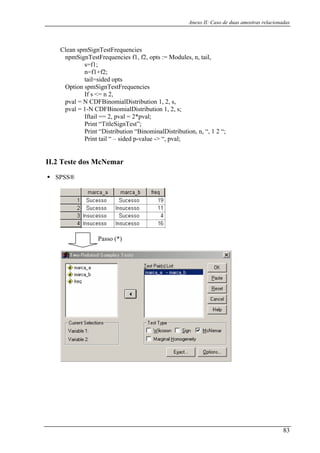
Este documento apresenta um resumo dos principais testes estatísticos não paramétricos para diferentes cenários de amostragem. Inclui testes para uma amostra, duas amostras relacionadas e independentes, k amostras relacionadas e independentes, e medidas de associação. Fornece exemplos e explicações detalhadas para cada teste.







![Capítulo 1: Caso de uma amostra
CAPITULO 1: CASO DE UMA AMOSTRA
Os testes estatísticos inerentes ao caso de uma amostra servem para comprovar uma
hipótese que exige a extracção de uma amostra. É usualmente usado para teste de aderência,
isto é, se determinada amostra provém de uma determinada população com uma distribuição
específica.
As provas de uma amostra verificam se há diferenças significativas na locação
(tendência central) entre a amostra e a população, se há diferenças significativas entre
frequências observadas e as frequências que poderíamos esperar com base em determinado
princípio, se há diferenças significativas entre as proporções observadas e as proporções
esperadas e se é razoável admitir que a amostra seja uma amostra aleatória de alguma
população conhecida.
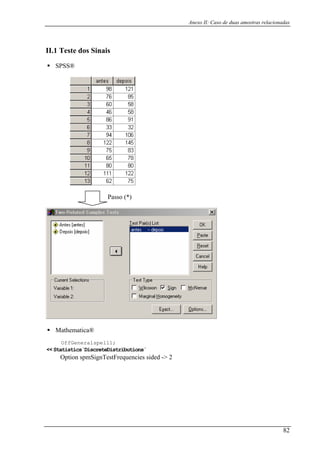
1.1 Teste da Binomial
Antes de falar no teste da Binomial, falemos um pouco da distribuição Binomial. Esta
distribuição é comum ser usada para a contagem de eventos de um modelo observado. É
baseado no pressuposto de que a contagem podem ser representada como um resultado de
uma sequência de resultados independentes de Bernoulli (por exemplo: o lançamento de uma
moeda). Se a probabilidade de observar um resultado R é P para cada n ensaios, então a
probabilidade que R será observado num ensaio x exacto é
xNx
x PP
x
N
p −
−⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
= )1(
A distribuição definida por: [ ] ),,1( NxpxXP x K=== é chamada distribuição
bi râmnomial com pa etros n e p. O nom que a expansão binomial dee aparece, pelo facto de
n
p)− é nPPP +++ K10 .
O Teste da Binomial aplica-se a amostras que provém de uma população, onde o
número de casos observados podem ser representados por uma variável aleatória que tenha
distribuição binomial. As amostras consistem em dois classes (ex: cara o
p 1( +
u coroa; sucesso ou
insucesso), deste modo este teste é aplicado a amostra de escala nominal.
(1.1.1)
6](https://image.slidesharecdn.com/monograf01estatnparamtbomamanha-140815020155-phpapp02/85/Monograf01estat-nparamt-bom-amanha-9-320.jpg)





