Transferir como PDF, PPTX



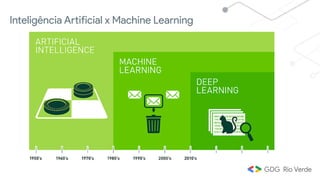
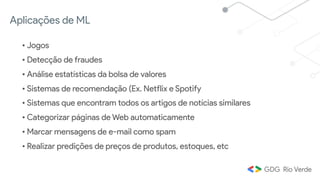





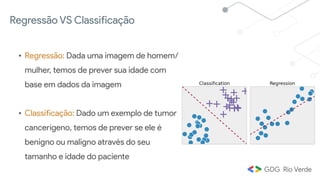

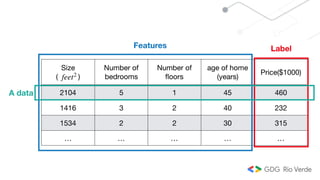
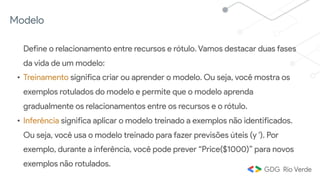

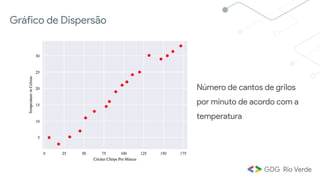

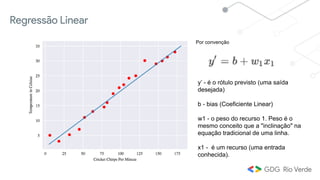





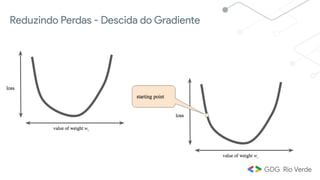
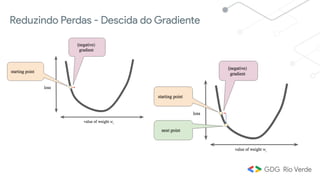
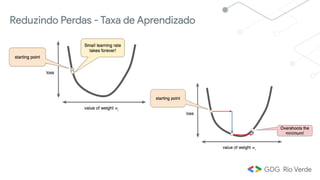
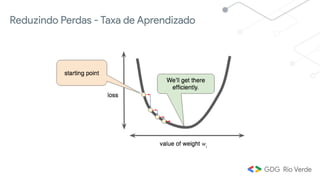




Este documento apresenta uma introdução ao aprendizado de máquina, definindo o conceito, distinguindo-o de inteligência artificial e apresentando alguns tipos e aplicações. Explica os conceitos de aprendizado supervisionado, não-supervisionado e por reforço, além de apresentar exemplos de regressão e classificação no aprendizado supervisionado.







































![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BuildWithAI] Introduction to Gemini.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/buildwithaiintroductiontogemini-240507191145-3c85d2d0-thumbnail.jpg?width=640&height=640&fit=bounds)






