Baixar para ler offline













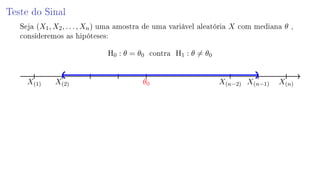

































O documento descreve um teste estatístico para verificar se a mediana do teor de impureza de um produto químico é igual a 2,5 ppm. Foram observadas 36 amostras aleatórias, sendo que 24 tinham teor de impureza menor que 2,5 ppm. O teste estatístico utilizado foi o teste dos sinais, que comparou o número de amostras com teor menor ou maior que 2,5 ppm. O valor-p calculado para este teste foi 0,0228.























































































