1) O documento discute técnicas de análise de correlação e associação, incluindo coeficientes de correlação de Pearson, Spearman e contingência.
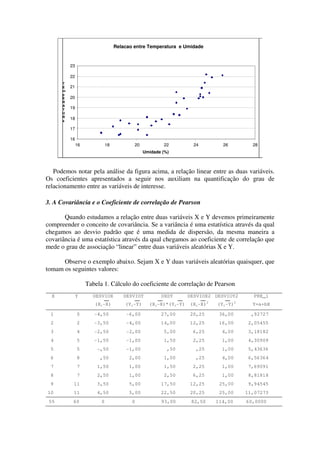
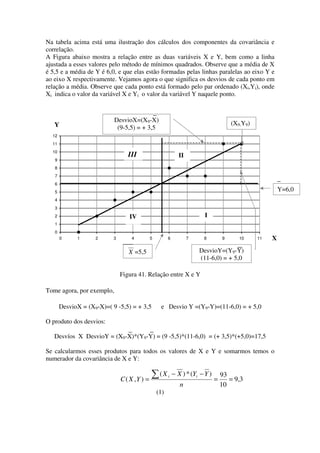
2) É apresentado o conceito de covariância e como é usado para calcular o coeficiente de correlação de Pearson, uma medida da força da relação linear entre duas variáveis.
3) O coeficiente de determinação é introduzido como a proporção da variação de uma variável explicada pela outra e é igual ao quadrado do coeficiente de correlação.