



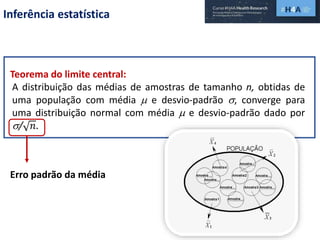







![Região crítica, RC
Região crítica do teste: região de rejeição de H0.
Teste bilateral:
H0: θ = θ0
H1: θ ≠ θ0
RC = ]-∞, c1[ U ]c2, + ∞[
Teste unilateral à esquerda:
H0: θ = θ0
H1: θ < θ0
RC = ]-∞, c[
Teste unilateral à direita:
H0: θ = θ0
H1: θ > θ0
RC = ]c, + ∞[](https://image.slidesharecdn.com/m5h4aapresent-190909221750/85/Curso-H4A-Modulo-5-12-320.jpg)




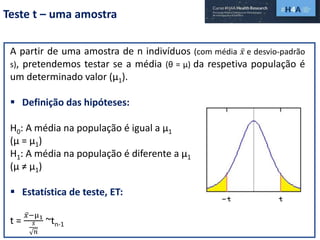










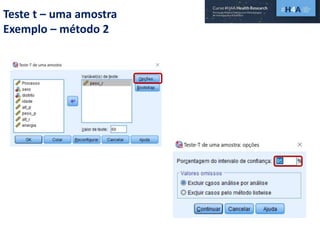







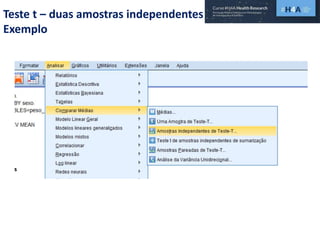
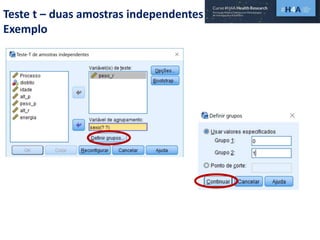


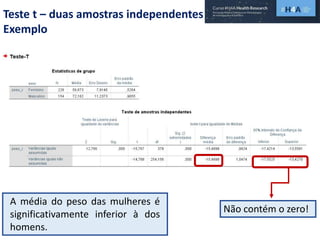



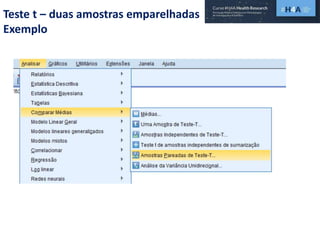
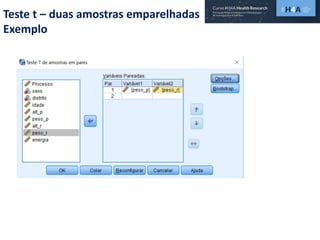
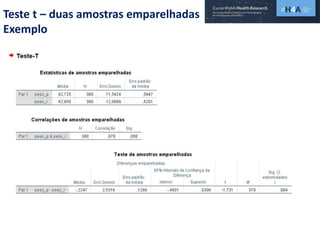
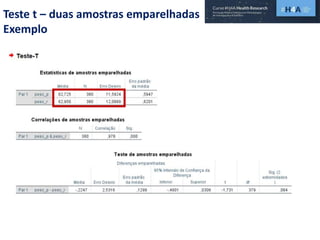
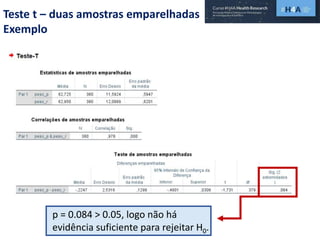
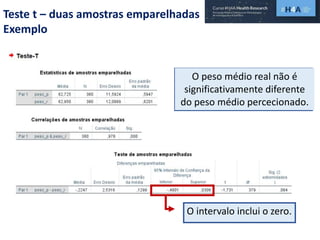

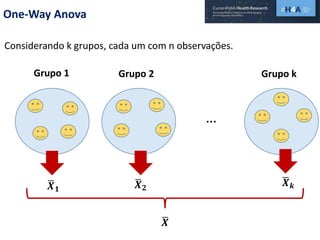
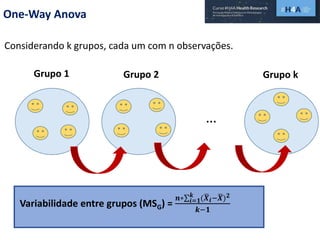
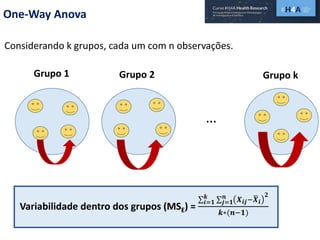


