura e
covariância de tipo covar. Se quisermos construir um modelo para a distribuição
conjunta dos retornos das ações descrita acima utilizando 5 componentes com
covariâncias completas, devemos digitar:
> mix= gmm(3,5,'full');
A estrutura definida tem as seguintes componentes:
>mix
mix =
type: 'gmm'
nin: 3
ncentres: 5
covar_type: 'full'
priors: [0.2000 0.2000 0.2000 0.2000 0.2000]
centres: [5x3 double]
covars: [3x3x5 double]
nwts: 65
Os priors são os componentes de mistura e nwts é o número de parâmetros.
A mistura acima precisa ser inicializada, para isso utilizamos o comando gmminit.
Criado por Renato Vicente 23/06/02
48](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-49-320.jpg)
![>help gmminit
GMMINIT Initialises Gaussian mixture model from data
Description
MIX = GMMINIT(MIX, X, OPTIONS) uses a dataset X to initialise the
parameters of a Gaussian mixture model defined by the data structure
MIX. The k-means algorithm is used to determine the centres. The
priors are computed from the proportion of examples belonging to each
cluster. The covariance matrices are calculated as the sample
covariance of the points associated with (i.e. closest to) the
corresponding centres. For a mixture of PPCA model, the PPCA
decomposition is calculated for the points closest to a given centre.
This initialisation can be used as the starting point for training
the model using the EM algorithm.
See also
GMM
>options=foptions;
>mix=gmminit(mix,x,options);
>mix
mix =
type: 'gmm'
nin: 3
ncentres: 5
covar_type: 'full'
priors: [0.0639 0.3083 0.0111 0.4264 0.1903]
centres: [5x3 double]
covars: [3x3x5 double]
nwts: 65
A função gmminit utiliza um algoritmo não-paramétrico denominado K-médias
implementado pela função kmeans do Netlab que consiste dos seguintes passos:
1. Os N dados são são divididos em K grupos S1, S2 e SK com o mesmo número
de componentes;
1
2. São calculadas médias (centros) para cada grupo: µ j = ∑ xn ;
N j n∈S j
3. Calculam-se as distâncias de cada dado em relação a cada um dos centros e
reagrupam-se os dados no grupo de centro mais próximo de forma a
K
minimizar E = ∑ ∑ xn − µ j
2
.
j =1 n∈S j
4. Volta ao passo 2.
Após inicialização o treinamento do GMM é efetuado utilizando um algoritmo de
otimização de verossimilhança denominado EM através da função gmmem.
Criado por Renato Vicente 23/06/02
49](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-50-320.jpg)
![>help gmmem
GMMEM EM algorithm for Gaussian mixture model.
Description
[MIX, OPTIONS, ERRLOG] = GMMEM(MIX, X, OPTIONS) uses the Expectation
Maximization algorithm of Dempster et al. to estimate the parameters
of a Gaussian mixture model defined by a data structure MIX. The
matrix X represents the data whose expectation is maximized, with
each row corresponding to a vector. The optional parameters have
the following interpretations.
OPTIONS(1) is set to 1 to display error values; also logs error
values in the return argument ERRLOG. If OPTIONS(1) is set to 0, then
only warning messages are displayed. If OPTIONS(1) is -1, then
nothing is displayed.
OPTIONS(3) is a measure of the absolute precision required of the
error function at the solution. If the change in log likelihood
between two steps of the EM algorithm is less than this value, then
the function terminates.
OPTIONS(5) is set to 1 if a covariance matrix is reset to its
original value when any of its singular values are too small (less
than MIN_COVAR which has the value eps). With the default value of
0 no action is taken.
OPTIONS(14) is the maximum number of iterations; default 100.
The optional return value OPTIONS contains the final error value
(i.e. data log likelihood) in OPTIONS(8).
See also
GMM, GMMINIT
Note a opção(5) que tem por objetivo evitar que a covariância colapse sobre um ponto,
o que corresponde a um overfitting dos dados modelados.
