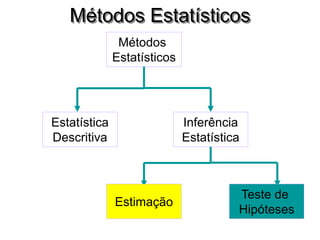
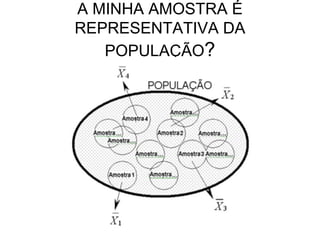
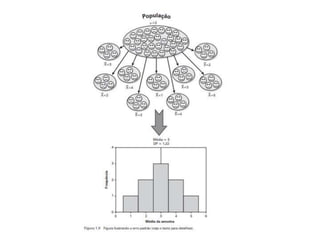
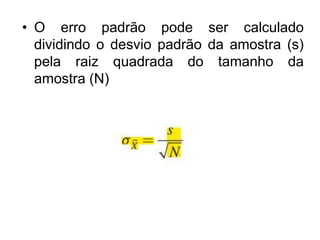
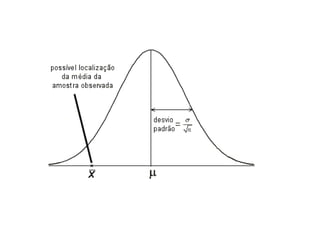
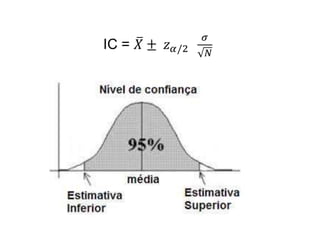
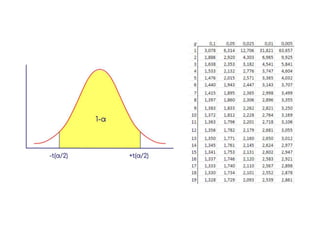
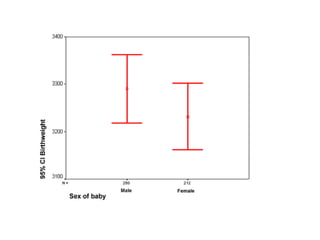
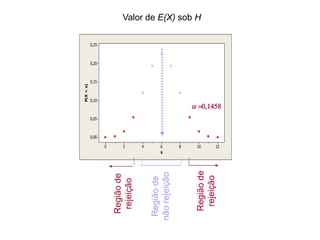
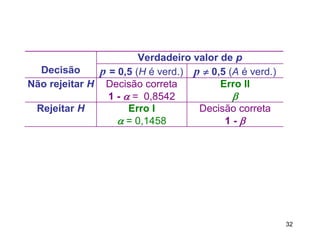
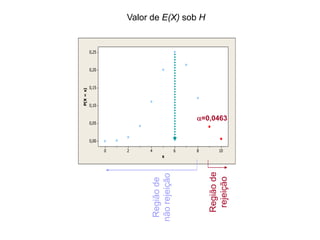
O documento discute noções de teste de hipóteses estatísticas. Explica que um teste de hipóteses envolve estabelecer uma hipótese nula e alternativa sobre um parâmetro populacional e definir uma regra de decisão para aceitar ou rejeitar a hipótese nula com base nos resultados de uma amostra. Também discute conceitos como nível de significância, região crítica, erros tipo I e tipo II e hipóteses unilaterais e bilaterais.