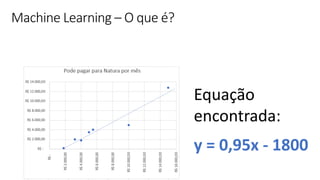
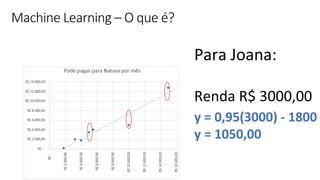
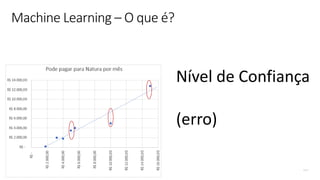
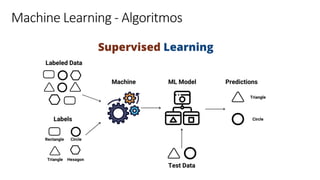
Transferir como PDF, PPTX




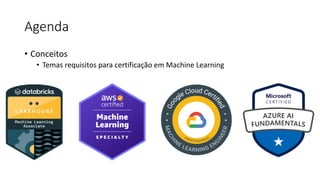









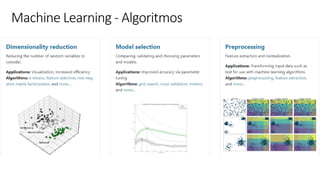









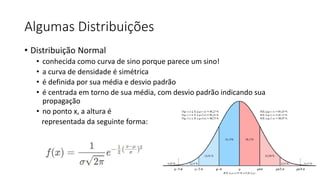






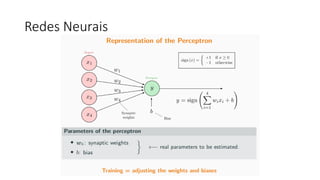



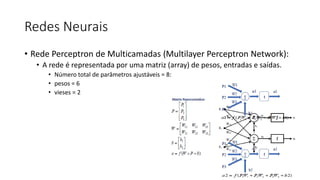









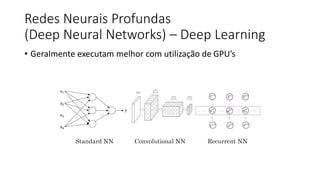



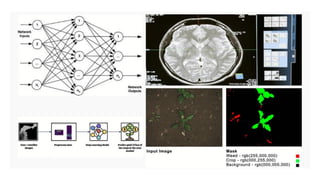




































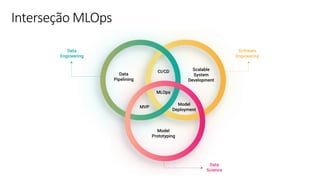






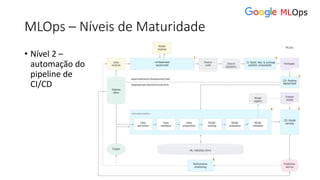



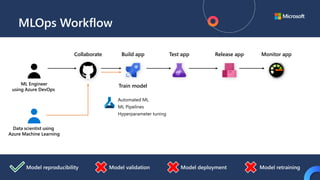

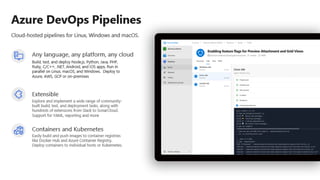

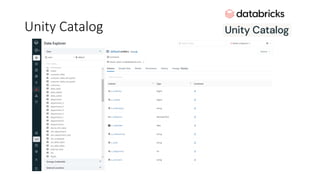
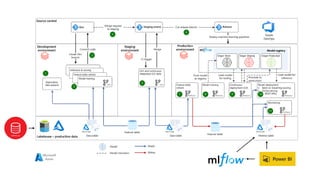
![ML Eng
Cloud Services
IDE
Data Scientist
[ { "cat": 0.99218,
"feline": 0.81242 }]
IDE
Apps
Edge Devices
Model Store
Consume Model
DevOps
Pipeline
Customize Model
Deploy Model
Predict
Validate
&
Flight
Model
+
App
Update
Application
Publish Model
Collect
Feedback
Deploy
Application
Model
Telemetry
Retrain Model
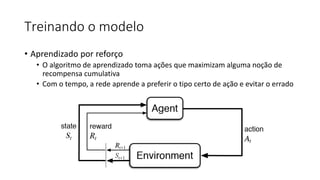
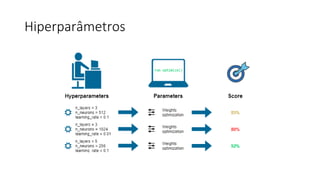
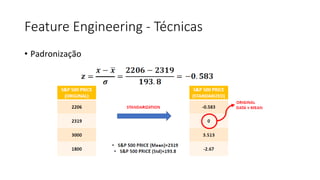
ML + App Dev Process
Model Versioning & Storage](https://image.slidesharecdn.com/treinamentomlopsdatabricks-230811205344-1105d93f/85/Treinamento-MLOps-Databricks-2023-160-320.jpg)