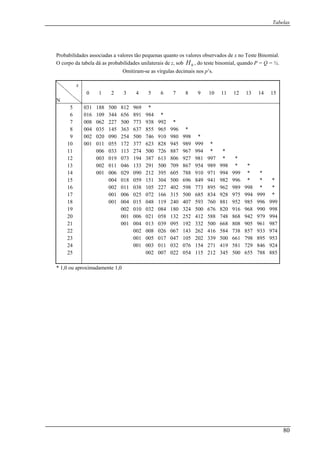
![Capítulo 1: Caso de uma amostra
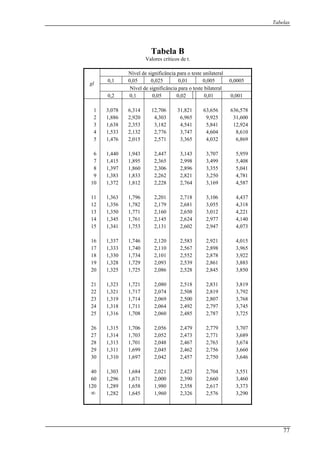
A tabela C indica que 48,62
≥χ para gl = 4 tem a probabilidade de ocorrência
entre 1,0=p e 2,0=p . Como p > α então não podemos rejeitar 0H . Concluindo que a
proporção de casos em cada categoria é igual, para um nível de 0,05.
Através deste exemplo, verifica-se que
tabela, deste modo, seria mais preciso se util
não podemos ir buscar o valor exacto de p na
assim, o SPSS® seria a melhor escolha, como
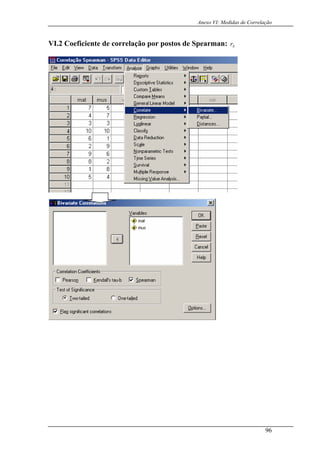
Output 1.2.1:
oderíamos utilizar o Mathematica®, através da função QuiQuadrada1Amostra[],
iQuadrada1Amostra 29,25,19,17,15
izarmos outros meios de cálculo mais eficazes,
ilustra o seguinte output:
P
dando como parâmetro a amostra:
Qu
PValue: 0.166297
como é observado, o
associad
a am
função de distribuição empírica da amostra define-se como a proporção das observações da
amostra que são menores ou iguais a
Mathematica® calcula com maior precisão o valor da probabilidade
a.
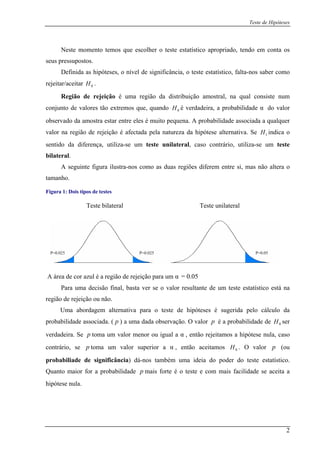
1.3 Teste de Kolmogorov-Smirnov
O Teste de Kolmogorov-Smirnov de um ostra é baseado na diferença entre a função
de distribuição cumulativa )(0 xF e a função de distribuição empírica da amostra )(xSn . A
x para todos os valores reais x . )(xSn dispõe dum
estimador pontual consistente para a verdadeira distribuição . Mais, através do teorema)(xFX
12](https://image.slidesharecdn.com/monograf01estatnparamtbomamanha-140815020155-phpapp02/85/Monograf01estat-nparamt-bom-amanha-15-320.jpg)
![Capítulo 1: Caso de uma amostra
de Glivenko-Cantelli1
, podemos afirmar que )(xSn aproxima-se da distribuição teórica.
Portanto, p ra um n grande, o desvio entre as duas dia stribuições, ,)()( xFxS Xn − fica cada
vez m is pequenos para todos os valores de x . Assim ficama os com o seguinte resultado:
)()(sup xFxD X
x
n −= (1.3.1)
À esta nD chama os estatística de Kolmogorov-Smirnov de uma amostra. É
particularmente út
Sn
tística m
i a a Estatística Não Paramétrica, porque a probabilidade de não
depen este modo, pode ser chamada estatística
sem distribuição.
l par nD
de de )(xFX desde que XF seja contínua. D nD
O desvio à direita e à esquerda definida por
[ ])()(sup xFxSD Xn
x
n −=+
[ ])()(sup xSxFD nXn −=−
(1.3.2)
x
são c
uições de são independentes de
podem s assumir, sem perda de generalidade, que é a distribuição uniforme com
par sim o s o seguinte teorema:
Teorema 1.3.1: Para
hamados estatísticas de Kolmogorov-Smirnov unilaterais. Estas medidas também não
têm distribuição.
Para que possamos utilizar a estatística de Kolmogorov para inferência, a distribuição
da amostra deve ser conhecida. Sabendo que as distrib nD XF ,
o XF
âmetros (0,1). As btemo
)()(sup xFxSD Xn
x
n −= onde é uma função distribuição
cumulativa contínua qualquer, temos:
)(xFX
1
Teore ko-Cantelli: converge uniformemente para com a probabilidade 1; que éma de Gliven )(xnS )(xFX
10)()(suplim =⎥⎦
⎤
⎢⎣
⎡ =−
∞<<∞−∞→
xFxSP Xn
xn
13](https://image.slidesharecdn.com/monograf01estatnparamtbomamanha-140815020155-phpapp02/85/Monograf01estat-nparamt-bom-amanha-16-320.jpg)




















