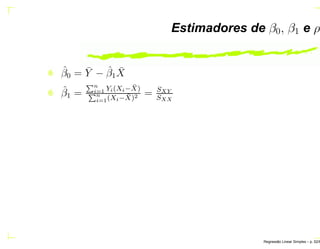
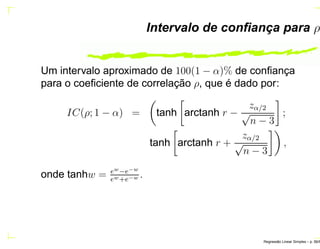
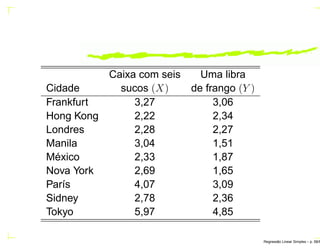
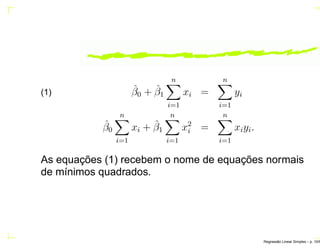
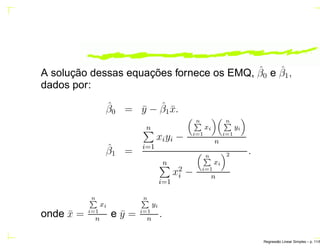
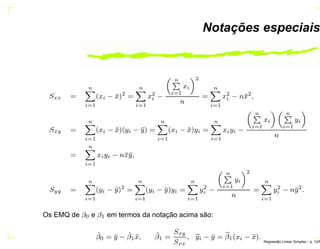
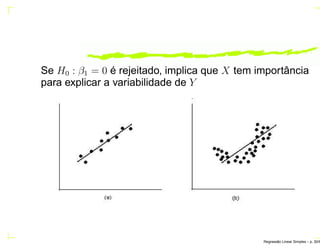
O documento discute regressão linear simples, apresentando seu objetivo de estudar a relação linear entre duas variáveis quantitativas através de coeficientes de regressão. Exemplos incluem a relação entre altura dos pais e filhos. O método dos mínimos quadrados ordinários é usado para estimar os parâmetros da função de regressão a partir de dados amostrais.




























![Previsão
Seja xp o valor para o qual deseja-se prever (ou projetar) o
valor médio E(Y |xp) e o valor individual de Y .
- Previsão média
Yi é um estimador não viciado de E[Y |xp], dado que
E(Yi) = E(ˆβ0 + ˆβ1xp) = β0 + β1xp = E(Y |xp)
V ar(Yi) = σ2
[1
n
+ (xi−¯x)2
sxx
]
- Previsão individual (Exercicio 4.)
V ar(Ypart) = σ2
[1 + 1
n
+ (xi−¯x)2
sxx
]
Na pratica sustituimos σ2
(desconhecido), pelo estimador
consistente σ2 Regress˜ao Linear Simples – p. 23/6](https://image.slidesharecdn.com/regressaosimples-160331130524/85/Regressao-simples-32-320.jpg)




![Teste de hipóteses sobre β0
H0 : β0 = β0,0, vs H1 : β0 = β0,0
A estatística
T =
ˆβ0 − β0,0
ˆσ2[1
n
+ ¯x2
Sxx
]
que tem distribuição t-Student com n − 2 graus de
liberdade. Rejeitamos a hipóteses nula se |Tobs| > tα/2, n−2.
Regress˜ao Linear Simples – p. 28/6](https://image.slidesharecdn.com/regressaosimples-160331130524/85/Regressao-simples-37-320.jpg)







![Intervalo de confiança para β0 e β1
Se para o MRLS é válida a suposição de que os
εi ∼ NID(0, σ2
), então
(ˆβ1 − β1)/ QMR/Sxx e (ˆβ0 − β0)/ QMR[
1
n
+
¯x2
Sxx
]
são variáveis aleatórias com distribuição t-Student com
n − 2 graus de liberdade.
Um intervalo de 100(1 − α)% de confiança para β1 :
IC(β1; 1−α) = ˆβ1 − tα
2
, n−2
QMR
Sxx
; ˆβ1 + tα
2
, n−2
QMR
Sxx
Regress˜ao Linear Simples – p. 36/6](https://image.slidesharecdn.com/regressaosimples-160331130524/85/Regressao-simples-48-320.jpg)
![De modo similar, um intervalo de 100(1 − α)% de confiança
para β0 é dado por:
IC(β0; 1 − α) = ˆβ0 − tα
2
, n−2 QMR[
1
n
+
¯x2
Sxx
]
ˆβ0 + tα
2
, n−2 QMR[
1
n
+
¯x2
Sxx
]
A seguir é obtido um intervalo de 95% de confiança para a
inclinação do MRLS com os dados do exemplo 1,
Regress˜ao Linear Simples – p. 37/6](https://image.slidesharecdn.com/regressaosimples-160331130524/85/Regressao-simples-49-320.jpg)


