Baixado 12 vezes














![CAPÍTULO 2. DESCRIÇÃO NUMÉRICA DOS DADOS 10
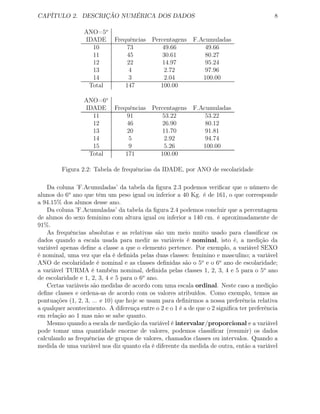
SEXO=feminino
Classes
de alturas Frequências Percentagens F.Acumuladas
altura<=130 5 4.03 4.03
130 a 135 42 33.87 37.90
135 a 140 66 53.23 91.13
140 a 145 10 8.06 99.19
altura>145 1 0.31 100.00
Total 124 100.00
SEXO=masculino
Classes
de alturas Frequências Percentagens F.Acumuladas
altura<=130 2 1.03 1.03
130 a 135 32 16.49 17.53
135 a 140 84 43.30 60.82
140 a 145 63 32.47 93.30
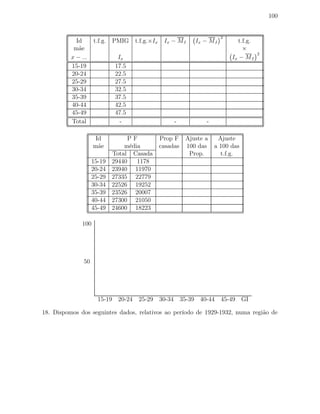
altura>145 13 6.70 100.00
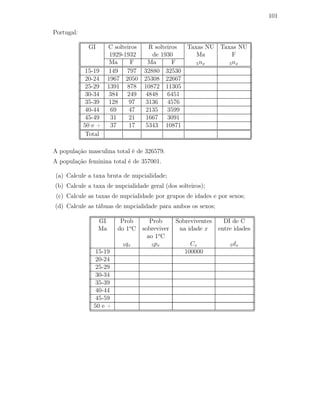
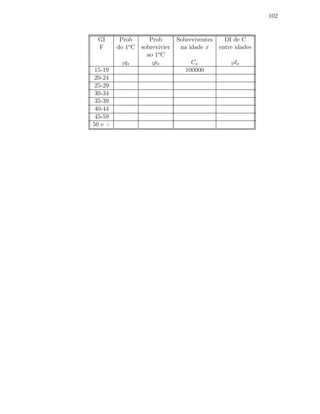
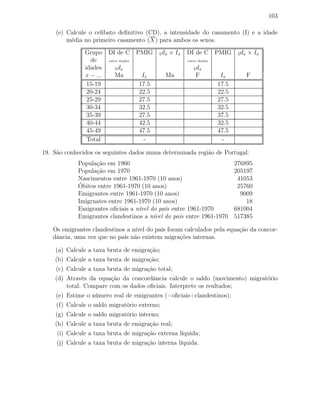
Total 194 100.00
Figura 2.4: Tabela das frequências das ALTURAS, por SEXO do aluno
2. (e como, para esta variável, todas as observações são quantidades inteiras) os limi-
tes dos intervalos são definidos usando valores com casas decimais, 0.5 unidades
inferiores ao valor, para o limite inferior, e 0.5 unidades superiores ao valor, para o
limite superior, de cada intervalo. Neste caso, ficamos com os seguintes intervalos
fechados nos dois extremos: [124.5, 130.5], [130.5, 135.5], [135.5, 140.5], [140.5, 145.5]
e [145.5, 150.5].
É também comum considerar os intervalos dos extremos como ’totalmente’ abertos, o
primeiro à esquerda, e o último à direita, isto é, o primeiro intervalo pode ser do tipo
≤ 130cm. e o último do tipo > 145cm. Verifique o processo utilizado na definição dos
intervalos para a variável ALTURA, na tabela da figura 2.4 e para a variável PESO na
tabela da figura 2.3.
A amplitude destas classes/intervalos é a diferença entre o limite superior e o inferior.
Para a variável ALTURA a amplitude dos intervalos é de 5 cm. e para o PESO é de 5 Kg.
Confirme estes valores nas tabelas das figura 2.4 e 2.3 respectivamente.
Como estes intervalos são definidos por um conjunto, por vezes, vasto de valores, há
necessidade de ter um valor que represente cada intervalo. Este valor é o ponto médio e
calcula-se como a semi-soma dos limites superior e inferior do intervalo. No caso da variável
ALTURA os pontos médios dos intervalos são respectivamente 127.5, 132.5, 137.5, 142.5 e
147.5 e para a classificação da variável PESO temos como pontos médios os valores: 27.5,](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-17-320.jpg)