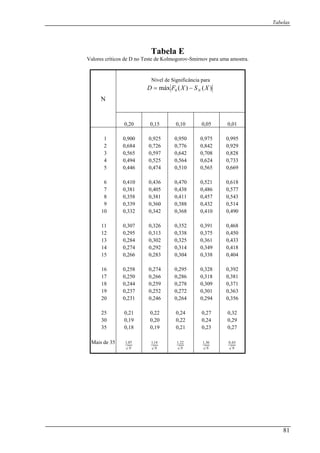
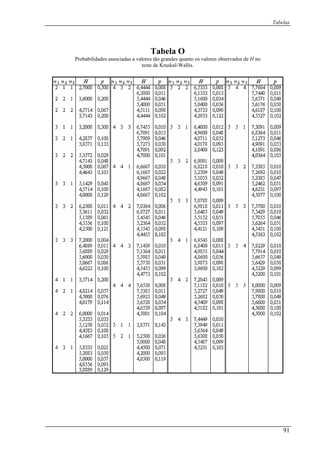
![Capítulo 3: Caso de duas amostras independentes
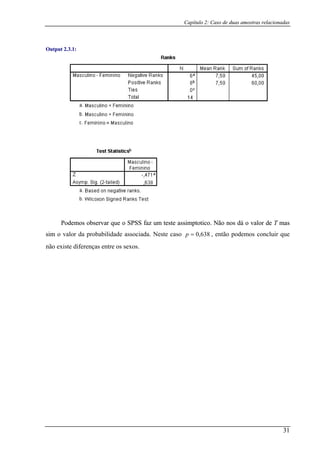
Tabela 3.1.3 (continuação):
Valores 21 21 22 23 23 24 24 24 29 31 45 55 56 75
Grupo B B B B B B B A A A A A A A
Iterações 3 4
Assim, ficamos com 42 =r .
Dado que 81 =n e 20212 >=n , então não podemos recorrer à tabela F. Para que
possamos calcular a probabilidade associada teremos que fazer uma aproximação à Normal
com o auxilio da fórmula (3.2.1):
Para : Para41 =r 62 =r :
[ ]
)1218()218(
218)21)(8)(2()21)(8)(2(
5,01
218
)21)(8)(2(
4
2
1
−++
−−
−⎟
⎠
⎞
⎜
⎝
⎛
+
+
−
=z
864,3=
[ ]
)1218()218(
218)21)(8)(2()21)(8)(2(
5,01
218
)21)(8)(2(
6
2
2
−++
−−
−⎟
⎠
⎞
⎜
⎝
⎛
+
+
−
=z
908,2=
Recorrendo à Tabela A, calcula-se o valor da probabilidade associada:
Para um 864,31 ≥z , verificamos que
0=p
Para um 908,22 ≥z , verificamos que a
0014,0
a probabilidade é probabilidade é
1 2 =p
Ambas as probabilidades e , são inferiores a1p 2p 01,0=α . Deste modo, concluímos
que os dois grupos de animais diferem significativamente nas suas taxas de aprendizagem
(reaprendizagem).
e gnificância este
método não teria efeito.
Caso, alguma das probabilidades fossem superior do que o nível d si
Vejamos como o SPSS® apresentava o resultado:
36](https://image.slidesharecdn.com/monograf01estatnparamtbomamanha-140815020155-phpapp02/85/Monograf01estat-nparamt-bom-amanha-39-320.jpg)




