Transferir como PDF, PPTX










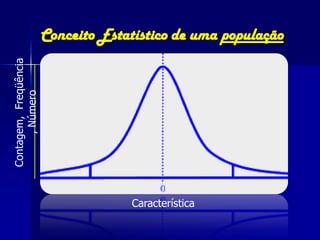










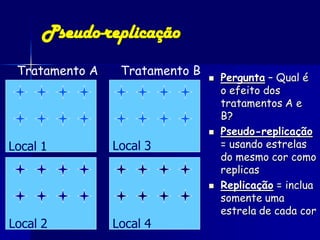





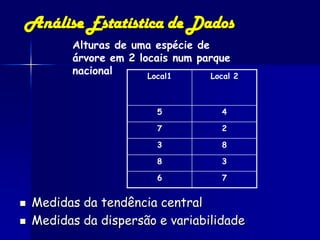

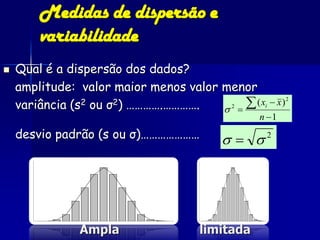
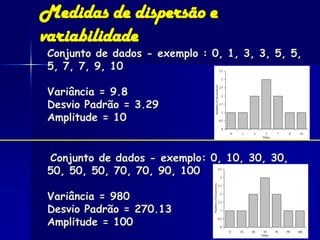

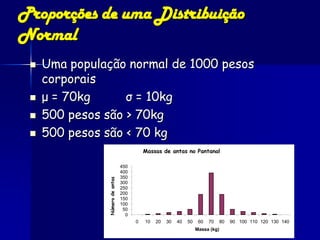





O documento fornece um resumo sobre análise estatística de dados ecológicos. Ele discute conceitos como amostragem, variáveis, populações, amostras, parâmetros e estatísticas. Além disso, explica medidas de tendência central, dispersão e variabilidade de dados, e testes estatísticos como t-teste, ANOVA e regressão que podem ser usados para analisar dados ecológicos.














































![Estatistica[1]](https://cdn.slidesharecdn.com/ss_thumbnails/estatistica1-120719160006-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









![XVII SAMET -2ª feira - Mini-curso [Dra. Simone Ferraz]](https://cdn.slidesharecdn.com/ss_thumbnails/xviisametdra-simoneferraz-101202183744-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












































