Baixado 31 vezes











![NORMAL
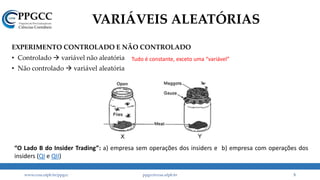
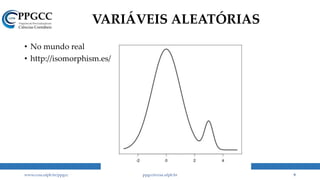
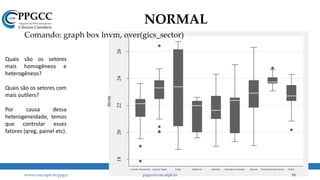
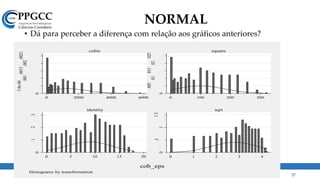
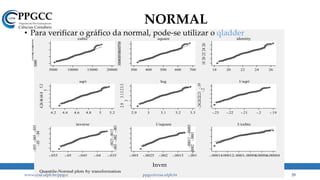
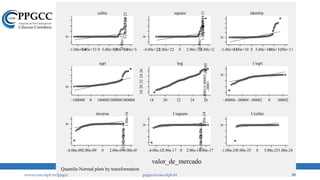
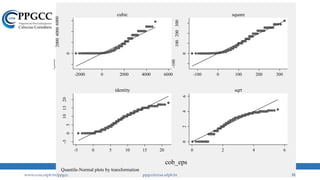
• Na prática, o que encontramos são coisas assim:
www.ccsa.ufpb.br/ppgcc ppgcc@ccsa.ufpb.br 13
0
2
4
6
8
10
12
14
16
18
20
-0.1 0 0.1 0.2 0.3
acc_disc_abs
acc_disc_abs
N(0.036252,0.051882)
Test statistic for normality:
Chi-square(2) = 356.744 [0.0000]
0
5
10
15
20
25
30
0.00 0.05 0.10 0.15 0.20 0.25 0.30
Series: ACC_DISC_ABS
Sample 1 89
Observations 89
Mean 0.036252
Median 0.020848
Maximum 0.334798
Minimum 6.94e-18
Std. Dev. 0.051882
Skewness 3.665601
Kurtosis 18.70847
Jarque-Bera 1114.363
Probability 0.000000
05
101520
0 .1 .2 .3 .4
acc_disc_abs
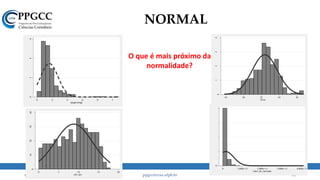
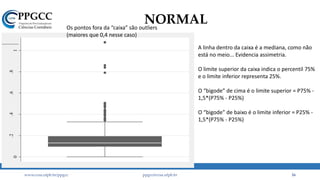
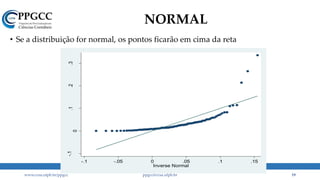
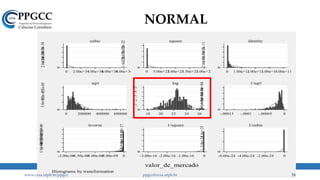
A assimetria é muito maior do que 0,5.
Regra geral: -0,5 < Skew < 0,5.
A Normal tem curtose = 3.
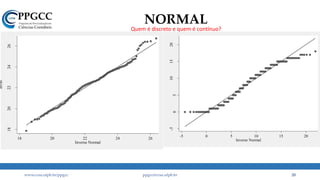
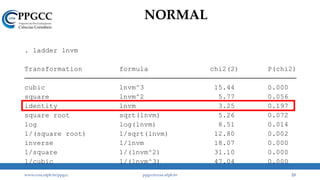
A partir dessa análise, o que pode ter
gerado nosso “problema”?
No Eviews, GRETL e Stata.](https://image.slidesharecdn.com/aula2distribuicaodeprobabilidade-180311144132/85/Aula-2-Distribuicao-de-probabilidade-13-320.jpg)




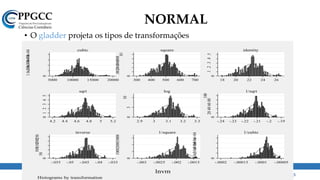








![AMOSTRAS E POPULAÇÕES
INTERVALO DE CONFIANÇA
• Nós convencionamos usar 95% como nível de confiança (Z = 1,96 para cada lado,
– 47,5% e + 47,5% = 95% - VER NA TABELA NORMAL = 5%/2 = 2,5%).
• Mesmo usando os 95% de nível de confiança, podemos ter a “sorte” de selecionar
uma amostra que gere uma média dentro dos 5% restantes. Exemplo com várias
amostras da idade da turma.
• Calcule a média do FCO e utilize o nível de 95% para estimar um intervalo de
confiança: Média amostral + ou – 1,96*[DP/(N^0,5)]. Considere que o desvio-
padrão da amostra é igual ao da população.
• Considerando que a um nível de significância de 90% o Z é 1,645 (90%/2 = 0,45
buscando 0,45 na Tabela Normal, temos 1,645 aproximadamente), estime o IC do
FCO.
• Agora considere um nível de 99% (Z = 2,575) para o mesmo FCO.
www.ccsa.ufpb.br/ppgcc ppgcc@ccsa.ufpb.br 39](https://image.slidesharecdn.com/aula2distribuicaodeprobabilidade-180311144132/85/Aula-2-Distribuicao-de-probabilidade-39-320.jpg)
![AMOSTRAS E POPULAÇÕES
DISTRIBUIÇÃO t
• Anteriormente consideramos que sabíamos o desvio-padrão da população.
Isso faz pouco sentido!
• Para poder usar o DP amostral, basta utilizar o ajuste nos graus de
liberdade que vimos na aula passada: Média amostral + ou – t*{DP/[(N –
1)^0,5]}.
• Em amostras grandes isso faz pouca diferença. À medida que aumentamos
os GL a t tende à normal.
• A tabela t de Student é um pouco diferente da normal, ela usa os GL (N-1)
e o alfa. Lembrem de dividir por 2, porque estamos falando de duas
caudas.
• Refaça os exercícios do slide anterior, considerando a tabela t.
www.ccsa.ufpb.br/ppgcc ppgcc@ccsa.ufpb.br 40](https://image.slidesharecdn.com/aula2distribuicaodeprobabilidade-180311144132/85/Aula-2-Distribuicao-de-probabilidade-40-320.jpg)






O documento aborda o conceito de distribuições de probabilidades e a importância da probabilidade na tomada de decisões, utilizando exemplos práticos e exercícios. Ele distingue variáveis aleatórias em contínuas e discretas e discute a relevância dos outliers na análise de dados. Além disso, menciona a normalidade das distribuições e apresenta formas de transformar dados para melhor adequação às condições estatísticas.



































