![Capítulo 3: Caso de duas amostras independentes
É claro que existe clara vantagens em utilizar o SPSS®. Pois, dá um quadro resume que
contém o valor exacto da probabilidade, a probabilidade assimptótica e tam ém o valor de U.
Tendo como principal vantagem o pouco tempo gasto para o emprego deste teste.
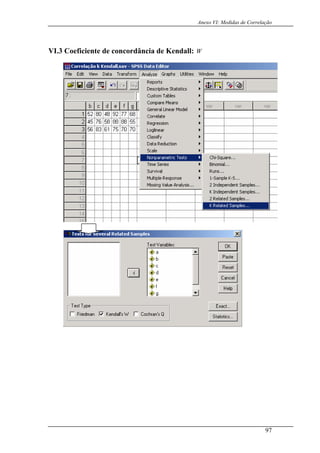
No Mathematica® coma ajuda da função npmMannWhitneyTest[list1,list2], fica:
Mat
Mat 0
rpm M
b
Ensino = 10.5, 16.5, 11, 9.8, 17.1, 1.5, 14.8, 9.9, 9.8, 10.3, 8.7
Informatica = 11.4, 12.9, 1 .1, 7.9, 8.8, 12.8
MannWhitneyTest MatEnsino, atInformatica
Title: Mann- Whitney Test
Sample Medians: 10.75, 10.3
Test Statistic: 32.
Distribution: Normal Approximation
2 - Sided PValue - > 0.919895
ina-se especificamente a dados de mensuração mínima na escala
ordinal. Esta prova tem como objectivo ver se as populações têm a mesma oscilação, isto é, o
teste de Moses é aplicável quando é previsto que um dos grupos tenha valores altos, e o outro
alores baixos.
deste teste é que não requer que as populações tenha medianas
iguais. Todavia, Moses (1952b) salienta que um teste baseado em medianas ou em postos
médios, por exemplo, o teste de Mann-Whitney, é mais eficiente, devendo, por
conse ialmente útil quando existem
razõe a priori para esperar que determinada condição experimental conduza a escores
extrem ou em outra direcção.
Mé
es são:
eja e o número de casos de controlo e experimentais respectivamente.
ar q eno arbitrário;
Esta função apenas dá um valor aproximado de p.
Podemos concluir que para fazer um teste com maior rigor e rapidez, o SPSS® seria a
melhor escolha, pois o SPPS® calcula o valor exacto.
3.3 Teste de Moses para reacções extremas
O teste de Moses dest
v
A principal vantagem
U
guinte, ser preferido à prova de Moses. Esta última é espec
s
os em uma
todo:
Os passos a seguir para o teste de Mos
S Cn En
1. Antes de reunir os dados deve-se especific Será um número pe uh .
41](https://image.slidesharecdn.com/monograf01estatnparamtbomamanha-140815020155-phpapp02/85/Monograf01estat-nparamt-bom-amanha-44-320.jpg)









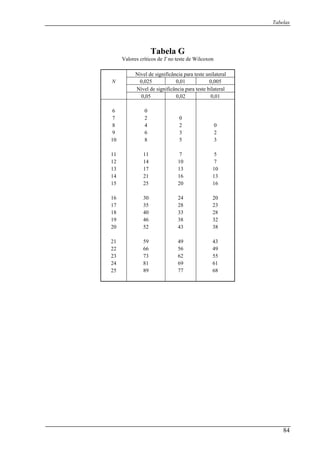
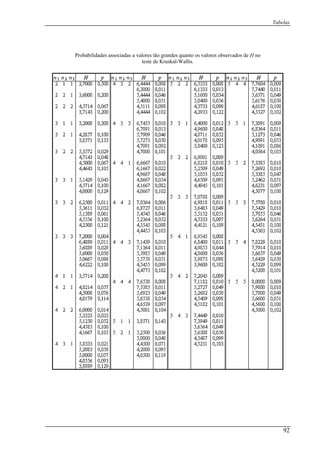
![Capítulo 4: Caso de k amostras relacionadas
Resolução:
As hipóteses são as seguintes:
: Cada fã tem um sistema de igual efeito para antever os resultados dos jogos de
futebol.
Existe diferenças nos efeitos dos sistemas criados pelos fãs.
Primeiro dispomos os resultados de novo numa tabela, que será apenas uma
modificação da tabela 4.1.1:
Tabela 4.1.2:
Fãs
0H
:1H
Jogos 1 2 3 4 iL 2
iL
1 1 1 0 0 2 4
2 1 1 1 0 3 9
3 1 1 1 0 3 9
4 0 1 1 0 2 4
5 0 1 0 0 1 1
6 1 1 0 1 3 9
jG 4 6 3 1 14 36
2
1jG 6 36 9 1 62
auxílio da fórmula 4.4.1:Então, após o cálculo dos somatórios temos, com o
( )[ ] 8,7
36144
146243
2
=
−×
−××
=Q
Calculamos agora a significância do valor observado, com a ajuda da tabela C:
314 =−=gl
Assim, como 05,002,0 ≤≤ p e 05,0=α , rejeitamos a hipótese, concluindo que existe
diferen feitos dos sistemas criados pelos fãs.ças nos e
52](https://image.slidesharecdn.com/monograf01estatnparamtbomamanha-140815020155-phpapp02/85/Monograf01estat-nparamt-bom-amanha-54-320.jpg)