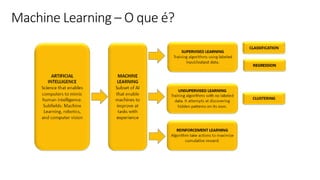
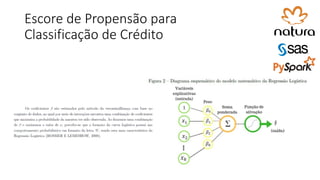
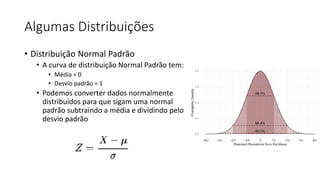
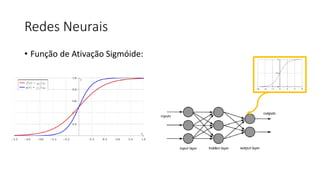
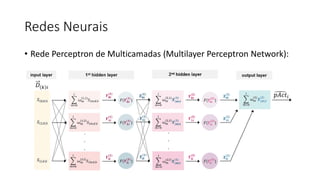
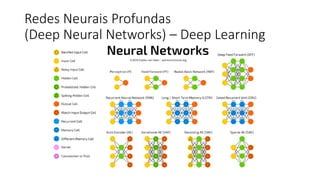
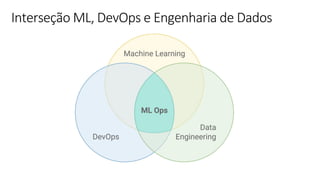
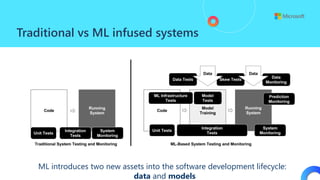
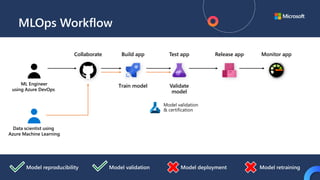
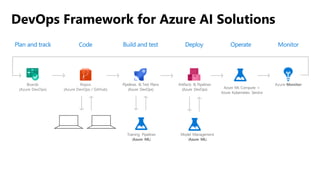
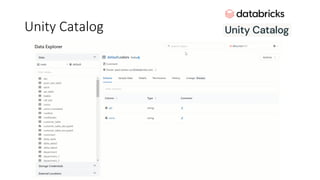
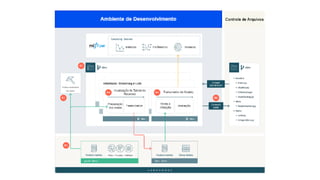
![ML Eng
Cloud Services
IDE
Data Scientist
[ { "cat": 0.99218,
"feline": 0.81242 }]
IDE
Apps
Edge Devices
Model Store
Consume Model
DevOps
Pipeline
Customize Model
Deploy Model
Predict
Validate
&
Flight
Model
+
App
Update
Application
Publish Model
Collect
Feedback
Deploy
Application
Model
Telemetry
Retrain Model
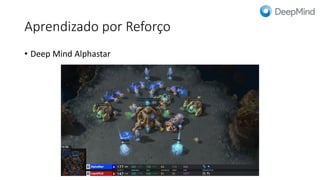
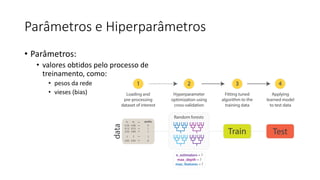
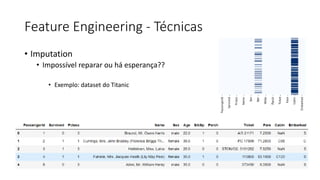
ML + App Dev Process Model Validation](https://image.slidesharecdn.com/treinamentomlopsdatabricks-230811205344-1105d93f/85/Treinamento-MLOps-Databricks-2023-162-320.jpg)