![CAPÍTULO 3. DESCRIÇÃO GRÁFICA DOS DADOS 16
fe m inino
20
14
24
14
29
1
2
3
4
5
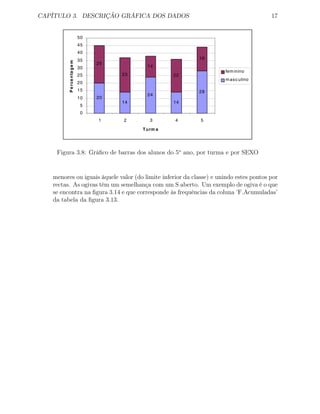
Figura 3.6: Gráfico de sectores dos alunos do 5o
ano do sexo feminino, por TURMA
]../pictures/sectoresm.eps
Figura 3.7: Gráfico de sectores dos alunos do 5o
ano do sexo masculino, por TURMA
sentar um histograma, devemos escolher intervalos (classes) com amplitudes iguais.
Não existe nenhum valor ideal para a amplitude da classe (intervalo). O objectivo
é conseguir obter uma distribuição de frequências equilibrada. Assim, tenta-se evi-
tar colocar todos os valores num número muito reduzido de classes de amplitudes
enormes ou distribuir poucos valores por muitas classes de amplitudes pequenas. As
classes devem ser definidas de tal forma que não haja ambiguidades sobre a classe
(ou intervalo) a que pertence cada observação.
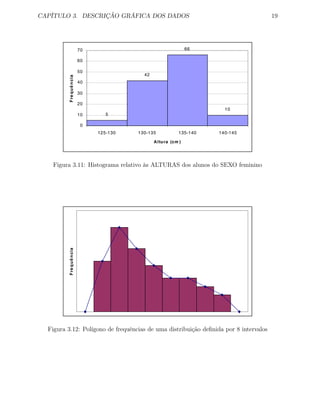
7. A forma da distribuição de frequências de um conjunto de dados pode ser analisada
através do histograma das frequências. A figura 3.12 mostra uma distribuição não
simétrica e descaída para a direita. Por vezes, a análise é facilitada pelo polígono que
se obtém unindo, por linhas, os pontos médios dos topos das barras no histograma,
como se vê na figura 3.12. O polígono é terminado para a esquerda e para a direita,
unindo os pontos que se colocam no eixo horizontal distanciados de metade da am-
plitude para a esquerda do primeiro intervalo e para a direita do último intervalo.
Este polígono é conhecido por polígono de frequências.
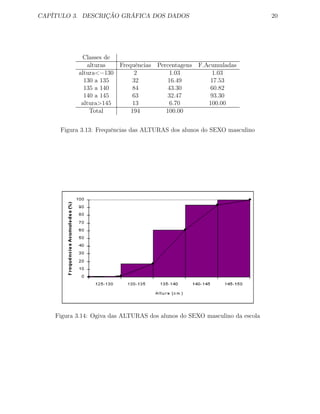
8. Ao gráfico das frequências acumuladas chama-se ogiva. Este gráfico obtém-se co-
locando pontos na vertical dos limites inferiores das classes (ou intervalos) a uma
distância do eixo horizontal que corresponde à percentagem das observações que são](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-23-320.jpg)

