>options=foptions;
>options(1)=-1;
> [mix,options,errlog] =gmmem(mix,x,options);
> mix
mix =
type: 'gmm'
nin: 3
ncentres: 5
covar_type: 'full'
priors: [0.0063 0.1210 0.2052 0.2196 0.4479]
centres: [5x3 double]
covars: [3x3x5 double]
nwts: 65
Criado por Renato Vicente 23/06/02
50](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-51-320.jpg)
![Os centros são :
> mix.centres
ans =
0.1779 0.1205 0.2443
-0.0056 0.0001 -0.0091
0.0095 0.0246 0.0130
0.0051 -0.0100 -0.0060
-0.0052 -0.0049 -0.0046
Se quisermos agora simular retornos utilizando nosso modelo recém treinado basta
utilizarmos a função [data,label]=gmmsamp(mix,n), com n sendo o número de amostras,
data sendo os dados amostrados e label a componente geradora.
> [simula,label_sim]=gmmsamp(mix,500);
>plot3(simula(:,1),simula(:,2),simula(:,3),'rs','LineWidth',2,'MarkerEdgeColor','k','MarkerFaceColor','g','Mark
erSize',5);
Algoritmo EM (Expectation-Maximization)
A estimação dos parâmetros em um GMM se baseia em um algoritmo conhecido como
EM (Expectation-Maximization) 2. Para encontrarmos os parâmetros mais adequados
para modelar os dados devemos maximizar a função verossimilhança no conjunto de
dados {xn }n =1 :
N
N
L( P, µ , C ) = ∑ ln p ( xn ) , (3.3)
n =1
Esta função de verossimilhança é função dos coeficientes de mistura das médias e das
matrizes de covariância. Para simplificar os cálculos podemos, alternativamente,
minimizar uma função erro definida como:
E = − ln L (3.4)
2
Dempster, A. P., N.M. Laird e D.B. Rubin (1977). Maximum likelihood from incomplete data via the EM
algorithm. journal of the Royal Statistical Society, B 39 (1), 1-38.
Criado por Renato Vicente 23/06/02
51](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-52-320.jpg)


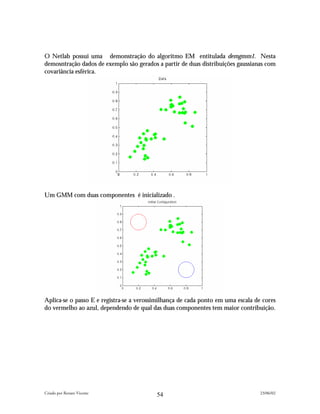
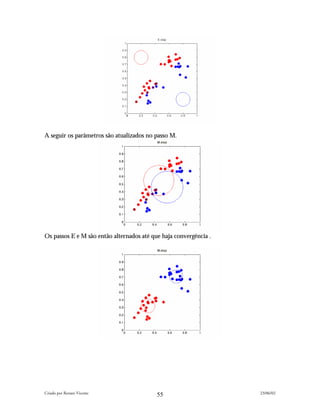



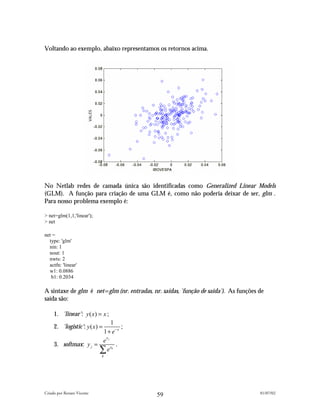
![A função 'logistic' é utilizada nas regressões logísticas comuns em sistemas de aprovação
automática de crédito. Já a função softmax é utilizada em classificações que envolvem
várias classes diferentes (por ex.: rating de crédito).
Dada a estrutura net com parâmetro w, a função erro é avaliada pela função glmerr e o
gradiente pela função glmgrad, em geral é convenção do Netlab representar o erro e o
gradiente da seguinte forma:
<tipo_de_rede>err(net,x,t) , para o erro ;
<tipo_de_rede>grad(net,x,t), para o gradiente.
