A seção apresenta o conceito, evolução e objetivos da econometria. A econometria surgiu para estabelecer relações quantitativas entre variáveis econômicas, fundamentando teorias econômicas com dados. Seu objetivo é medir fenômenos econômicos e testar hipóteses, utilizando matemática, estatística e teoria econômica.
















![Conceitos introdutórios e especificação de modelos econométrico
U1
15
Esta foi, então, a primeira ideia de como nasceu a econometria. Porém, ela voltou-
se para a aplicação econômica de seus métodos, logo ela pode ser definida como:
Hill (2010) argumenta que a econometria se utiliza de Teoria Econômica e de
Dados da economia, negócios e ciências sociais e estatística para responder a
questões do tipo quanto. Assim, questões tais como: quanto crescerão as vendas
de uma empresa, qual o impacto dos gastos com publicidade na eleição de um
vereador, qual o incremento de renda necessário para elevar o consumo médio
de carne de primeira etc. Então, a econometria permite prever quanto, por isto
também pode ser utilizada para previsão. Agora, vamos ver um pouco sobre a
evolução da econometria.
Em sua turma, qual a é idade média dos estudantes?
Econometria é a ciência que lida com a determinação,
por métodos estatísticos, das leis quantitativas concretas
que ocorrem na vida econômica [...] está ligada à teoria
econômica e à estatística econômica e tenta por métodos
matemáticos e estatísticos dar expressão concreta e
quantitativa às leis gerais e esquemáticas estabelecidas pela
teoria econômica (LANGE, 1961, p. 13-14).
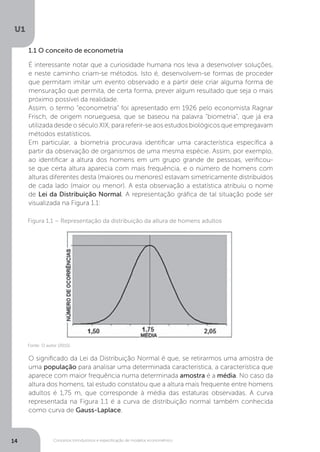
Para entender o que é distribuição normal, é necessário, primeiramente,
definir evento aleatório. Trata-se de um evento cuja ocorrência
individual não obedece a regras ou padrões que permitam fazer
previsões acertadas, como, por exemplo, qual face de um dado lançado
cairá para cima. Muitos dos conjuntos de eventos aleatórios apresentam
padrões que não são identificáveis em cada evento isoladamente,
mas verifica-se a tendência de os eventos se concentrarem próximos
a uma posição que representa uma média matemática deles. Assim, a
quantidade de eventos diminui constante e gradativamente à medida
que nos afastamos da média.](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-17-320.jpg)




![Conceitos introdutórios e especificação de modelos econométrico
U1
20
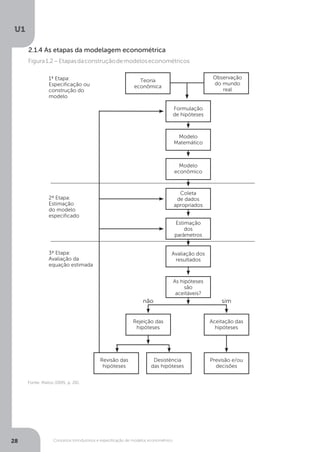
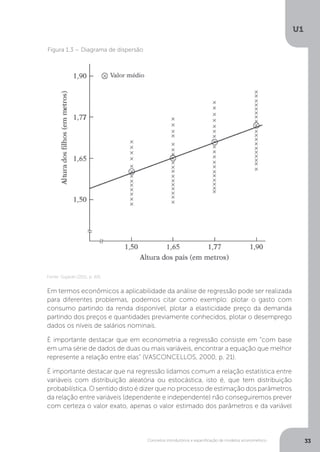
Uma das formas tradicionais de estudo da Econometria Aplicada na Economia é a
análise de regressão. A análise de regressão pressupõe a existência de, no mínimo,
duas variáveis: uma variável dependente/explicada (por exemplo Y) e uma variável
independente/explicativa (por exemplo X). Um exemplo disto é a Lei da demanda,
na qual dizemos que a quantidade demanda (que podemos associar a letra Y) de-
pende inversamente do preço (que podemos associar a letra X).
Assim, enquanto na regressão, procuramos um valor para Y tomando por base
um conjunto de informações fornecido pelas características X, isto é (E[Y|X]), na
análise verificamos se a relação causal entre uma variável econômica a ser explica-
da (variável dependente = Y) e uma ou mais variáveis independentes ou explicativas
(X) são válidas ou necessitam de mais aprofundamentos.
Na análise de regressão quando temos uma única variável independente ou ex-
plicativa, nós temos uma regressão simples e, quando temos mais de uma, o que
é muito comum nos estudos econométricos, temos a regressão múltipla. Mais à
frente veremos maiores detalhes destas duas formas de regressão.
Em toda a análise de regressão também se inclui o termo erro. Este termo tem por
objetivo ser a variável de ajuste de uma regressão que permite equilibrar a exatidão
das análises quantitativas com a inexatidão dos fatos econômicos de acordo com
a teoria econômica. Assim, o termo erro (aleatório) deve ser incluído na relação
exata postulada pela teoria econômica e economia matemática, a fim de torná-
las probabilísticas (isto é, a fim de refletir o fato que, no mundo real, as relações
econômicas entre as variáveis econômicas são inexatas, e algumas vezes erráticas).
1. Explique a ligação entre amostra, frequência e média.
2. Explique a diferença entre a econometria teórica e a
aplicada.](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-22-320.jpg)





















