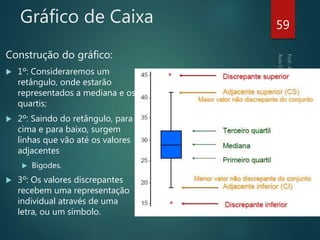
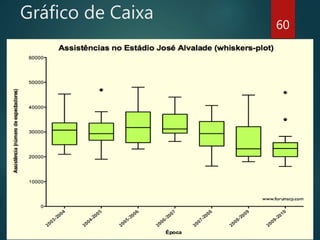
Baixado 40 vezes




















































![ Formato mais objetivo: Utilização das medidas “Cerca Inferior”
e “Cerca Superior”.
CERCA INFERIOR
𝐶𝐼 = 𝑄1 − 1,5𝑎 𝑞
CERCA SUPERIOR
𝐶𝑆 = 𝑄3 + 1,5𝑎 𝑞
Serão considerados discrepantes os valores que estiverem fora
do seguinte intervalo:
[𝐶𝐼; 𝐶𝑆]
Valores menores que a CI são considerados discrepantes
inferiores, e os maiores que a CS são considerados discrepantes
superiores.
56
Identificação de valores
discrepantes](https://image.slidesharecdn.com/prob-160519185100/85/Probabilidade-e-Estatistica-Aula-03-56-320.jpg)











O documento descreve medidas estatísticas descritivas utilizadas para resumir e analisar conjuntos de dados numéricos. Ele discute medidas de localização como média, mediana e moda, que indicam tendências centrais nos dados. Também cobre medidas separatrizes como quartis, que dividem os dados em porcentagens. Por fim, aborda medidas de dispersão como amplitude e variância, que quantificam a variabilidade dos dados em relação à média ou mediana.













































![XVII SAMET -2ª feira - Mini-curso [Dra. Simone Ferraz]](https://cdn.slidesharecdn.com/ss_thumbnails/xviisametdra-simoneferraz-101202183744-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









