Desta foram podemos usar sem maiores dificuldades a função genérica para treinamento
de redes. Primeiro carregamos os dados, o arquivo beta.dat contém duas colunas , a
primeira com retornos do Ibovespa e a segunda com retornos vale5 :
>load('beta.dat');
>ibov=beta(:,1);
>vale=beta(:,2);
Então, inicializamos o otimizador e chamamos netopt
> options=foptions;
> [net,options]=netopt(net,options,ibov,vale,'scg');
O resultado é:
>net
net =
type: 'glm'
nin: 1
nout: 1
nwts: 2
actfn: 'linear'
w1: 0.5864
b1: -9.8947e-004
Criado por Renato Vicente 01/07/02
60](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-61-320.jpg)
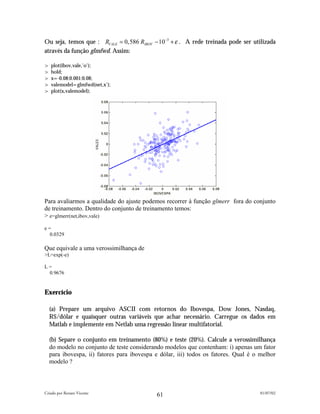







![A arquitetura que escolhemos tem a seguinte representação:
As unidades de saída são lineares e as unidades internas são tanh .
Podemos ver a rede criada digitando:
>net
net =
type: 'mlp'
nin: 12
nhidden: 7
nout: 2
nwts: 107
actfn: 'linear'
w1: [12x7 double]
b1: [-0.1817 0.3313 -0.2486 0.0904 -0.1714 -0.3418 0.3177]
w2: [7x2 double]
b2: [0.1880 0.5289]
Note que o modelo contém 107 parâmetros. Agora inicializamos o vetor de controle
dos algoritmos de otimização:
>options=foptions;
Ajustamos o vetor de controles para que os erros sejam exibidos na tela:
>options(1)=1;
Ajustamos o número máximo de iterações para 500;
>options(14)=500;
Criado por Renato Vicente 05/08/02
69](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-70-320.jpg)
![Agora treinamos a MLP utilizando o Gradiente Conjugado Escalado (scg):
> [net,options,erro] = netopt(net,options,intreino,outtreino,'scg');
…
Cycle 200 Error 0.160426 Scale 1.000000e-015
Cycle 201 Error 0.160335 Scale 1.000000e-015
Cycle 202 Error 0.160068 Scale 1.000000e-015
Cycle 203 Error 0.159740 Scale 1.000000e-015
Cycle 204 Error 0.159441 Scale 1.000000e-015
Cycle 205 Error 0.159200 Scale 1.000000e-015
Cycle 206 Error 0.159114 Scale 1.000000e-015
Cycle 207 Error 0.158751 Scale 1.000000e-015
Cycle 208 Error 0.158675 Scale 1.000000e-015
Cycle 209 Error 0.158466 Scale 1.000000e-015
Cycle 210 Error 0.158082 Scale 1.000000e-015
Cycle 211 Error 0.157837 Scale 1.000000e-015
Cycle 212 Error 0.157532 Scale 1.000000e-015
Cycle 213 Error 0.157437 Scale 1.000000e-015
Cycle 214 Error 0.157029 Scale 1.000000e-015
Cycle 215 Error 0.156953 Scale 1.000000e-015
Cycle 216 Error 0.156921 Scale 1.000000e-015
Agora plotamos a evolução do erro de treinamento com o número de iterações:
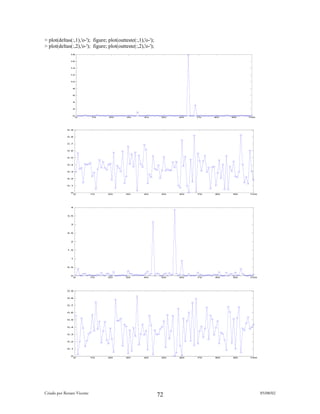
> plot(err,'o-');
Agora utilizamos o modelo treinado armazenado em net para realizar prediçõe no
conjunto de teste:
> outmodel=mlpfwd(net,inteste);
Criado por Renato Vicente 05/08/02
70](https://image.slidesharecdn.com/rncommatlab-120812132525-phpapp02/85/Redes-neurais-com-matlab-71-320.jpg)




Este documento apresenta um resumo de redes neurais para inferência estatística. Ele introduz conceitos básicos de redes neurais, o software Matlab e a toolbox Netlab. O documento descreve como gerar dados de treinamento fictícios, definir a arquitetura de uma rede neural multicamada e treiná-la usando os algoritmos de otimização do Matlab.



































































































