Obter um modeloque explique o
comportamento dos exemplos
observados (respostas) e usar
esse modelo para fazer predições
Objetivos
Planejamento
A amostra de dados deve ser representativa,
isto é, cobrir amplamente o domínio do
problema considerando as operações
rotineiras, e as exceções
Amostra
Definição da metodologia a ser aplicada,
avaliação da adequação do modelo e
interpretação dos resultados
Previsão
Previsão
Previsão é similarà Classificação
Primeiro construa um modelo
Depois, use o modelo para a previsão do valor
desconhecido
O método mais importante de previsão é a
regressão
Regressão linear e múltipla
Regressão não linear
Previsão é diferente de Classificação
Na classificação, a variável a “explicar” é categorica
Na previsão, a variável a “explicar” é contínua
5.
Sejam os valoresde uma variável dependente (resposta) Y
relacionados com os valores valores de m variáveis
independentes Xk por meio de um modelo estocástico
Yt = 0+ 1X1+ 2X2+...+ mXm + t t = 1,...,n
k – parâmetro desconhecido que indica o grau de associação
linear da variável independente Xk com a variável
dependente Y
t – erro aleatório devido a natureza estocástica de Y
Regressão Linear Múltipla
6.
Suposições para aanálise do modelo
de Regressão Linear
Resíduos homocedásticos, isto é, com variância
constante, não correlacionados e média zero
Normalidade nos resíduos (não necessariamente)
Número de parâmetros menor que o número de
observações (problema de overfitting)
7.
Métodos de Estimaçãodos
Parâmetros
Mínimos Quadrados
Máxima Verossimilhança (suposição de
Normalidade para os resíduos)
Y = X +
Y – vetor de respostas (n 1)
X - matriz de observações independentes (n p)
- vetor de parâmetros
- vetor de erros (n 1)
Modelo
8.
Métodos de MínimosQuadrados
com suposição de normalidade
A idéia é obter uma estimativa b para o vetor de parâmetros
que minimize a soma de quadrados dos erros ’
Como E()=0 então o modelo é expresso por E(Y) = X
’
= (Y - X)’
(Y - X)
= Y’
Y - ’
X’
Y – Y’
X + ’X’X
= Y’
Y - 2’
X’
Y + ’X’X
A soma de quadrados de resíduos
9.
A solução dosistema é
Vetor de valores ajustados
Xb
Y
ˆ
0
β
ε
ε'
Obtendo
Y
'
X
β
)
X
X
(
'
Y
)
(
ˆ
b '
1
X
X
X
β
'
10.
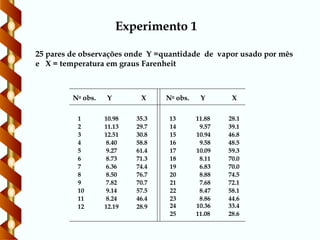
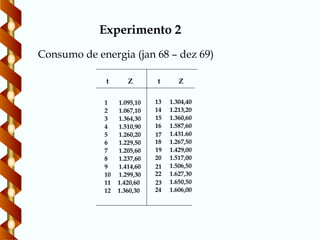
25 pares deobservações onde Y =quantidade de vapor usado por mês
e X = temperatura em graus Farenheit
Experimento 1
1 10.98 35.3 13 11.88 28.1
2 11.13 29.7 14 9.57 39.1
3 12.51 30.8 15 10.94 46.8
4 8.40 58.8 16 9.58 48.5
5 9.27 61.4 17 10.09 59.3
6 8.73 71.3 18 8.11 70.0
7 6.36 74.4 19 6.83 70.0
8 8.50 76.7 20 8.88 74.5
9 7.82 70.7 21 7.68 72.1
10 9.14 57.5 22 8.47 58.1
11 8.24 46.4 23 8.86 44.6
12 12.19 28.9
No
obs. Y Y
No
obs.
X X
24 10.36 33.4
25 11.08 28.6
11.
Modelo: Yt =0+ 1X1+ t t = 1,...,25
2
i
1
0
n
1
i
i
'
)
X
Y
(
S
0
)
X
Y
(
2
S n
1
i
i
1
0
i
0
0
)
X
Y
(
X
2
S n
1
i
i
1
0
i
i
1
12.
n
i
i
1
0
i 0
)
X
b
b
Y
(
n
i
i
1
0
i
i0
)
X
b
b
Y
(
X
As estimativas b0 e b1 são obtidas por
Então
X
b
Y
b 1
0
n
1
i
2
2
i
n
1
i
2
2
i
1
X
n
X
Y
n
Y
b
)
X
X
(
b
Y
Ŷ 1
Equação da regressão estimada:
13.