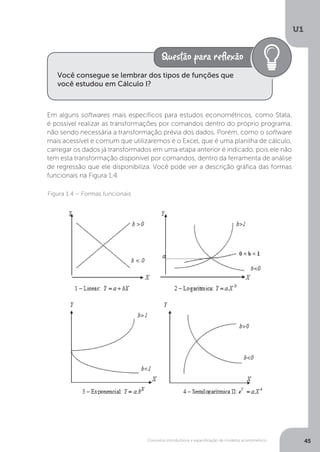
![Conceitos introdutórios e especificação de modelos econométrico
U1
47
A função exponencial é utilizada para descrever processos de crescimento de
uma variável no tempo, de tal forma que:
A função semilogarítmica II é utilizada quando estamos mensurando um efeito
sobre uma variável dependente na qual os acréscimos na variável independente
fazem a variável dependente crescer a taxas positivas, porém declinantes na medida
em que a variável independente aumenta. Exemplo econômico é o efeito Engel.
elasticidade constante. De modo geral, o uso de tal
função é adequado toda vez que uma variável cresce
com o aumento de outra, porém a taxas decrescentes
ou crescentes. Serviria, então, para captar o efeito Engel
da renda disponível sobre o consumo (crescimento a
taxas decrescentes) ou sobre a poupança (crescimento
a taxas crescentes) (MATOS, 1995, p. 32).
Particularmente, tem-se que LnY Lna Lnb.t, a
taxa de crescimento, g = (antiln b - 1) x 100. Pode-se
igualmente aplicar tal função quando uma variável
cresce (ou decresce) com os acréscimos de outra,
porém a taxas crescentes (decrescentes). [...] A restrição
é que a variável dependente assuma somente valores
positivos (MATOS, 1995, p. 34).
O efeito Engel pode ser aplicado sobre o consumo individual. Isto
implica que as taxas de variação das despesas individuais de consumo
de um dado bem são positivas, mas declinam com os acréscimos de
renda.](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-49-320.jpg)














![Modelo linear geral e inclusão de variáveis especiais
U2
62
à maneira pela qual os parâmetros e as perturbações entram na equação, não
necessariamente à relação entre as variáveis. Então, afirma-se que a relação de
linearidade deve ser entre os parâmetros e não necessariamente entre as variáveis.
2 – Rank ou posto Completo: Não pode haver relacionamento linear perfeito entre
as variáveis independentes; o número de observações tem de ser no mínimo tão
grande quanto o número de parâmetros; as variáveis independentes têm de variar.
3 – Exogeneidade das variáveis independentes: E [εi | xj1, xj2. . . ,xjK ]= 0. Indica que o
valor esperado do termo erro εi da amostra não é uma função de qualquer uma das
variáveis independentes observadas. Isso significa que as variáveis independentes
não carregam informações úteis, ou que tenham peso, para a previsão de εi.
4 – Homocedasticidade e não autocorrelação: cada perturbação, εi tem a mesma
finita variância σ2, e é não correlacionado com todos os outros distúrbios, εj. Esta
suposição limita a generalidade do modelo.
5 – Exogeneidade na geração de dados: os dados no (xj1, xj2,..., XjK) podem ser
uma mistura de variáveis constantes e aleatórias. O processo de geração dos dados
opera externamente às suposições do modelo, isto é, independentemente do
processo que gera εi. Nota-se que isso amplia A3. A análise é feita condicionalmente
ao X observado.
6 – Distribuição normal: os resíduos são normalmente distribuídos: o modelo de
regressão linear, com todos os seus pressupostos, é a plataforma básica para a
construção de modelos em econometria.
De maneira similiar, porém um pouco mais sintética em termos de representação
simbólica, Matos (1995, p. 42-43) expressa que:
Esses pressupostos são os seguintes:
Aleatoriedade de ui
– A variável ui
é real e aleatória
ou randômica.
Média zero de ui
– A variável ui
tem média zero, isto
é, E(ui
)=0.
Homoscedasticidade – ui
tem variância constante,
ou seja, var(ui
)=E(ui
^2 )= σ^2,ondeσ=constante.
A variável u_i tem distribuição normal, isto é, ui
~
N(0,σ^2 ).](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-64-320.jpg)