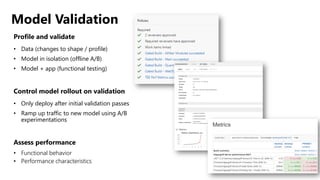
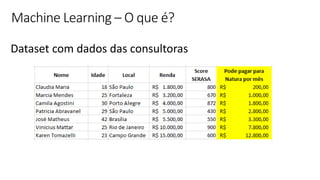
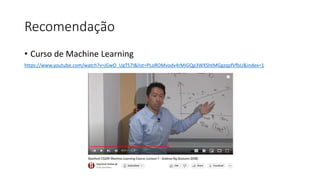
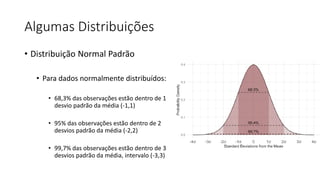
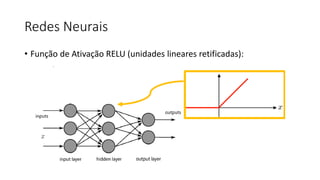
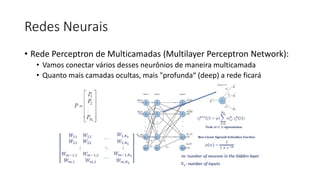
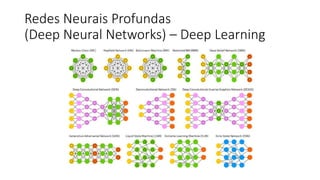
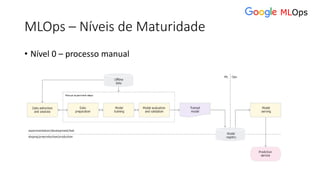
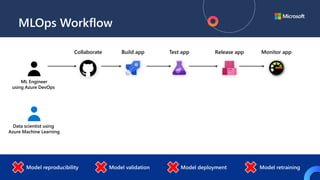
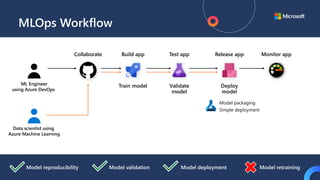
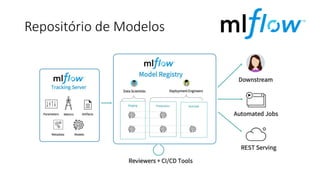
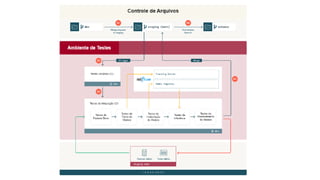
![ML Eng
Cloud Services
IDE
Data Scientist
[ { "cat": 0.99218,
"feline": 0.81242 }]
IDE
Apps
Edge Devices
Model Store
Consume Model
DevOps
Pipeline
Customize Model
Deploy Model
Predict
Validate
&
Flight
Model
+
App
Update
Application
Publish Model
Collect
Feedback
Deploy
Application
Model
Telemetry
Retrain Model
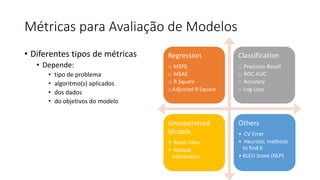
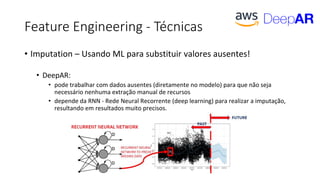
ML + App Dev Process
Inference Deployment](https://image.slidesharecdn.com/treinamentomlopsdatabricks-230811205344-1105d93f/85/Treinamento-MLOps-Databricks-2023-164-320.jpg)