432
.
11821
Y
X
1315
X
60
.
235
Y i
i
i
i
Para n = 25 e
424
.
9
Y
60
.
52
X
42
.
76323
X
2
i
079829
.
0
42
.
7154
128
.
571
b1
t
t
1
t X
080
.
0
623
.
13
)
X
X
(
b
Y
Ŷ
Portanto e
14.
30 40 5060 70 80
6
7
8
9
10
11
12
13
X
Y
80
70
60
50
40
30
11,5
10,5
9,5
8,5
7,5
ajustados
Valores
X
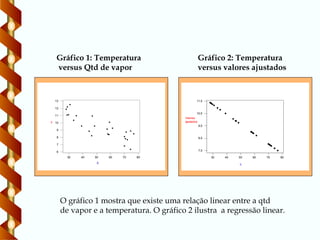
Gráfico 2: Temperatura
versus valores ajustados
Gráfico 1: Temperatura
versus Qtd de vapor
O gráfico 1 mostra que existe uma relação linear entre a qtd
de vapor e a temperatura. O gráfico 2 ilustra a regressão linear.
15.
Avaliação de desempenhodo modelo
de Regressão
R2
– mede a variabilidade de explicada
pelo modelo de regressão
2
t
i
t
2
t
2
)
Y
Y
(
)
Y
Ŷ
(
R
Y
Exemplo: Para os dados do experimento 1
71
.
0
81
.
63
5924
.
45
R2
Estatística
16.
Teste de aceitaçãodo modelo
H0: = 0
H1: 0
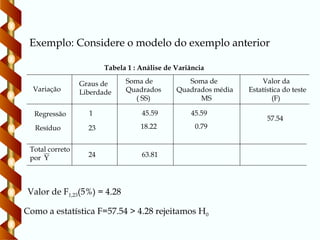
Tabela 1 : Análise de Variância
Regressão
Resíduo
Variação
Graus de
Liberdade
p-1
n-p
n-1
Total correto
por Y
Soma de
Quadrados
( SS)
Soma de
Quadrados média
(MS)
2
n
1
t
i )
Y
Ŷ
(
2
i
n
1
t
i )
Ŷ
Y
(
2
n
1
t
i Y
Y )
(
SSReg/(p-1)
s2
= SSRes/(n-p)
Estatística do teste
(F)
)
p
n
/(
SS
)
1
p
/(
SS
s
Re
g
Re
F tem distribuição F-snedcor com p-1,n-p graus de liberdade
e nível de significância
17.
Teste de aceitaçãodo modelo
Região de aceitação da hipótese H0
)
(
F
)
1
p
n
/(
SS
)
1
p
/(
SS
F 1
p
n
,
1
p
s
Re
g
Re
H0: Rejeita-se o modelo
H1: Aceita-se o modelo
18.
Regressão
Resíduo
Variação
Graus de
Liberdade
1
23
24
Total correto
porY
Soma de
Quadrados
( SS)
Soma de
Quadrados média
MS
45.59
0.79
Valor da
Estatística do teste
(F)
Tabela 1 : Análise de Variância
Exemplo: Considere o modelo do exemplo anterior
45.59
18.22
57.54
63.81
Valor de F1,23(5%) = 4.28
Como a estatística F=57.54 > 4.28 rejeitamos H0
19.
Teste de significânciado vetor de
parâmetros ()
Estatística do teste
)
b
(
Var
b
s
)
(
diag
b
T
i
i
2
1
ésimo
i
i
X
X'
H0: i = 0 (i = 1,...,p)
H1: i 0
Região de aceitação da hipótese H0
)
2
/
(
t
T p
n
T tem distribuição t-student com n-p graus de liberdade
20.
Intervalo de confiançapara o vetor b
)
b
(
Var
)
2
/
(
t
b i
p
n
i
b tem distribuição t-student(n-p)
i = 1,...p
Exemplo: Continuando com o exemplo anterior
H0: 1 = 0 (i = 1,...,p)
H1: 1 0
|T| =| -0.0798/0.0105| = 7.6 > t23(0.975)=2.069
Rejeita H0
Intervalo de confiança : -0.105 < 1< -0.0581
21.
Regression Analysis: C1versus C2
The regression equation is
C1 = 13,6 - 0,0798 C2
Predictor Coef SE Coef T P
Constant 13,6230 0,5815 23,43 0,000
C2 -0,07983 0,01052 -7,59 0,000
S = 0,8901 R-Sq = 71,4% R-Sq(adj) = 70,2%
Analysis of Variance
Source DF SS MS F P
Regression 1 45,592 45,592 57,54 0,000
Residual Error 23 18,223 0,792
Total 24 63,816
22.