![Modelo linear geral e inclusão de variáveis especiais
U2
64
mínimos quadrados. Mas é possível construir um estimador consistente de β
usando as relações assumidas entre zi, xi, e εi.
E no final o autor reconhece e elenca uma série de dados amostrais que dado as
suas particularidades não teriam no MMQ um melhor método de estimação para
seus parâmetros, tais como:
A) Painel de dados – examinando um modelo para despesas municipais na forma Sit
= f (Sit-1,...) + εi. Os distúrbios são assumidos para serem livremente correlacionados
entre períodos, então ambos Si,t-1 e εi,t, são correlacionados com εi,t-1. Segue que
eles estão correlacionados uns com os outros, o que significa que este modelo,
mesmo com uma especificação linear, não satisfaz os pressupostos do modelo
clássico. Os regressores e perturbações estão correlacionados.
B) Regressão Dinâmica – examinando uma variedade de modelos de séries de
tempo que sejam da forma yt = f(yt-1,...) + εt em que εt é autocorrelacionado
com os seus valores passados. Este processo é essencialmente o mesmo que
foi considerado anteriormente. Desde que os distúrbios são autocorrelacionados,
segue-se que a regressão dinâmica implica a correlação entre a perturbação e uma
variável do lado direito. Mais uma vez, os mínimos quadrados serão inconsistentes.
C) Função Consumo – Por construção, o modelo viola os pressupostos do modelo
clássico de regressão. A função renda nacional Y = C + investimento + gastos
governamentais + exportações líquidas. Embora ocorra uma relação exata entre
C de consumo, renda e Y, C = f (Y, ε), é ambíguo e é um candidato apropriado
para a modelagem, é evidente que o consumo (e, portanto, ε) é um dos principais
determinantes da Y. O modelo Ct = α + βYt + εt não se encaixa nas premissas
para o modelo clássico se Cov [Yt, εt] ≠ 0. Mas é razoável assumir (pelo menos por
agora) que εt é não correlacionado com os valores passados de C e Y. Assim, nesse
modelo, é possível considerar Yt-1 e CT-1, como variáveis instrumentais adequadas.
1.2.3 Os estimadores MQO são BLUE
Geralmente, os parâmetros estimados, através do MQO, são chamados melhores
estimadores lineares não tendenciosos dentro da classe dos estimadores possíveis,
também chamados BLUE. Wooldridge (2011) aborda o Teorema de Gauss-
Markov, que justifica o uso do método de MQO em vez de usar uma variedade de
estimadores concorrentes. Sob as hipóteses 1 a 5, o estimador de MQO bj para βj é
o melhor estimador linear não viesado (Best Linear Unbiased Estimator – BLUE). A
fim de formular o teorema, o autor diz que é preciso entender cada componente
da sigla “BLUE”.](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-66-320.jpg)
![Modelo linear geral e inclusão de variáveis especiais
U2
65
Assim destaca-se que um estimador se define como uma regra que pode ser
aplicada a qualquer amostra de dados para produzir uma estimativa. O termo
não viesado refere-se a um estimador, por exemplo bj, de βj
é um estimador não
viesado de βj
se E(bj
) = βj
para qualquer β0
, β1
..., βk
cuja dedução matemática,
conforme demonstrou Greene (2003), é dado como:
b = (X’X)-1 X’y
b = (X’X)-1 X’(Xβ + ε)
b = (X’X)-1 X’Xβ + (X’X)-1 X’ε
b = β + (X’X)-1 X’ε
E[b|X] = β + E[(X’X)-1 X’ε]
Assim, para qualquer conjunto de observações, o estimador de mínimos quadrados
tem esperança β. Além disso, através da média de b dos possíveis valores de X,
obtém-se a média incondicional de b que também é β.
Quanto ao termo linear refere-se a um estimador bj de βj é linear se, e somente se,
ele puder ser expresso como uma função linear dos dados da variável dependente.
E o significado de melhor para o teorema corrente, o melhor é definido como a
variância menor. Dados dois estimadores não viesados, deve-se preferir aquele
com a variância menor conforme demonstração matemática de Greene (2003),
que requer conhecimento de matrizes:
Seja b0
=Cy com C uma matriz k x n e b0
outro estimador linear não viesado de β.
Então, E[Cy | X] = E[(CXβ + Cε)|X] = β
Com y = Xβ + εeCX = I
Então existem muitos candidatos.
Por exemplo, as primeiras k linhas de X. Então,
C = [X0
-1
:0], em que X0
-1
é a inversa das k primeiras linhas de X.
A matriz de covariância pode ser obtida,
Var[b0
|X] = σ2
CC’, ou seja,](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-67-320.jpg)
![Modelo linear geral e inclusão de variáveis especiais
U2
66
b0
= Cy = C(Xβ + ε)
= CXβ + Cε b0
= β + Cε b0
– β = Cε
Com isso,
Var[b0
|X] = E[(b0
– β)( b0
– β)’|X] = E[Cεε’C|X]
Var[b0
|X] = σ2
CC’
Agora, seja
D = C – (X’X)-1X’ ouC = D + (X’X)-1X’
Além disso,
Dy = (C – (X’X)-1
X’)y = Cy – (X’X)-1
X’y = b0
– b
Voltando,
Var[b0|X] =σ2
CC’
= σ2
[(D + (X’X)-1X’)( D’ + X(X’X)-1
)]
= σ2
[(DD’ + DX(X’X)-1
+ (X’X)X’D’ + (X’X)-1
X’X(X’X)-1
)]
Mas, como = CX = I CX = DX + (X’X)-1
X’X DX = 0
Portanto,
Var[b0|X] = σ2
[DD’ + (X’X)-1
] = σ2
(X’X)-1
+ σ2
DD’
= var[b0
|X] = σ2
DD’
Então,
var[b0
|X] > var[b0
|X]
Assim, b é o melhor estimador linear não viesado de β, à medida que possui
variância mínima.
Portanto, sob as cinco hipóteses de Gauss-Markov, na classe dos estimadores
lineares não viesados, MQO tem a menor variância. MQO também é, sob as
hipóteses de Gauus-Markov, assintoticamente (para grandes amostras) eficiente
dentro de uma classe de estimadores.
1.3 A estimação do modelo por meio do MQO](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-68-320.jpg)







