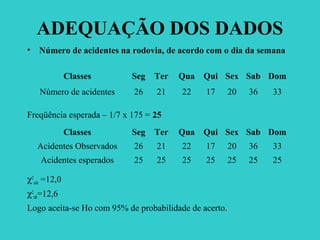
O documento discute testes de hipóteses estatísticas, incluindo: (1) o teste de hipótese avalia inferências sobre uma população com base em uma amostra; (2) a teoria de Popper afirma que não se pode provar nada, apenas refutar hipóteses; (3) os principais conceitos incluem hipótese estatística, teste de hipótese e tipos de hipóteses.