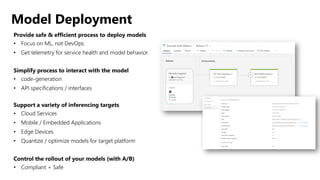
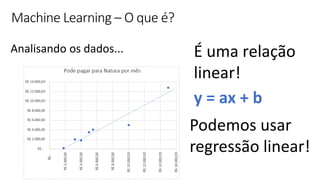
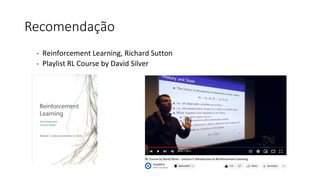
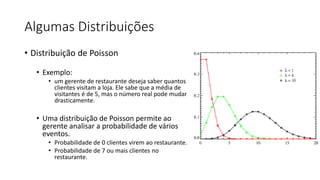
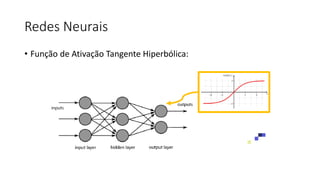
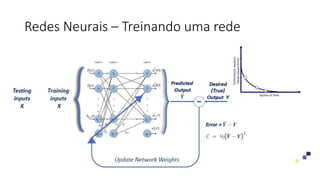
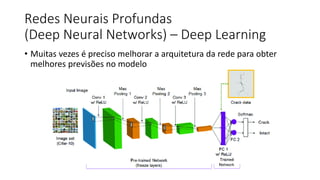
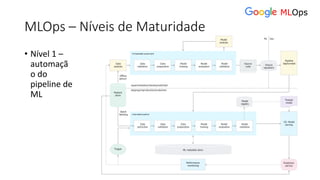
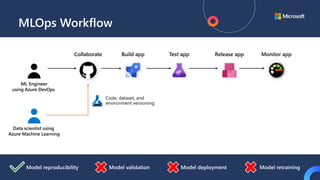
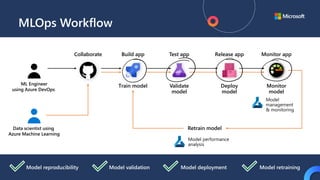
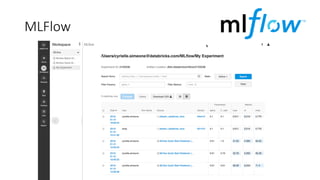
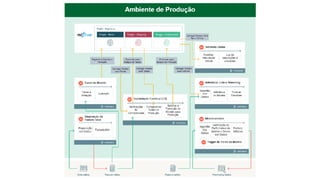
![ML Eng
Cloud Services
IDE
Data Scientist
[ { "cat": 0.99218,
"feline": 0.81242 }]
IDE
Apps
Edge Devices
Model Store
Consume Model
DevOps
Pipeline
Customize Model
Deploy Model
Predict
Validate
&
Flight
Model
+
App
Update
Application
Publish Model
Collect
Feedback
Deploy
Application
Model
Telemetry
Retrain Model
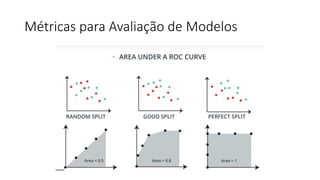
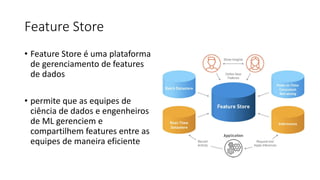
ML + App Dev Process
Re-training Deployment](https://image.slidesharecdn.com/treinamentomlopsdatabricks-230811205344-1105d93f/85/Treinamento-MLOps-Databricks-2023-167-320.jpg)
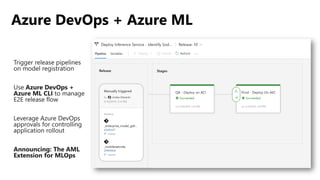