![CAPÍTULO 9. ESTUDO DA TENDÊNCIA 42
i) as estimativas da tendência calculam-se em pontos médios de um intervalo
(exemplo com k = 4, m = 2)
ponto médio de [2, 3] =
X1 + X2 + X3 + X4
4
ponto médio de [3, 4] =
X2 + X3 + X4 + X5
4
ponto médio de [4, 5] =
X3 + X4 + X5 + X6
4
...
ii) para centrar estas médias, calcula-se uma 2a
média móvel de período 2
[2, 3] = X1+X2+X3+X4
4
[3, 4] = X2+X3+X4+X5
4
⇒
t3 =
X1+X2+X3+X4
4
+ X2+X3+X4+X5
4
2
.
Do mesmo modo
t4 =
X2+X3+X4+X5
4
+ X3+X4+X5+X6
4
2
, ...
O método das médias móveis é um caso particular dos filtros lineares, filtros esses que
transformam uma série X noutra Y , por meio de uma operação linear.
9.1.2 Método analítico
Com o método analítico a determinação da tendência é feita ajustando uma função da
variável tempo (t) ao cronograma da série cronológica.
Este ajuste é feito, em geral, pelo método dos mínimos quadrados.
De acordo com o tipo de função assim podemos ter tendências lineares, parabólicas,
exponenciais, ...
A função vai traduzir uma lei matemática que se admite ser seguida pela tendência.
A escolha do tipo de função a ajustar não é fácil e este processo deve ser iniciado com
a representação gráfica da série e inspecção cuidada do cronograma.
Tendência linear
O modelo mais simples que é possível representar é o modelo linear com a seguinte
forma:
Xt = α + βt. (9.1)
Como
Xt = α + β(t − t) = α + βt − βt = α − βt + βt,](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-49-320.jpg)
![CAPÍTULO 9. ESTUDO DA TENDÊNCIA 43
tem-se
α = α − βt (9.2)
em que t é a média aritmética dos tempos, t1, t2, ..., tn, e os valores de α e β são calculados
da seguinte maneira:
α =
X1 + X2 + ... + Xn
n
(9.3)
e
β =
(t1 − t)X1 + (t2 − t)X2 + ... + (tn − t)Xn
(t1 − t)2 + (t2 − t)2 + ... + (tn − t)2
. (9.4)
O valor de α da equação Xt = α + βt chama-se ordenada na origem, isto é, quando
t = 0, Xt = α, e β representa o declive da recta. Este declive dá a variação verificada
em Xt quando t varia de um período de tempo (constante).
O quadrado do coeficiente de correlação das duas variáveis X e t, r2
(coeficiente de
determinação) dá a percentagem da variação da série original explicada pela tendência
linear. A diferença 100% − r2
% é a variação explicada pelos outros movimentos.
Além da tendência linear, descrita por um polinómio linear, existem outros tipos, tais
como: tendências quadráticas (polinómio quadrático), tendências cúbicas (polinómio cú-
bico), exponenciais, etc.
Exemplo 9.1.1 Considere a seguinte tabela de valores [2]:
Ano t X desvios:X − Xt
1973 1 233 41.258
1974 2 250.3 39.884
1975 3 158 -71.09
1976 4 178.3 -69.464
1977 5 293.5 27.062
1978 6 309.5 24.388
1979 7 279 -24.786
1980 8 355.2 32.74
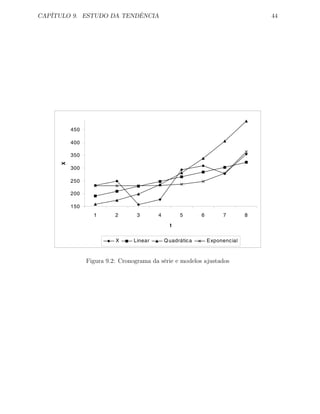
O cronograma está representado na figura 9.2.
No ajuste de uma tendência linear, usando as equações (9.3), (9.4), (9.2) e finalmente
(9.1), obtêm-se
Xt = 173.068 + 18.674 t.
A representação desta recta está na figura 9.2. A interpretação é a seguinte - A partir
de uma valor de 173.068 verificado para t = 0 (1972), a tendência (Xt) aumenta (β > 0),
em média, por ano (ver 1a
coluna da tabela) 18.67.
Se calcularmos o coeficiente de determinação, r2
, teremos r2
= 0.475, ou seja, 47.5%
da variação da série original é explicada pela tendência, ficando 52.5% à conta dos outros](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-50-320.jpg)
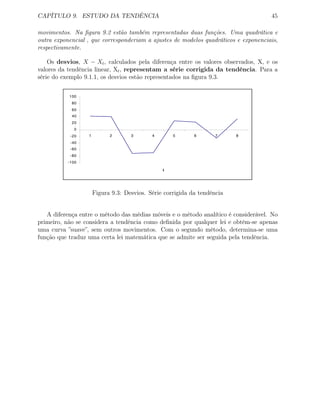
![Capítulo 10
Movimento sazonal
Os movimentos sazonais são variações que ocorrem dentro de um ano e de acordo com
um certo modelo (mais ou menos rígido) que se repete de ano para ano.
São todos os movimentos periódicos de período igual ou inferior a um ano.
Exemplo 10.0.2 Sazonalidade de casamentos[1] (índices)
Paróquias
Mês Sul do Pico Transmontanas Guimarães
Jan 122 126 117
Fev 164 172 160
Mar 29 91 64
Abr 52 111 118
Mai 140 131 127
Jun 105 98 111
Jul 73 64 64
Ago 69 68 76
Set 93 83 78
Out 154 75 96
Nov 161 78 110
Dez 39 104 94
Deste exemplo é visível que a marcação de casamentos, nalgumas regiões, é afectada
por:
• razões sociais: respeito pelas interdições da Quaresma, Advento
• razões económicas: fainas agrícolas, preparação das vinhas (fim de inverno), vindi-
mas, pastagens no verão.
46](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-53-320.jpg)