![Modelo linear geral e inclusão de variáveis especiais
U2
76
Em termos populacionais as variáveis aleatórias se caracterizam pelos momentos da
variável que em si são representados pelas seguintes medidas:
a) Média ou esperança matemática: E(q)
b) Variância: Var(q)=E[q-E(q)]2
=
=E(q2
)-[E(q)]2
c) Erro-padrão:EP(q)=√(Var(q) )
Em termos amostrais, as variáveis aleatórias se caracterizam pelos momentos da
variável que em si são representados pelas seguintes medidas:
a) Erro amostral: q-^
q
b) Tendenciosidade ou viés: E(^
q )-q
c) Erro quadrático médio (EQM): E(^
q -q)2
=Var(^
q )+[viés(^
q )]2
Matos (1995) destaca que: “É importante assinalar que, enquanto a variância mede a
dispersão em torno da média amostral, o erro quadrático médio mede a dispersão
em torno do verdadeiro valor do parâmetro q. Assim, se viés (^
q ) = 0, Var(^
q ) =EQM
(^
q )” (MATOS, 1995, p. 58).
Feitas estas considerações sobre os parâmetros, resta-nos acrescentar as qualidades
desejáveis dos estimadores MQO. Em especial, esta qualidade refere-se à capacidade
de se obter informações fidedignas possíveis sobre o valor do verdadeiro parâmetro, q.
Os momentos são muito importantes em estatística para caracterizar
distribuições de probabilidade. por exemplo, a distribuição normal é
caracterizada apenas pelo primeiro (média) e pelo segundo (variância)
momentos. Os momentos dão uma ideia da tendência central,
dispersão e assimetria de uma distribuição de probabilidades.
Isso significa dizer que o desejável é que a distribuição
dos valores de ^
q , obtidos a partir de amostras repetitivas,
seja o máximo possível concentradas em torno de q. Em
consequência, para se obter tal proximidade máxima,
a estimativa ^
q terá de possuir as qualidades de não
tendenciosidade, eficiência e consistência, que são
definidas a seguir (MATOS, 1995, p. 58).](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-78-320.jpg)

![Modelo linear geral e inclusão de variáveis especiais
U2
78
2.1.3 Consistência
Um estimador é consistente se sua distribuição amostral tender a se concentrar no
verdadeiro valor do parâmetro quando a amostra cresce. Então, uma estimativa ^
q
de q para ser consistente se o limite da probabilidade de ocorrência de ^
q for igual
a q de tal forma que:
Assinale-se que a diferença [E(^
q )-q]2
é o viés, ou seja, a distância entre E(^
q ) e o
verdadeiro valor do parâmetro, q. A representação gráfica da consistência pode ser
visualizada na Figura 2.5.
2.2 Critérios para avaliar as estimativas de um modelo
A segurança que podemos ter em utilizar um modelo econométrico para tomada
de decisão ou previsão deve ser pautada pela qualidade dos resultados obtidos.
Fonte: Adaptado de Matos (1995)
Fonte: Adaptado de Matos (1995)
Figura 2.4 - Eficiência
Figura 2.5 - Consistência](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-80-320.jpg)





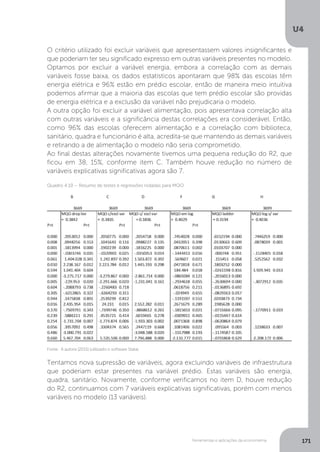
![Modelo linear geral e inclusão de variáveis especiais
U2
84
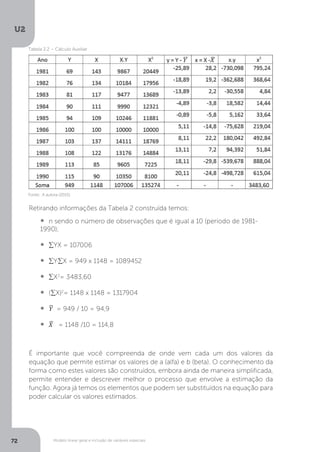
A partir da tabela de análise de variância podemos deduzir os demais elementos
importantes para a composição das estatísticas de avaliação, conforme segue:
Variância amostral: que mede o grau de dispersão entre os valores observados de
Y e o valor estimado (^
Y ). Dada pela fórmula:
Coeficiente de determinação (R2): É um coeficiente utilizado para demonstrar a
qualidade do ajustamento da linha de regressão, ou seja, “descobriremos quão
bem uma linha de regressão amostral é adequada aos dados... o coeficiente de
determinação é uma medida resumida que diz o quanto a linha de regressão
se ajusta aos dados” (GUJARATI, 2005, p. 65). Em termos de fórmulas pode-se
descrevê-lo como:
Quando realizamos a operação 1 – R2 podemos verificar qual parcela da variância
total de Y (VT) não pode ser explicada por X, devido à existência de variáveis
omitidas. Ele é descrito pela fórmula:
Tecnicamente ele mede a relação entre a variação explicada pela equação de
regressão múltipla e a variação total da variável dependente. Assim, R2=0,75
significa que 75% de variância são explicados pelo modelo. O coeficiente de
determinação (R2) é um número no intervalo [0;1], quanto mais próximo de um
melhor o ajuste.
Estatística de F: serve para avaliar o efeito conjunto das variáveis explicativas sobre
a variável dependente, ele é descrito pela fórmula
Fonte: Matos (1995, p. 67)
Tabela 2.4 – Análise de variância simples](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-86-320.jpg)