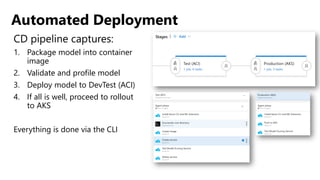




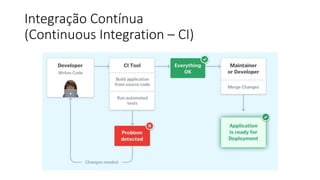








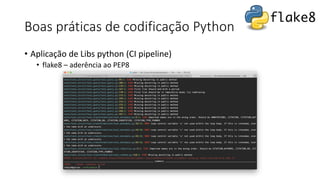
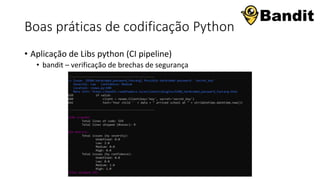
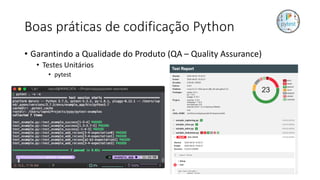



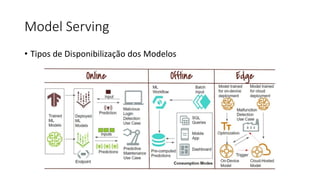

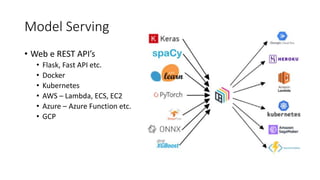
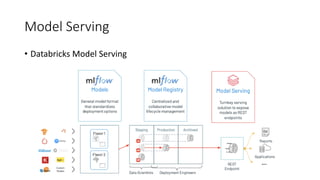



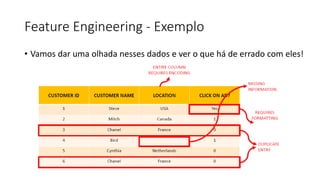
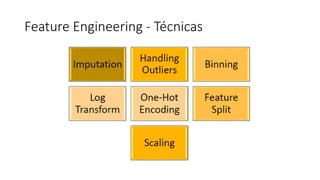






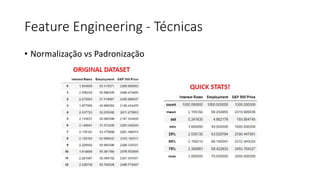










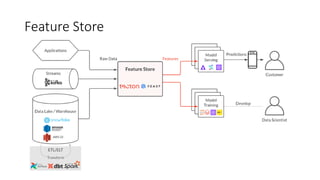




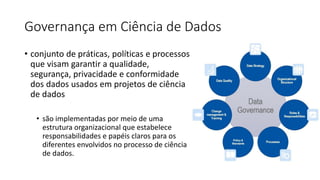




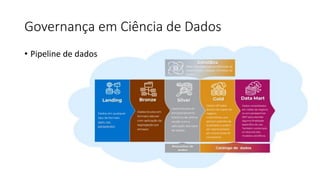

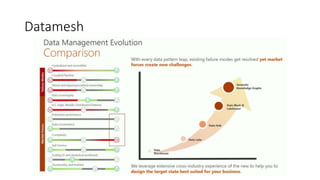
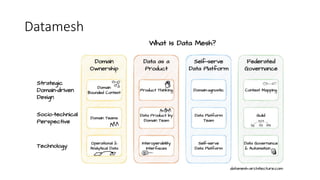