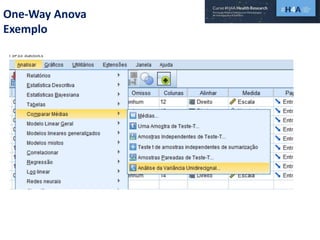
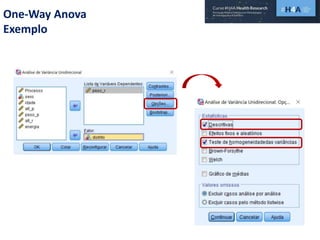
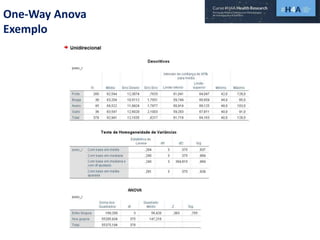
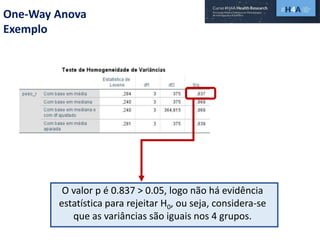
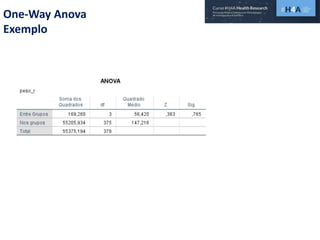



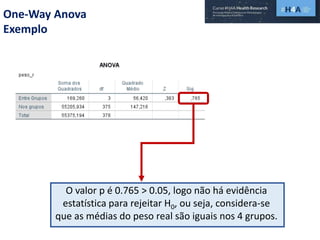










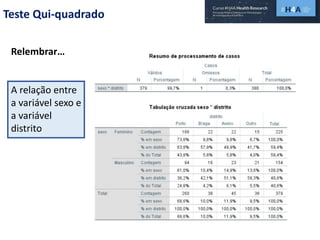
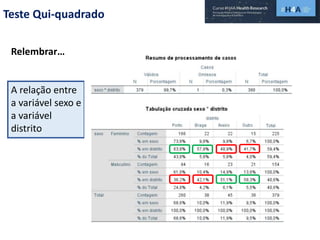


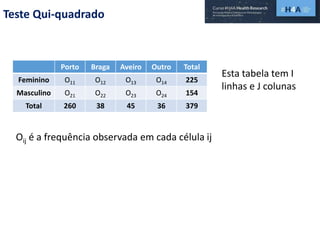
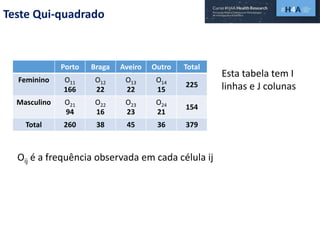
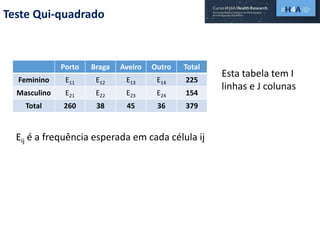
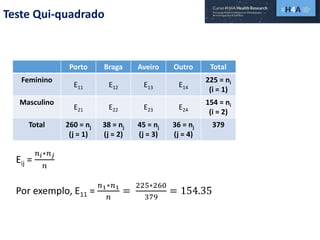
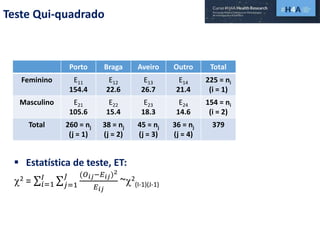

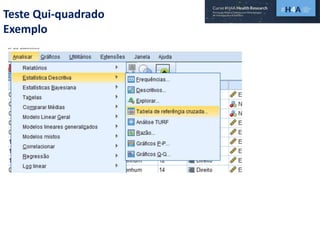
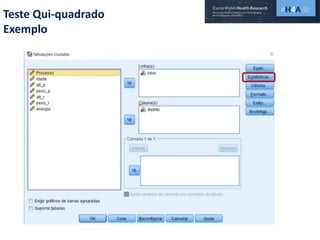
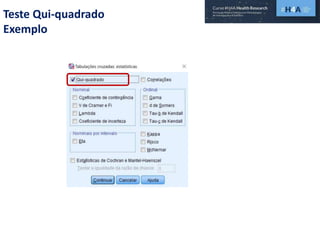
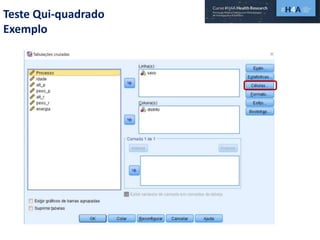
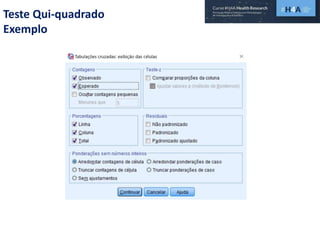
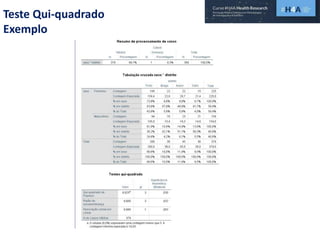