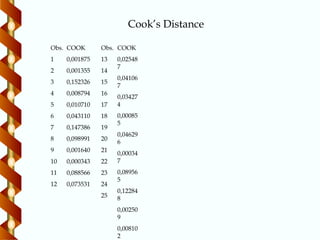
Outliers
São observações atípicasque podem ser relevantes
para a construção do modelo
Considere uma matriz H=(hij)nn = X(XT
X)-1
XT
Um procedimento paramétrico: Teste de Cook
Propriedades
a) 1
h
n
1
ii
b) 1
hii
Diagnóstico da Regressão
Análisedo modelo
Exemplo 1
Os resultados do ajustamento revelam que :
a variável temperatura é significativa no modelo (|t|=2.069 > 2)
a variabilidade dos dados explicada pelo modelo é boa (R2
= 0.71)
o valor da F=57.54 > F1,23(5%) indica que a regressão é significativa
ao nível de confiança de 95%
o modelo proposto não apresenta outilier (Di > F2,23(5%) = 3.42,
i = 1,...,23)
26.
Diagnóstico da Regressão
Análisegráfica dos resíduos
1 – Normalidade da variável resposta
2 – Independência das observações
3 – Homocedasticidade
4 – Se uma variável explicativa não incluída no
modelo é relevante
27.
25
20
15
10
5
1
0
-1
-2
Observation Order
Residual
Residuals Versusthe Order of the Data
(response is C1)
7,5 8,5 9,5 10,5 11,5
-2
-1
0
1
Fitted Value
Residual
Residuals Versus the Fitted Values
(response is C1)
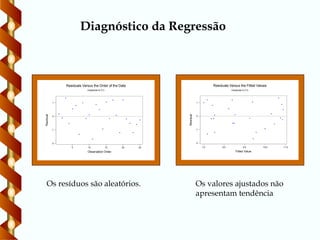
Diagnóstico da Regressão
Os resíduos são aleatórios. Os valores ajustados não
apresentam tendência
28.
1,5
1,0
0,5
-0,0
-0,5
-1,0
-1,5
7
6
5
4
3
2
1
0
Residual
Frequency
Histogram of theResiduals
(response is C1)
-2 -1 0 1
-2
-1
0
1
2
Normal
Score
Residual
Normal Probability Plot of the Residuals
(response is C1)
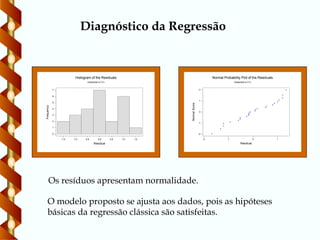
Diagnóstico da Regressão
Os resíduos apresentam normalidade.
O modelo proposto se ajusta aos dados, pois as hipóteses
básicas da regressão clássica são satisfeitas.
29.
Modelos de RegressãoNão Linear
A não linearidade é dada pela função de regressão
Yt = 0+ 1X1+ X2
+ t t = 1,...,n
Um método de estimação: Mínimos Quadrados não
Lineares
30.
Aplicável quando ovalor da variável resposta
é uma proporção
Modelo Logístico Linear
Suposição: A distribuição da variável dependente é
uma Bernoulli (1,) onde é a proporção de sucesso
m
m
1
1
0 X
...
X
1
log
onde = E(Y)
Método de estimação por Máxima Verossimilhança
31.
Parte II
Parte II
Mineraçãode Séries
Mineração de Séries
Temporais
Temporais
Mineração de Dados
Mineração de Dados
Seqüências
Seqüências
32.
Series temporais
Seriestemporais
• Consiste de sequencia de valores ou eventos que
Consiste de sequencia de valores ou eventos que
mudam com o tempo
mudam com o tempo
• Os dados são registrados em intervalos regulares
Os dados são registrados em intervalos regulares
• Componetes característicos das séries temporais
Componetes característicos das séries temporais
– Tendencia, ciclo, sazonalidade, aleatóriedade
Tendencia, ciclo, sazonalidade, aleatóriedade
Aplicações
Aplicações
• Finanças: preço de ações, inflação
Finanças: preço de ações, inflação
• Biomedicina: presão sanguinea
Biomedicina: presão sanguinea
• Metereologia: precipitação
Metereologia: precipitação
33.
