O documento discute os conceitos e métodos de amostragem para estimar parâmetros de uma população. Ele aborda como calcular o tamanho da amostra para populações finitas e infinitas, e como lidar com situações em que o desvio padrão da população é desconhecido. Além disso, explica os métodos de amostragem estratificada e como determinar o tamanho da amostra para cada estrato.










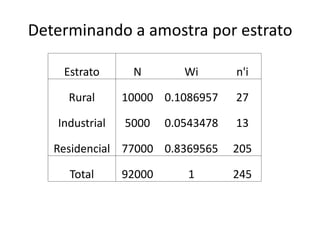










![Estatísticas e parâmetros
Um parâmetro é uma medida usada para
descrever um característica da POPULAÇÃO.
E[X ] 2 Var[ X ]](https://image.slidesharecdn.com/aula10-planejamentodaamostra-100827132620-phpapp02/85/Aula-10-planejamento-da-amostra-22-320.jpg)




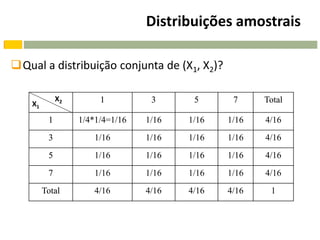


![Distribuições amostrais
A população {1,3,5,7} tem média =4 e variância 2=5.
A média da distribuição amostral de T é:
n
1 2 3 1 64
E[ X ] xi pi 1 2 3 7 4
i 1 16 16 16 16 16
2
Var[ X ] E[ X ] E 2 [ X ] 18,5 16 2,5](https://image.slidesharecdn.com/aula10-planejamentodaamostra-100827132620-phpapp02/85/Aula-10-planejamento-da-amostra-31-320.jpg)

































































