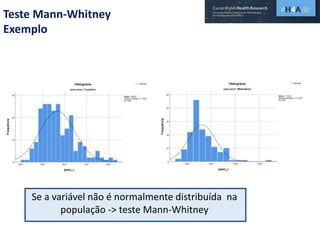

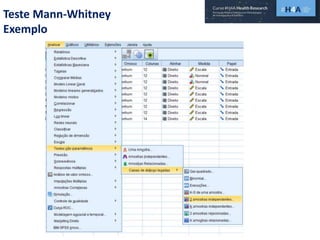
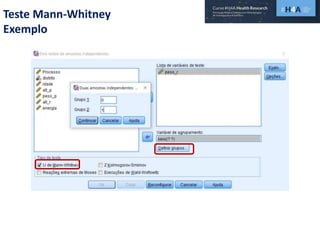


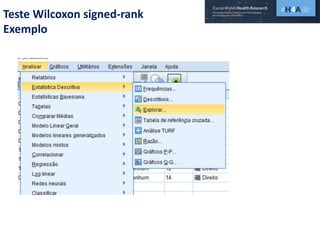
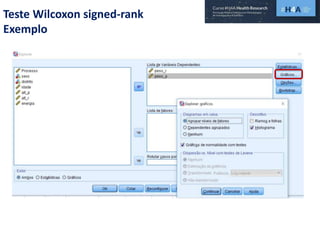
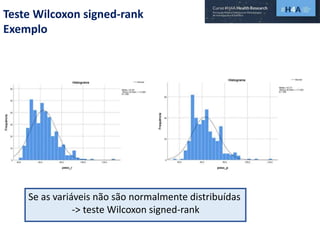





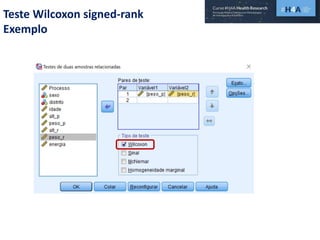


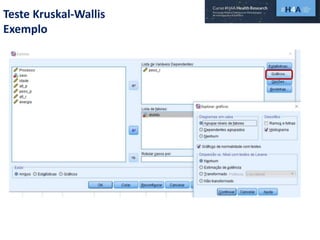
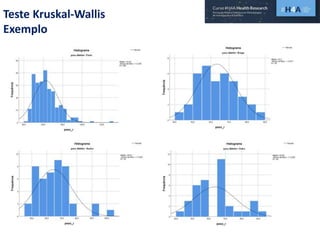

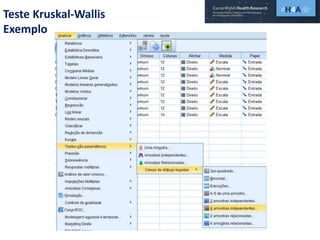
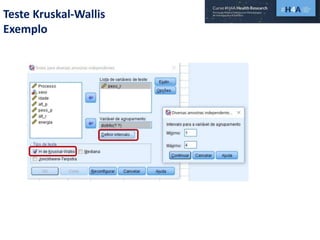
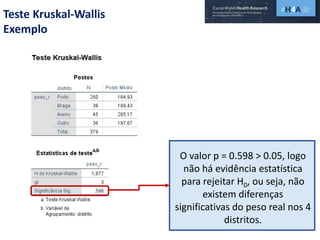
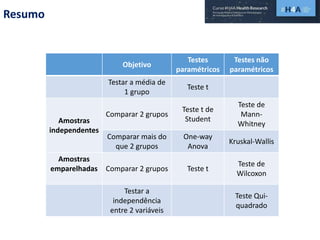




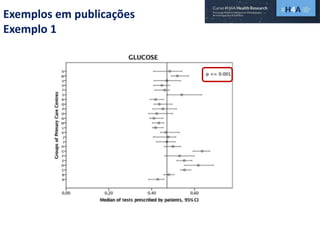

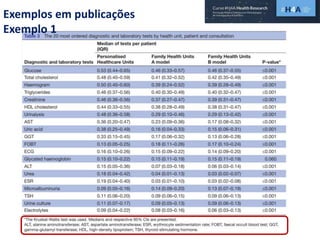





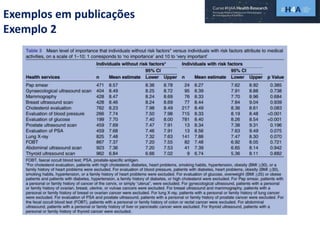





Este documento discute procedimentos estatísticos para testes de hipóteses, incluindo: 1) escolha entre testes paramétricos e não paramétricos dependendo do tamanho e distribuição das amostras; 2) formulação de hipóteses nulas e alternativas; 3) cálculo e interpretação de estatísticas de teste como o teste t. Exemplos ilustram como aplicar esses procedimentos para testar diferenças entre médias em diferentes tipos de amostras.



































