Uma sérietemporal pode ser ilustrada por um gráfico que
Uma série temporal pode ser ilustrada por um gráfico que
descreve pontos que se movem ao longo do tempo
descreve pontos que se movem ao longo do tempo
Categorias de movimentos de séries temporais
Categorias de movimentos de séries temporais
• Tendencia à longo termo (curva de tendencia)
Tendencia à longo termo (curva de tendencia)
• Variações ciclicas
Variações ciclicas
• Variações Sazonais
Variações Sazonais
• Variações irregulares ou aleatórias
Variações irregulares ou aleatórias
34.
Estimação da Série
Estimaçãoda Série
Método manual
Método manual
• Ajustar a curva pela observação do gráfico
Ajustar a curva pela observação do gráfico
• Impraticavel para a mineraçào em larga escala
Impraticavel para a mineraçào em larga escala
O método dos minimos quadrados
O método dos minimos quadrados
Os métodos das médias móveis
Os métodos das médias móveis
• Eliminaçào de padrões ciclicos, sazonais e irregulares
Eliminaçào de padrões ciclicos, sazonais e irregulares
• Sensivel a valores aberrrantes
Sensivel a valores aberrrantes
35.
Descoberta de tendenciasem series temporais
Descoberta de tendencias em series temporais
Estimação de variações sazonais
Estimação de variações sazonais
• Indice sazonal
Indice sazonal
– Conjunto de valores que mostram os valores relativos de uma
Conjunto de valores que mostram os valores relativos de uma
variável durante os meses do ano
variável durante os meses do ano
– Ex, vendas em outubro, novembro e dezembro são 80%, 120%, e 140%
Ex, vendas em outubro, novembro e dezembro são 80%, 120%, e 140%
da média de vendas mensal do ano inteiro. Então 80, 120, e 140 são
da média de vendas mensal do ano inteiro. Então 80, 120, e 140 são
índices sazonais para esses meses
índices sazonais para esses meses
• Remoção da Sazonalidade
Remoção da Sazonalidade
– Dados ajustados com relação as variações sazonais
Dados ajustados com relação as variações sazonais
– Ex., dividir os meses originais pelos indices sazonais dos meses
Ex., dividir os meses originais pelos indices sazonais dos meses
correspondentes
correspondentes
36.
Descoberta de tendenciasem series temporais
Descoberta de tendencias em series temporais
Estimação das variações ciclicas
Estimação das variações ciclicas
• Se os ciclos ocorrem periodicamente (aproximadamente),
Se os ciclos ocorrem periodicamente (aproximadamente),
pode ser introzido um índice de cilco como os indices
pode ser introzido um índice de cilco como os indices
sazonais
sazonais
Estimação de variações irregulares
Estimação de variações irregulares
• Pelo ajustamento dos dados as variações de tendencia,
Pelo ajustamento dos dados as variações de tendencia,
ciclo e estação
ciclo e estação
Através da análise sistemática das tendencias,
Através da análise sistemática das tendencias,
cilcos, estações e componentes irregulares, é
cilcos, estações e componentes irregulares, é
possivel realizar previzoões de curto e longo prazo
possivel realizar previzoões de curto e longo prazo
de boa qualidade
de boa qualidade
37.
Busca por similaridadeem series temporais
Busca por similaridade em series temporais
Busca por similaridade encontra sequencias de dados
Busca por similaridade encontra sequencias de dados
que diferem apenas ligeiramente de uma dada
que diferem apenas ligeiramente de uma dada
sequencia
sequencia
Duas categorias de interrogações baseada em
Duas categorias de interrogações baseada em
similaridade
similaridade
• Sequencia matching: encontrar uma sequencia que é
Sequencia matching: encontrar uma sequencia que é
similar a sequencia de interrogação
similar a sequencia de interrogação
• Subsequencia matching
Subsequencia matching: encontrar todos os pares de
: encontrar todos os pares de
sequencias similares
sequencias similares
Aplicações
Aplicações
• Finanças Financial market
Finanças Financial market
• Bases de dados cientificas
Bases de dados cientificas
• Diagnostico médico
Diagnostico médico
38.
Uma Série Temporal
Umaconjunto de observações ordenadas no tempo
Exemplos
Z(t1), Z(t2),...,Z(tn)
- os valores diários do preço das ações de uma
empresa, na bolsa de valores (série econômica)
- os valores mensais de temperatura de uma cidade
- registro de eletrocardiograma de uma pessoa
39.