![Int. conf. 100(1 − α)% para µY |x0
IC(ˆµY |x; 1 − α) = ˆµY |xo − E; ˆµY |xo + E
onde E = tα
2
, n−2 QMR[1
n
+ (x0−¯x)2
Sxx
]
Exemplo: Suponha que tem-se interesse em construir um
intervalo de 95% de confiança da venda, média, semanal
para todos supermercados com 600 clientes.
Regress˜ao Linear Simples – p. 40/6](https://image.slidesharecdn.com/regressaosimples-160331130524/85/Regressao-simples-52-320.jpg)
![Int. conf. 100(1 − α)% para µY |x0
IC(ˆµY |x; 1 − α) = ˆµY |xo − E; ˆµY |xo + E
onde E = tα
2
, n−2 QMR[1
n
+ (x0−¯x)2
Sxx
]
Exemplo: Suponha que tem-se interesse em construir um
intervalo de 95% de confiança da venda, média, semanal
para todos supermercados com 600 clientes.
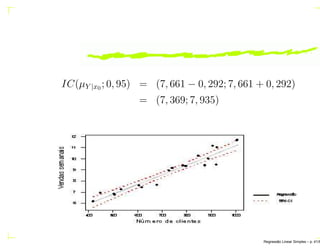
No modelo ajustado ˆµY |x0 = 2, 423 + 0, 00873x0. Para
x0 = 600, obtém-se ˆµY |x0 = 7, 661.
Regress˜ao Linear Simples – p. 40/6](https://image.slidesharecdn.com/regressaosimples-160331130524/85/Regressao-simples-53-320.jpg)
![Int. conf. 100(1 − α)% para µY |x0
IC(ˆµY |x; 1 − α) = ˆµY |xo − E; ˆµY |xo + E
onde E = tα
2
, n−2 QMR[1
n
+ (x0−¯x)2
Sxx
]
Exemplo: Suponha que tem-se interesse em construir um
intervalo de 95% de confiança da venda, média, semanal
para todos supermercados com 600 clientes.
No modelo ajustado ˆµY |x0 = 2, 423 + 0, 00873x0. Para
x0 = 600, obtém-se ˆµY |x0 = 7, 661. Também,
¯x = 731, 15, QMR = 0, 2513, Sxx = 614.603, n = 20
e 1 − α = 0, 95 ⇒ t0,05,18 = 2, 101.
Regress˜ao Linear Simples – p. 40/6](https://image.slidesharecdn.com/regressaosimples-160331130524/85/Regressao-simples-54-320.jpg)
![Int. conf. 100(1 − α)% para µY |x0
IC(ˆµY |x; 1 − α) = ˆµY |xo − E; ˆµY |xo + E
onde E = tα
2
, n−2 QMR[1
n
+ (x0−¯x)2
Sxx
]
Exemplo: Suponha que tem-se interesse em construir um
intervalo de 95% de confiança da venda, média, semanal
para todos supermercados com 600 clientes.
No modelo ajustado ˆµY |x0 = 2, 423 + 0, 00873x0. Para
x0 = 600, obtém-se ˆµY |x0 = 7, 661. Também,
¯x = 731, 15, QMR = 0, 2513, Sxx = 614.603, n = 20
e 1 − α = 0, 95 ⇒ t0,05,18 = 2, 101.
E = 2, 101 0, 2513[ 1
20
+ (600−731,15)2
614.603
] = 0, 292
Regress˜ao Linear Simples – p. 40/6](https://image.slidesharecdn.com/regressaosimples-160331130524/85/Regressao-simples-55-320.jpg)
![Previsão de novas observações
Uma aplicação muito importante de um modelo de
regressão é a previsão de novas ou futuras observações
de Y, (Y0) correspondente a um dado valor da variável
explicativa X, x0, então
ˆY0 = ˆβ0 + ˆβ1x0
é o melhor estimador pontual de Y0.
Um intervalo de 100(1 − α)% de confiança para uma futura
observação é dado por:
IC(Y0; 1 − α) = ( ˆY − E; ˆY + E)
onde E = tα
2
, n−2 QMR[1 + 1
n
+ (x0−¯x)2
Sxx
]
Regress˜ao Linear Simples – p. 42/6](https://image.slidesharecdn.com/regressaosimples-160331130524/85/Regressao-simples-57-320.jpg)
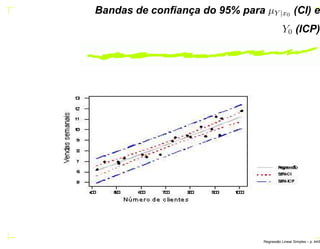
![Exemplo
Suponha agora, tem-se interesse em encontrar um
intervalo de previsão de 95% das vendas semanais de um
supermercado com 600 clientes.
Considerando os dados do exemplo 1, ˆY = 7, 661 e o
intervalo de predição é:
E = 2, 101 0, 2513[1 + 1
20
+ (600−731,15)2
614.603
] = 1, 084
IC(Y0; 0, 95) = (7, 661 − 1, 084; 7, 661 + 1, 084)
= (6, 577; 8, 745).
Regress˜ao Linear Simples – p. 43/6](https://image.slidesharecdn.com/regressaosimples-160331130524/85/Regressao-simples-58-320.jpg)