![Capítulo 4: Caso de k amostras relacionadas
Exemplo 4.2.1:
A fim de avaliar se houve progressão na aprendizagem, um professor reteve as médias
de um grupo de 4 alunos no final de cada trimestre:
Tabela 4.2.1:
Alunos A B C D
1º Trimestre 8 15 11 7
2º Trimestre 14 17 13 10
3º Trimestre 15 17 14 12
Considerando um 05,0=α , que conclusão poderá tirar?
Hipóteses:
: Não houve progressão na aprendizagem ao longo do ano escolar;
Houve progressão ao longo do ano escolar.
Atribuímos os postos através da seguinte tabela e calculamos as somas:
Tabela 4.2.2:
Alunos 1º Trimestre 2º Trimestre 3º Trimestre
Resolução:
0H
:1H
A 1 2 3
B 1 2.5 2.5
C 1 2 3
D 1 2 3
jR 4 8.5 11.5
2
jR 16 72.25 132.25
Assim, fica:
e então4=N 3=k [ ] 125,7)13(4325,13225,7216
434
122
=+××−++×
××
=rχ
55](https://image.slidesharecdn.com/monograf01estatnparamtbomamanha-140815020155-phpapp02/85/Monograf01estat-nparamt-bom-amanha-57-320.jpg)











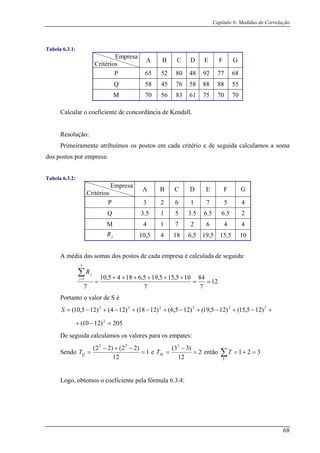


![Conclusão
Quadro 2: Caso de duas amostras s
Processo de
Resolução:
SPSS® Mathematica®
relacionada
Tabelas
Teste dos sinais
po
o valo
S
m
R
is
p
Fornec
rela
empa
positivos e negativos.
U
distr
par
O v
pre
n.º de casas decimais.
Nem sempre é
ssível determinar
r exacto de p;
ó para dimensões
enores que 25;
ecorre-se à tabela
D.
d
Utiliza a
tribuição Binomial
ara o cálculo da
probabilidade
e dados em
ção ao teste:
tes, sinais
tiliza também a
ibuição binomial
a o cálculo de p;
alor de p é o mais
ciso com maior
Teste de
McNemar
É empregue a
f
dá-
que
é c
val
Nã
Calcula um valor
distr
O calculo de p é
pr
pm
[]
órmula 2.2.1 que
nos o resultado
, posteriormente,
omparado com
ores da tabela C;
o temos o cálculo
de p.
assimptótico,
utilizando a
ibuição Binomial.
n
feito através de
ocedimento
BinomialPValue
, o mesmo da
Binomial.
Teste de
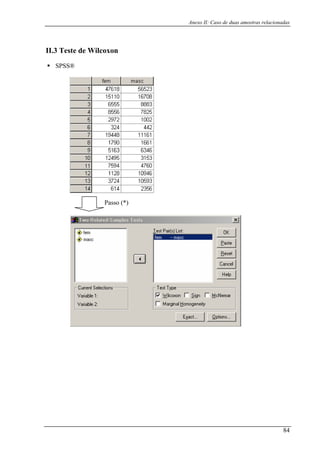
Wilcoxon
co
d
os
tabela G;
O c
as
b
n
Não calculamos o
valor de p, apenas
mparamos o valor
e T calculado com
tabelados na
álculo do valor
simptótico de p é
aseado nos números
egativos.
Não foi possível
conseguir um
procedimento.
71](https://image.slidesharecdn.com/monograf01estatnparamtbomamanha-140815020155-phpapp02/85/Monograf01estat-nparamt-bom-amanha-73-320.jpg)

![Conclusão
O SPSS® é mais fácil de trabalha te de fácil utilização, tornando-
uma ferramenta “popular”. O “output” de cada teste tem a vantagem de poder ser
a
ue o SPSS® pode fazer no campo da Estatística.
a
ão Paramétrica, pois poder-se-á desenvolver função para testar hipóteses utilizando os
s procedimentos, aqui utilizados, apresentam resultados com mais precisão do que o
S
r, pois apresenta um ambien
se
form tado ao gosto do utilizador. Este trabalho desenvolvido, é apenas uma ínfima parte do
q
O M thematica® é uma ferramenta preciosa na Matemática e em particular para a Estatística
N
diferentes métodos da Estatística.
O
SPS ®, podendo escolher o número de casas decimais com a função N[]. A programação
destes procedimentos encontra-se em anexo.
74](https://image.slidesharecdn.com/monograf01estatnparamtbomamanha-140815020155-phpapp02/85/Monograf01estat-nparamt-bom-amanha-76-320.jpg)