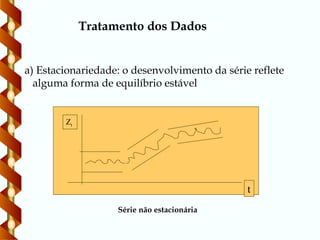
Tratamento dos Dados
a)Estacionariedade: o desenvolvimento da série reflete
alguma forma de equilíbrio estável
t
Zt
Série não estacionária
40.
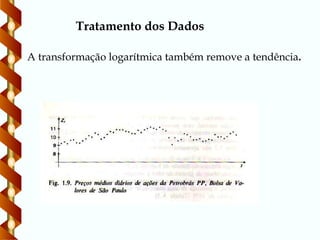
Tratamento dos Dados
b)Transformações
Diferenças sucessivas da série original
até obter-se uma série estacionária
Zt=Zt – Zt-1
2
Zt= [ Zt]
Presença de não estacionariedade
Logarítmica
Estabilização da variância
logZt=logZt – logZt-1
Componentes de umaSérie Temporal
Zt = Tt + St + t t =1,...n
Modelo
Clássico
Uma série Z1, Z2,...,Zn
Tt – tendência
t – erro aleatório
St – sazonalidade
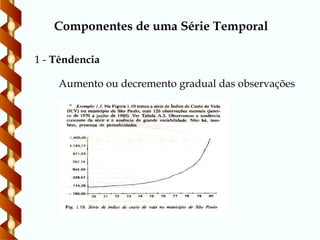
43.
1 - Têndencia
Aumentoou decremento gradual das observações
Componentes de uma Série Temporal
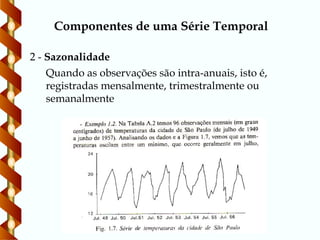
44.
Componentes de umaSérie Temporal
2 - Sazonalidade
Quando as observações são intra-anuais, isto é,
registradas mensalmente, trimestralmente ou
semanalmente
45.
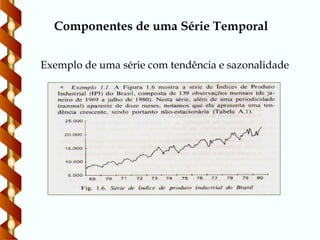
Exemplo de umasérie com tendência e sazonalidade
Componentes de uma Série Temporal
46.
Componentes de umaSérie Temporal
Removendo as componentes Tt e St a série é explicada
por um componente aleatório, t. A suposição é que t
tem média zero e variância constante .
Se as amplitudes sazonais St variam com a tendência,
então um modelo mais adequado é o multiplicativo
Zt = Tt St t t =1,...n
3 – Resíduo
Nota
47.
Função Perda
Erro QuadráticoMédio (EQM)
)
h
(
Ẑt é a previsão de Z(t+h)
EQM
2
t
2
t )]
h
(
e
[
E
)]
h
(
Ẑ
)
h
t
(
Z
[
E
Considere
48.
Métodos de estimaçãoda
Tendência
Zt = Tt + t t =1,...n
Suponha que a componente sazonal St não está presente e
que o modelo é aditivo
Existem vários métodos para estimar Tt
i) Ajustar os dados por uma função polinomial,
uma exponencial ou outra função suave de t
(Métodos paramétricos)
49.
i) utilizar diferenças(Método não paramétrico)
Métodos de estimação da
Tendência
i) suavizar ou filtrar os valores da série ao redor de
um ponto para estimar a tendência . (Método não
paramétrico)
Estimando a tendência através de , pode-se obter a
série livre de tendência
i
T̂
t
t
t
t
ˆ
T̂
Z
Y
50.
A tendência podeser observada através de uma inspeção
gráfica ou através de testes de hipóteses que pode ser
realizado de antes ou depois da estimação de Tt
Métodos de estimação da
Tendência
As hipóteses são
H0: não existe tendência
H1: existe tendência
Com base nas observações Zt (t=1,...,N)
51.
Métodos de estimaçãoda
Sazonalidade
Zt = Tt + St + t t =1,...n
As flutuações sazonais presentes em uma série tendem
a perturbar as outras componentes. Uma solução é
remover a componente, facilitando assim a identificação
e interpretação dos outros fenômenos.
Considere um modelo aditivo
ou multiplicativo
Zt = Tt St t t =1,...n
52.
Um procedimento deajustamento sazonal
Métodos de estimação da
Sazonalidade
a) obter estimativas e St
b) calcular a série sazonalmente ajustada
t
Ŝ
t
t
SA
t Ŝ
Z
Z
modelo aditivo
t
t
SA
t
Ŝ
Z
Z modelo multiplicativo
53.