![CAPÍTULO 10. MOVIMENTO SAZONAL 48
5. Os índices sazonais são calculados como a percentagem da média de cada mês em
relação à média geral.
Nota 10.1.1 A soma dos índices é 1200.
Nota 10.1.2 O nível que traduz ausência de sazonalidade é igual a 100.
Assim, os índices são interpretados da seguinte maneira:
• Um valor menor que 100 indica que nesse mês a flutuação sazonal se traduz numa
quebra em relação ao nível ’normal’ (100);
• Um valor maior que 100 indica um aumento em relação ao nível normal.
Nota 10.1.3 Também existe o método das médias móveis para estudar a sazonalidade [2].](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-55-320.jpg)






![CAPÍTULO 11. ESTRUTURAS POPULACIONAIS 56
Figura 11.2: Exemplo de pirâmide de idade [1]](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-63-320.jpg)
![CAPÍTULO 11. ESTRUTURAS POPULACIONAIS 57
Figura 11.3: Exemplo de pirâmide de idade [1]](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-64-320.jpg)








![CAPÍTULO 13. ANÁLISE DA MORTALIDADE 66
Exemplo 13.1.1 [3] Completar e
Grupos de idades total de óbitos população tx × 1000 Px Pxtx
1 1848 46514 39,73 0,0326 1,30
1-4 1087 184916 5,88 0,1295 0,76
5-9 318 215461 1,48 0,1509 0,22
10-14 171 173563 0,99 0,1215 0,12
15-19 198 145227 1,36 0,1017 0,14
20-24 197 125339 1,57 0,0878 0,14
25-29 185 101699
30-34 182 82518
35-39 200 73395
40-44 247 60945
45-49 251 53330
50-54 346 46561
55-59 398 37816
60-64 483 27889
65-69 502 20397
70+ 2463 32502
Total 9076 1428082 1,0000 6,37
• calcular a taxa bruta de mortalidade (geral);
• calcular a taxa bruta de mortalidade como resultante da interacção entre modelo e
estrutura.
Por este processo ficam visíveis os factores intervenientes - o modelo e as estruturas.
Quando surgem diferenças nos valores da t.b.m., elas podem vir dos tx (modelos) ou
dos Px (estruturas) e têm significados diferentes:
• Variações entre modelos (tx) significam a existência de diferentes riscos de mortali-
dade (diferenças nas condições gerais de saúde e higiene);
• Variações entre estruturas (Px; maior ou menor envelhecimento) são alheias ao fenó-
meno em análise.
As taxas brutas são muito sensíveis aos efeitos da estrutura. Basta as proporções da
população serem diferentes nos grupos em que a mortalidade é mais intensa para termos
importantes efeitos de estrutura que nos impossibilitam a comparação entre países, regiões
ou épocas.
A validade de uma análise feita através das taxas brutas é tanto menor quanto mais di-
versificadas forem as estruturas das regiões ou épocas que se querem comparar. A validade
aumenta com a homogeneização das estruturas populacionais.](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-73-320.jpg)