![Modelo linear geral e inclusão de variáveis especiais
U2
89
Em seguida, realizamos operações envolvendo matrizes a fim de estimar a
equação de demanda de energia elétrica por MQO múltipla. Considerando que
a resolução de matrizes foi estudada na disciplina de Matemática no Ensino
Médio, é importante para a compreensão do raciocínio desenvolvido, revisitar os
fundamentos da resolução de matrizes. Você também estudou um pouco disto na
disciplina de Cálculo/Matemática para Economista.
Inicialmente utilizamos o sistema matricial em pela forma de desvios:
Assim, obtendo a solução deste sistema considerando o raciocínio de que B=(X'
X)-1
∙ X'Y, tal solução possibilita-nos encontrar o valor de beta (B). A fórmula a seguir
permite a obtenção da estimativa do termo constante:
Para definir os elementos constantes do sistema matricial X^' X.B=X'Y procedemos
da seguinte maneira:
Seguindo os passos indicados, o sistema matricial é obtido ao tomar os dados
constantes da Tabela 4, representado por:
Assim, a matriz 2 x 2 é X’ X. Dando continuidade nos procedimentos para resolver
o sistema calcula-se a inversa, (X' X)-1
:
Cálculo do determinante D da matriz X'X
D=3.483,6 ∙854,1- [(-825,6)∙(-825,6)]=2.293.727,4
Cálculo da matriz cofatora C
C=[cij
]=(-1i+j
)∙Dij
Temos que Dij
é o determinante da submatriz que foi obtida depois da supressão
da i-ésima linha e da j-ésima coluna da matriz X'X. Considerando que, X'X é uma
matriz de segunda ordem, ou seja, (2 x 2), o escalar restante é o determinante da
submatriz, obtida após a supressão. Assim, obtemos a matriz cofatora:](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-91-320.jpg)
















![Violação dos pressupostos básicos do modelo
U3
107
foi considerado anteriormente. Desde que os distúrbios são autocorrelacionados,
segue-se que a regressão dinâmica implica a correlação entre a perturbação e uma
variável do lado direito. Mais uma vez, os mínimos quadrados serão inconsistentes.
C) Função Consumo – Por construção, o modelo viola os pressupostos do modelo
clássico de regressão. A função renda nacional Y = C + investimento + gastos
governamentais + exportações líquidas. Embora ocorra uma relação exata entre
C de consumo, renda e Y, C = f (Y, ε), é ambíguo e é um candidato apropriado
para a modelagem, é evidente que o consumo (e, portanto, ε) é um dos principais
determinantes da Y. O modelo Ct = α + βYt
+ εt
não se encaixa nas premissas para
o modelo clássico se Cov [Yt, εt] ≠ 0. Mas é razoável assumir (pelo menos por
agora) que εt é não correlacionado com os valores passados de C e Y. Assim, neste
modelo, é possível considerar Yt-1
e CT-1
, como variáveis instrumentais adequadas.
1. Por que não se pode utilizar o método MQO para estimar
parâmetros gerados por painel de dados?
2. Para a função consumo, qual tipo de variável deve ser
criado para resolução de um modelo?](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-109-320.jpg)



