Existem vários métodospara estimar a sazonalidade
Métodos de estimação da
Sazonalidade
a) Método de Regressão (método paramétrico)
b) Método de Médias Móveis (método não paramétrico)
c) Método de diferença sazonal
54.
Métodos de estimaçãoda
Sazonalidade
Pode se testar a existência de sazonalidade antes e depois
de sua estimação
H0: não existe sazonalidade determinística
H1: existe sazonalidade
a) Testes não paramétricos: Kruskal-Wallis, Friedman
b) Teste paramétrico: uma estatística F clássica tendo
como hipóteses
H0: S1 = S2 = ... Ss
H1: Si Sj para algum i e j
55.
Zt = t+ t t =1,...n
t
t M
)
h
(
Ẑ com h= 1,2,... (horizonte de previsão)
r
Z
...
Z
Z
M 1
r
t
1
t
t
t
r
Z
Z
)
1
h
(
Ẑ
)
h
(
Ẑ r
t
t
1
t
t
onde
E(t ) = 0, Var(t) = e t nível da série que varia com o tempo
Um método de Previsão de séries localmente
constantes - Médias Móveis (MM)
56.
O valor der deve ser proporcional à aleatoriedade
de t. Um procedimento é selecionar o valor de r
que minimize 2
1
t
N
1
j
t
t ))
r
(
Ẑ
Z
(
S
Vantagens do método MM:
Aplicável quando se tem poucas observações
Fácil aplicação
Um método de Previsão
Médias Móveis (MM)
57.
Desvantagens:
Aplicável apenas paraséries estacionárias
Dificuldade em determinar r
Uma alternativa é usar os modelos de Box & Jenkins
Um método de Previsão
Médias Móveis (MM)
57
,
597
.
1
4
Z
Z
Z
Z
)
h
(
Ẑ 24
23
22
21
24
PeríodoValor Real
Zt
Previsão
(h)
Ẑ24
25 1.696,4 1.597,57
26 1.767,5 1.597,57
27 1.554,8 1.597,57
28 1.727,5 1.597,57
29 2.231,8 1.597,57
30 2.211,7 1.597,57
h =1,...,5 e r = 4
Previsão com origem na observação 24
60.
05
,
645
.
1
4
Z
Z
Z
Z
)
1
(
Ẑ 25
24
23
22
25
PeríodoValor Real
Zt
Previsão
(h)
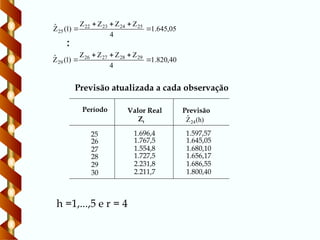
Ẑ24
25 1.696,4 1.597,57
26 1.767,5 1.645,05
27 1.554,8 1.680,10
28 1.727,5 1.656,17
29 2.231,8 1.686,55
30 2.211,7 1.800,40
h =1,...,5 e r = 4
Previsão atualizada a cada observação
40
,
820
.
1
4
Z
Z
Z
Z
)
1
(
Ẑ 29
28
27
26
29

































![Tratamento dos Dados
b) Transformações
Diferenças sucessivas da série original
até obter-se uma série estacionária
Zt=Zt – Zt-1
2
Zt= [ Zt]
Presença de não estacionariedade
Logarítmica
Estabilização da variância
logZt=logZt – logZt-1](https://image.slidesharecdn.com/regressiontimeseries-260205202935-e5d62d0c/85/RegressionTimeSeriesmachine-learnasw-ppt-40-320.jpg)


![Função Perda
Erro Quadrático Médio (EQM)
)
h
(
Ẑt é a previsão de Z(t+h)
EQM
2
t
2
t )]
h
(
e
[
E
)]
h
(
Ẑ
)
h
t
(
Z
[
E
Considere](https://image.slidesharecdn.com/regressiontimeseries-260205202935-e5d62d0c/85/RegressionTimeSeriesmachine-learnasw-ppt-47-320.jpg)

































![[Grupo 7] Conceitualização do Modelo.pptx.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/grupo7conceitualizaodomodelo-250829005610-621143ec-thumbnail.jpg?width=640&height=640&fit=bounds)





