![CAPÍTULO 13. ANÁLISE DA MORTALIDADE 69
365 dias). O total de óbitos endógenos é então a diferença entre o total dos óbitos
registados e os óbitos exógenos calculados.
A taxa de mortalidade infantil clássica é igual à taxa de mortalidade endógena
(t.m.end.) mais a taxa de mortalidade exógena (t.m.exo.) sendo
t.m.end.=
total de óbitos endógenos
total de nascimentos do ano
× 1000
t.m.exo.=
total de óbitos exógenos
total de nascimentos do ano
× 1000.
13.3 Tábua de mortalidade
É possível fazer uma análise da mortalidade de uma população calculando outros índices.
O princípio da estandardização [3], que separa o impacte das estruturas do das frequências
(modelos), tem como objectivo manter o efeito das estruturas constante, calculando os
índices comparativos. Não é contudo o método mais usado.
É comum usar o princípio da translação. Com este princípio procura-se estimar a inten-
sidade e o calendário a partir das frequências calculadas em transversal. Aplica-se, assim,
o método da coorte fictícia que consiste em transpôr os fenómenos que se observam num
determinado momento do tempo, para uma coorte imaginária. No caso da mortalidade, a
intensidade mede o número médio de acontecimentos por pessoa e o calendário mede a
sua repartição no tempo. O calendário, ao ser resumido pelo índice da tendência central,
a média, dá-nos a possibilidade de conhecer a duração de vida média das pessoas.
No cômputo dos efectivos de uma população podem surgir efectivos de idade ignorada.
Havendo um número significativo de pessoas de idade ignorada, pode usar-se um critério
de repartição dessas pessoas. Calcula-se o factor (Coale e Demeny) de correcção:
população total
população total - população de idade desconhecida
e os efectivos de cada idade (ou grupo de idades) são multiplicados por este factor.
Existem tábuas de mortalidade por idades que se chamam completas, e tábuas de
mortalidade por grupos de idades, chamadas tábuas abreviadas.
Nota 13.3.1 No caso da tábua de mortalidade abreviada, as diversas funções são calcu-
ladas por grupos de idades quinquenais (n=5), excepto no primeiro grupo, que devido à
importância da mortalidade infantil, se divide em dois grupos:
• menos de 1 ano (n=1)
• 1-4 anos completos (n=4).
As diversas funções que integram uma tábua de mortalidade são:](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-76-320.jpg)

![CAPÍTULO 13. ANÁLISE DA MORTALIDADE 71
sx+n = sx npx
ou
sx+n = sx(1 −n qx) = sx − sx nqx
5. Distribuição dos óbitos (tendo em conta o efectivo inicial de 100000) por idades
ou grupos de idade
ndx = sx − sx+n
ou
ndx = sx nqx
6. Número de anos vividos pelos sobreviventes sx entre as idades x e x + n:
[O número de anos vividos obtém-se multiplicando a média dos efectivos entre idades
exactas pelo número de anos]
(a) numa tábua de mortalidade completa
Nx =
1
2
(sx + sx+1)
(b) numa tábua de mortalidade abreviada
nNx =
n
2
(sx + sx+n)
Nota 13.3.4 Devido à não linearidade da função de sobrevivência nos primeiros
anos de vida, é mais conveniente (aproximação mais exacta) usar:
1N0 = k s0 + k s1
4N1 = 4 k s1 + k s5
em que k e k são os coeficientes de ponderação usados no cálculo da mortalidade
infantil (pelo método das médias ponderadas), em 13.2.
Nota 13.3.5 Para o último grupo (70 e + anos) tem-se:
Nk+ = Tk ↔ N70+ = T70+ (ver nota 13.3.8)
7. Probabilidade de sobrevivência entre dois anos completos ou entre dois grupos
de anos completos:](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-78-320.jpg)






![CAPÍTULO 14. ANÁLISE DA NATALIDADE E DA FECUNDIDADE 78
C urvas de proporções de m ulheres casadas e
fecundidade
0
50
100
15-19 20-24 25-29 30-34 35-39 40-44 45-49
Casadas Fecundidade
Figura 14.1: Gráfico das curvas
Grupo de taxa de ajuste a proporção ajuste a
idades fecundidade 100 de mulheres 100
geral casadas
15-19 0.02197 12 0.0406 5
20-24 0.16807 93 0.4739 55
25-29 0.18008 100 0.7891 92
30-34 0.10730 60 0.8511 100
35-39 0.05341 30 0.8550 100
40-44 0.01880 10 0.8359 98
45-49 0.00119 1 0.7973 90
Figura 14.2: Tabela das taxas de fecundidade geral [3]](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-85-320.jpg)




















![Bibliografia
[1] M. N. Amorim. Evolução Demográfica de 3 Paróquias no Sul do Pico 1680-1980, vo-
lume 35. ICS, U.M., 1992.
[2] B. J. F. Murteira e G. H. J. Black. Estatística Descritiva. Editora McGraw-Hill, 1983.
[3] J. M. Nazareth. Princípios e Métodos de Análise da Demografia Portuguesa. Editorial
Presença, 1988.
108](https://image.slidesharecdn.com/estatstica-140426191031-phpapp02/85/Estatistica-115-320.jpg)

Este documento apresenta um manual de estatística dividido em quatro partes. A primeira parte introduz conceitos básicos de estatística descritiva como descrição numérica e gráfica de dados, medidas de tendência central, dispersão e associação. A segunda parte aborda séries cronológicas, tendência e sazonalidade. A terceira parte trata de estatística demográfica e análise de variáveis como mortalidade, natalidade e nupcialidade. A quarta parte apresenta exercícios práticos.











































































