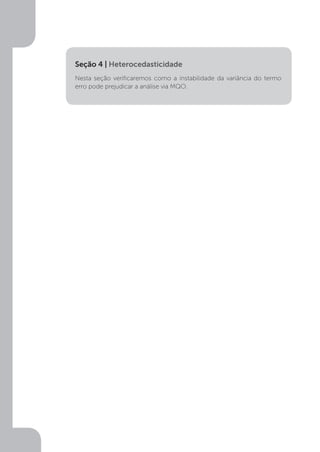
![Violação dos pressupostos básicos do modelo
U3
127
Seção 4
Heterocedasticidade
Introdução à seção
Quando estimamos um modelo, um pressuposto importante do MQO, é que os
erros ou resíduos sejam homocedásticos quando atendem a este pressuposto.
Todos têm variância mínima e constante, se apresentam concentrados próximos
a uma média.
Ocorre que algumas vezes isto não se verifica, então, pode ocorrer uma forte
dispersão dos dados em torno de uma reta; uma dispersão dos dados perante
um modelo econométrico regredido. Nestes casos temos o que se chama em
econometria de heterocedasticidade.
Por outro lado, podemos dizer que a heterocedasticidade não elimina as
propriedades de inexistência de viés e consistência dos estimadores de MQO, mas
sua principal implicação reside no fato de que os erros apresentando variância
elevada, os parâmetros estimados pela regressão de ter eficiência, ou seja, deixam
de ser os melhores estimadores lineares não viesados. Para compreender melhor
o aspecto vamos estudar esta seção.
4.1 Conceito
Em linhas gerais, a heterocedasticidade pode ser descrita como “conceito de
estatística que designa uma distribuição de frequência em que todas as distribuições
condicionadas têm desvios-padrão (afastamentos) diferentes" (SANDRONI, 1989,
p. 280). Isto é, o erro não é homocedástico.
Apenas relembrando que o pressuposto da homocedasticidade pode ser
representado estatisticamente por [E(ei)2
=σ2+
], significa que cada perturbação
tem a mesma variância σ2
cujo valor é desconhecido. Quando as estimativas
contemplam um termo erro homocedástico, isto garante que cada observação
é igualmente confiável e que as estimativas dos coeficientes da regressão são
eficientes, resultando em testes de hipóteses não viesados.](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-129-320.jpg)
![Violação dos pressupostos básicos do modelo
U3
128
Ao contrariar este pressuposto a heterocedasticidade surge de situações para as
quais a variância do termo erro não é constante para todos os valores da variável
independente (Y).Isto é,E(Xi
ei
)≠0; assim [E(ei
)2
≠σ2
]. Desta forma, as principais
consequências da heterocedasticidade é que o MQO não gera estimativas
eficientes ou de variância mínima dos parâmetros, logo os erros-padrões são
viesados e os testes t e F não são confiáveis. A heterocedasticidade é mais comum
em dados de cross-section.
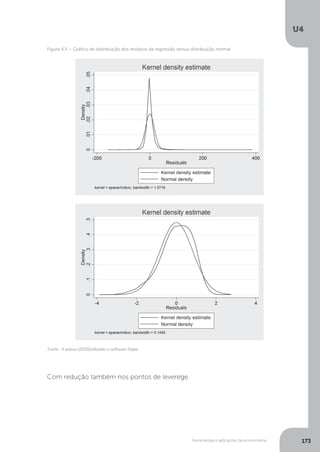
4.2 Identificação da heterocedasticidade
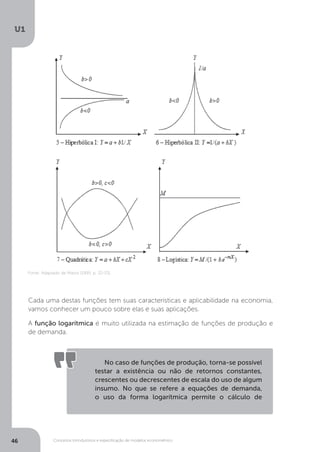
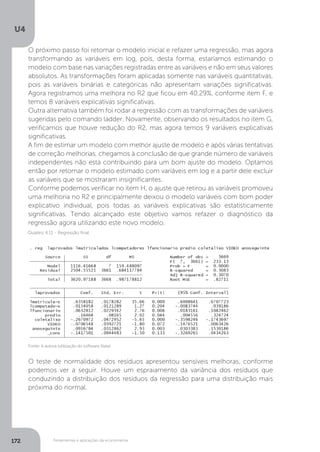
A forma mais simples de constatar a presença da heterocedasticidade é verificar a
plotagem dos termos erros contra cada uma das variáveis explicativas, conforme
podemos ver na Figura 3.3, que compara uma distribuição homocedástica contra
uma heterocedástica.
Esse pressuposto exclui, por exemplo, a possibilidade
de a dispersão das perturbações ser maior para valores
mais altos de Xi. Por exemplo, em uma função de
produção, o pressuposto de Homoscedasticidade implica
que a variação na produção é a mesma, seja a quantidade
de trabalho 20; 100 ou qualquer outro número de
unidades (MATOS, 1995 p. 147).
Fonte: Gujarati (2011, p. 371).
Figura 3.3 – Homecedasticidade versus heterocedasticidade](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-130-320.jpg)