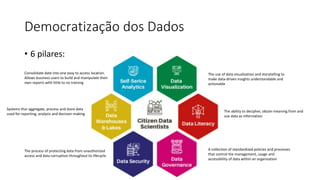


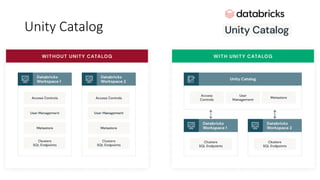




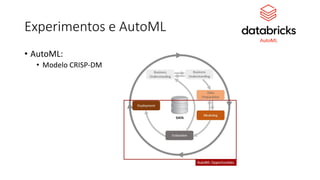
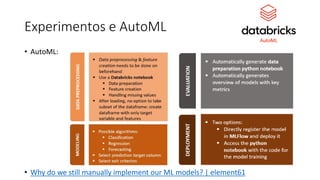



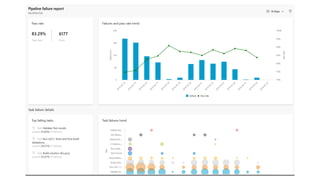


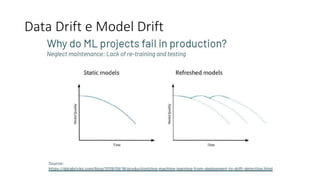
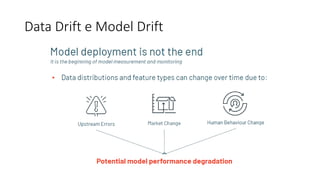

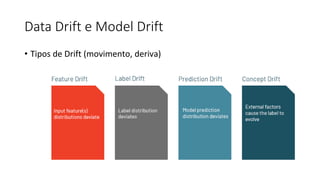

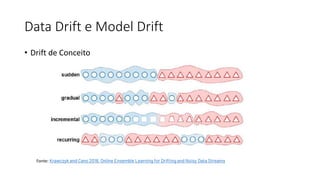













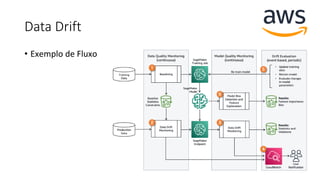
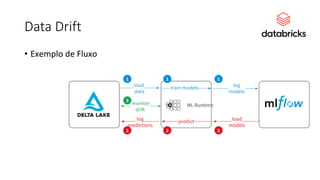








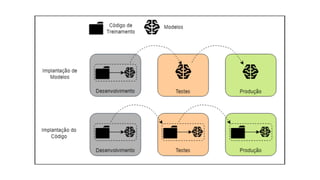
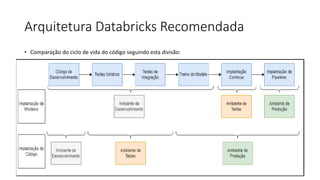







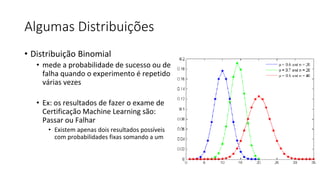
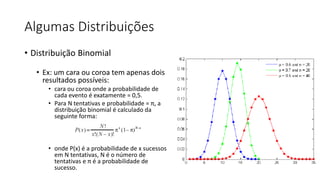
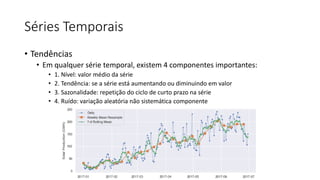
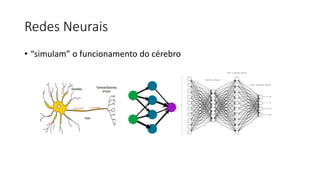
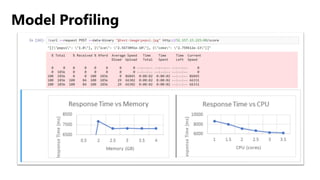
Este documento apresenta conceitos fundamentais de machine learning e MLOps, incluindo: (1) introdução à machine learning e seus algoritmos, (2) conceitos de MLOps e ciclo de vida MLOps, (3) boas práticas de codificação em Python para ML, e (4) arquitetura recomendada para ML na Databricks.






































![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)






