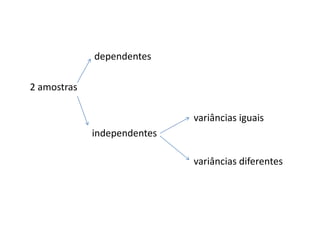
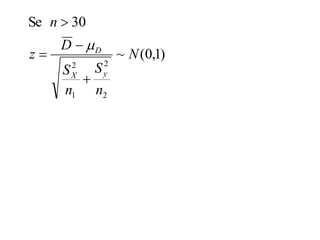Este documento descreve testes estatísticos para comparar duas médias amostrais, discutindo casos de amostras dependentes e independentes, com variâncias iguais ou diferentes. É apresentado um exemplo completo ilustrando o teste t para amostras dependentes e o teste t para amostras independentes com variâncias iguais.