![Violação dos pressupostos básicos do modelo
U3
130
b) Em seguida, realizar as operações de duas regressões separadas, uma
para os menores valores de Xi
e outra para os maiores valores de Xi
, omitindo
aproximadamente ¼ das observações que tenham valores médios. Portanto, as
(n – c) observações restantes são divididas em duas subamostras de tamanhos
iguais, em uma é necessário incluir os valores menores de X e na outra seus valores
mais elevados.
c) Desta maneira, testa-se a razão entre a soma dos quadrados dos erros da
segunda regressão e a soma dos quadrados dos erros da primeira regressão (isto
é, SQE2
/SQE1
) no intuito de verificar se é significativamente diferente de zero.
d) Partindo dessas informações, é definida a seguinte estatística F:
Com esta fórmula, a estatística tem distribuição F com [(n - c)/ 2 - k - 1] graus de
liberdade tanto para o numerador quanto para o denominador.
Adota-se:
n = número total de observações;
c = número e observações omitidas;
k = número de variáveis explicativas incluídas no modelo.
Constata-se que, se as variâncias das duas subamostras forem iguais, F tender a 1 e
a hipótese nula de ausência de heterocedasticidade (H0
) será aceita.
À medida que a diferença entre as duas variâncias se amplia, o problema de
heterocedasticidade vai se agravando.
Assim, dado um nível de significância, pode-se utilizar a estatística F para verificar a
existência ou não do problema de heterocedasticidade.
Naturalmente, se F observado >F crítico para [(n - c)/ 2 - k - 1] graus de liberdade, a
hipótese nula de homocedasticidade será rejeitada.
Ao trabalhar com grandes amostras, o teste de Goldfeld-Quandt é considerado
o mais indicado, de maneira que seja possível estimar adequadamente as duas
regressões adequadamente.
Em relação à validade, teste de Goldfeld-Quandt requer a normalidade dos resíduos
e a ausência de autocorrelação serial.](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-132-320.jpg)
![Violação dos pressupostos básicos do modelo
U3
131
2) Teste de Glejser
Este teste caracteriza-se em estimar a equação de regressão do valor absoluto
dos resíduos ei sobre a variável explicativa, relacionada aos resíduos, depois
da escolha da forma especificativa considera mais adequada. Apesar disto, a
heterocedasticidade se refira à existência de uma relação entre a variância dos
resíduos [var(ei)] e uma ou mais variáveis explicativas (X), a estimação sugerida por
Glejser faz sentido, porque a magnitude de ei em valores absolutos varia (aumenta
ou diminui), quando sua variância não for constante.
Desta forma, temos:
|e|= a + bXc
+ v, onde c = -2; -1; -0,5; 0,5; 1 ou 2
Aheterocedasticidadeé,portanto,avaliadaemfunçãodasestatísticasconvencionais
de análise de regressão (t, F e R2
), rejeitando-se a hipótese nula de ausência de
heterocedasticidade, se os parâmetros estimados forem estatisticamente iguais
a zero, para dado nível de significância. Utiliza-se então a estatística F para a
realização do teste.
Em uma situação quando apenas a estimativa do parâmetro b for diferente de zero,
tem-se heterocedasticidade pura e, desse modo, é plausível admitir que var(ei
) =
σ2
X2c
. Logo, o desvio-padrão será proporcional a Xc
e, em consequência, utiliza-
se Xc como fator de ponderação ou correção da equação original. Se tanto a
estimativa de a quanto a de b forem diferentes de zero, então a heterocedasticidade
será mista e o fator de correção mais apropriado seria o uso da estimativa da (a +
bXc), tornando assim, a correção muito mais complexa e problemática.
Salienta-se, pelo procedimento de Glejser, o fator de correção (Xc
) depende da
forma especificativa que, mais apropriadamente, ajuste |e| a Xc
ou da escolha
arbitrária de uma delas.
3) Teste de Park
Para este teste procede uma especificação que utiliza a relação e2=aXc. Sendo
assim, o teste de homocedasticidade consiste em regredir o quadrado dos
resíduos, e2
, sobre o X, usando-se a forma funcional logarítmica. Assim, desta
maneira, admitindo-se um resíduo aditivo u, a equação a ser estimada apresentada
a seguir será:
Ln e2
=Ln a + cLn X + u
Entretanto, tal forma especificativa não é aplicável no caso de a variável explicativa,
a priori relacionada a e2
, assumir valores negativos ou nulos. Para esta situação,
temos o caso da variável binária.](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-133-320.jpg)




















![Ferramentas e aplicações da econometria
U4
154
H1
:b1
≠ b2
≠ 0 (presença de efeito)
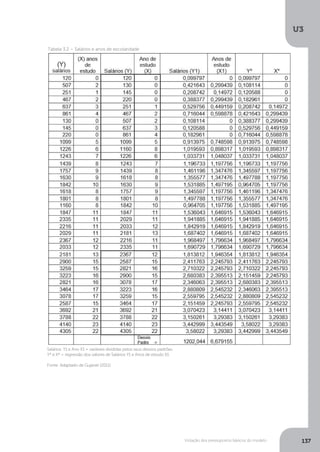
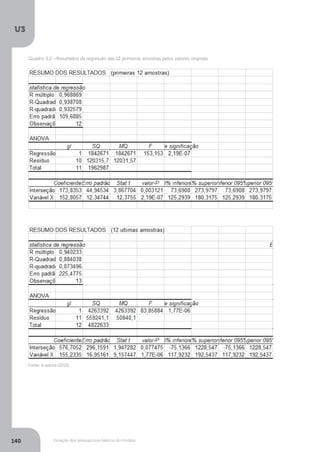
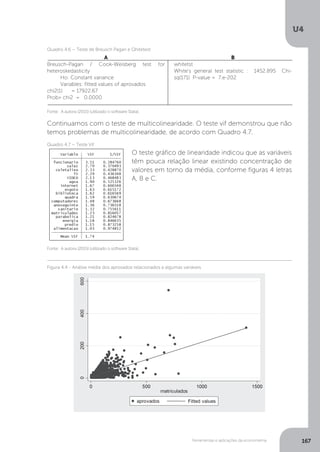
Como Fcalc>Ftab (184,7 > 7,82), rejeita-se a hipótese de efeito nulo das variáveis
explicativas. Isto significa que as variáveis crescimento do PIB e tarifa real média
afetam a quantidade demandada de energia elétrica.
Para o segundo momento, temos:
Y = a + b1
X1
+ b2
X2
+b3
X3
+ ui
Y = 189,73 + 0,31 X1
–1,15 X2
+ 29,56X3
R2
= 0,96
(5,33) (-6,50) (3,50) F = 184,7 n = 27
Com relação aos valores estimados dos parâmetros estimados temos a acrescentar que:
• Todos os parâmetros se mostraram significativos num teste de t, pois o t
23/5% = 2,069 e todos os parâmetros apresentaram valores superiores;
• O coeficiente de determinação (R2
) é significativo;
• O teste de F confirma que as variáveis em seu conjunto exercem
significativa influência no modelo.
Quando comparamos os resultados encontrados com uma amostra maior do que
a do estudo de Matos (1995), com relação à variável dummy, o autor adverte que:
Então observamos que a variável dummy não é significativa numa amostra pequena
nem aumentando o tamanho da amostra, este fato pode ser explicado por dois
motivos, em primeiro lugar porque o crescimento do PIB pode estar aumentando o
consumo rapidamente, outro seria o fato da geração de energia ser menor do que
o necessário para suprir o aumento da demanda.
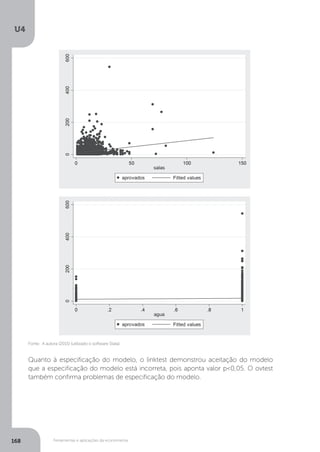
Mas também Mattos adverte para o fato de que podem ocorrer problemas de
multicolinearidade entre as variáveis e entre as variáveis explicativas. Para averiguar
tal situação, procedemos aos testes de multicolinearidade.
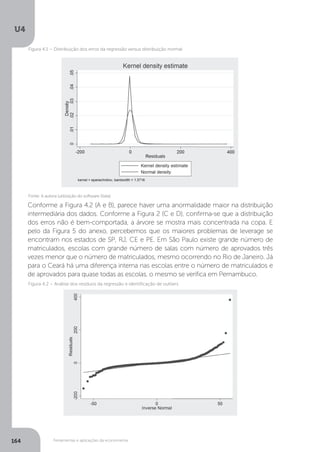
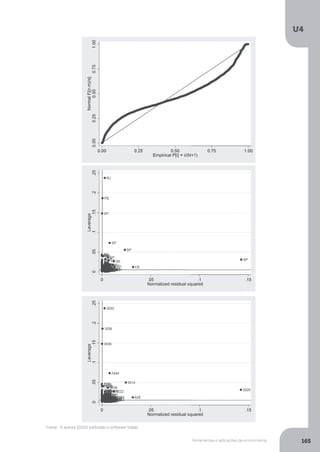
Com relação ao efeito individual, registre-se, porém que
a hipótese nula de ausência de efeito é somente rejeitada
no caso das variáveis tarifa real e produto interno bruto, o
que ocorre ao nível de significância de 5%, [...], já o impacto
relativo ao horário de verão, indicado pela dummy, apesar de
negativo como esperado, não se mostrou estatisticamente
significativa, isto implica que a variável não contribui para
explicar o modelo e pode ser excluída, [...], mas as estatísticas
t e F podem alterar-se (MATTOS, 1995, p. 121).](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-156-320.jpg)



![Ferramentas e aplicações da econometria
U4
158
Nesse sentido, mais do que uma "nova escola", voltada
a um novo público, antes não atendido pela escola básica
insuficiente, a educação supletiva converteu-se também em
mecanismo de "aceleração de estudos" para adolescentes
e jovens com baixo desempenho na escola regular [...] a
suplência passou a constituir-se em oportunidade educativa
para um largo segmento da população, com três trajetórias
escolares básicas: para os que iniciam a escolaridade já
na condição de adultos trabalhadores; para adolescentes
e adultos jovens que ingressaram na escola regular e a
abandonaram há algum tempo, frequentemente motivados
pelo ingresso no trabalho ou em razão de movimentos
migratórios e, finalmente, para adolescentes que ingressaram
e cursaram recentemente a escola regular, mas acumularam
aí grandes defasagens entre a idade e a série cursada (DI
PIERRO et al., 2001, p. 5-8).
Di Pierro et al. (2001) advertem que a escassez de recursos para modalidade Ensino
de Jovens e Adultos (EJA) foi contornada pelos municípios de duas maneiras
distintas: ampliação das salas de correção de fluxo e parcerias com organizações
sociais e voluntários, como, por exemplo, o Movimento de Alfabetização (MOVA).
O principal problema advindo destas alternativas resume-se “a descaracterização
da educação de jovens e adultos como modalidade que requer norma própria,
projeto político-pedagógico específico e adequada formação de educadores” (DI
PIERRO, 2001, p. 118).
Outro aspecto importante é que O EJA
tem necessidades especiais a serem
atendidas, pois seu público alvo são
pessoas com 15 anos ou mais e que
na maioria já ingressou no mercado de
trabalho, fato que a nova Lei de Diretrizes
e Bases (LDB) reconhece, pois destaca
que os cursos e os exames devem
proporcionar oportunidades de ensino
apropriadas às condições de vida e
trabalho dos jovens e adultos.
Diante destes aspectos, o presente artigo
visa explorar e descrever um panorama
geral do EJA no Brasil tomando por base
os dados gerados pelo Instituto Nacional
de Estudos e Pesquisas Educacionais Fonte: Shutterstock (2015).](https://image.slidesharecdn.com/econometria-220327170810/85/ECONOMETRIA-pdf-160-320.jpg)































































![Introdução a econometria [modo de compatibilidade]](https://cdn.slidesharecdn.com/ss_thumbnails/introduoaeconometriamododecompatibilidade-131212142929-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
















