O documento discute conceitos básicos de aprendizagem de máquina, incluindo tipos de aprendizado supervisionado e não supervisionado e exemplos de algoritmos e aplicações.
Concept
Machine Learning (Aprendizadode Máquina) é uma área de
IA cujo objetivo é o desenvolvimento de técnicas
computacionais sobre o aprendizado bem como a construção
de sistemas capazes de adquirir conhecimento de forma
automática.
Um sistema de aprendizado é um programa de computador
que toma decisões baseado em experiências acumuladas
através da solução bem sucedida de problemas anteriores.
4.
Definição
É a áreade estudo que dá aos computadores a capacidade de
aprender sem serem explicitamente programados.
Diz-se que é um problema de Machine Learning quando:
Um programa de computador (P) aprende a partir da experiência
(E) na realização de uma determinada tarefa (T) e com uma
determinada medida de performance (Pe).
Se sua Pe aumenta na realização de T, aumenta E.
5.
A inferência indutiva
Aindução é a forma de inferência lógica que permite obter conclusões genéricas sobre um conjunto particular de
exemplos.
Na indução, um conceito é aprendido efetuando-se inferência indutiva sobre os exemplos apresentados.
Portanto, as hipóteses geradas através da inferência indutiva podem ou não preservar a verdade.
Arquimedes KeplerDarwin
6.
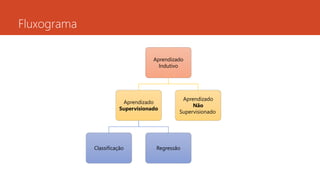
Formas de AprendizadoIndutivo
• SUPERVISIONADO
No aprendizado supervisionado é fornecido ao algoritmo de aprendizado, ou indutor, um conjunto de
exemplos de treinamento para os quais o rótulo da classe associada é conhecido.
• NÃO SUPERVISIONADO
No aprendizado não-supervisionado, o indutor analisa os exemplos fornecidos e tenta
determinar se alguns deles podem ser agrupados de alguma maneira, formando
agrupamentos ou clusters
SUPERVISIONADO
Requisitos:
Deve haver dadosde treino. Todos os algoritmos supervisionados devem ser “treinados” com dados previamente
separados para esse fim.
• Regressão Logística: Faz previsão de dados contínuos (Preços, quantidades, temperaturas, etc)
• Classificação: Faz previsão de dados discretos. (Verificar spam, operações fraudulentas online, tipo de imagem, etc)
9.
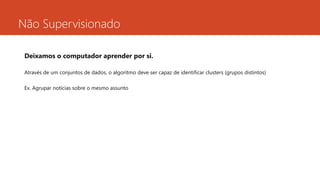
Não Supervisionado
Deixamos ocomputador aprender por si.
Através de um conjuntos de dados, o algoritmo deve ser capaz de identificar clusters (grupos distintos)
Ex. Agrupar notícias sobre o mesmo assunto
Exemplos
Regressão Logística
Prever ovalor de venda de casas, sabendo o tamanho em m², o número de quartos e a respectiva idade.
Classificação
Detecção de SPAM. Analisa-se e-mails e classifica-os como sendo spam ou não
Detecção de Anomalias/Fraudes: Analisa os indicadores de um equipamento e classifica-o como tendo uma
anomalia ou não. Analisa o comportamento do utilizador num website e classifica a possibilidade de atividade
fraudulenta.
12.
Exemplos
Não supervisionado
• Catalogare agrupar automaticamente fotos sobre o mesmo tema
• Identificar segmentos do mercado através de elementos recolhidos do perfil dos consumidores e do tipo de
consumo, para fazer promoções ou publicidade dirigida.
13.
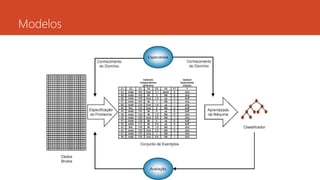
Algoritmos
A fim deretornar os melhores resultados, os algoritmos
desempenha uma função crucial para isso.
Ainda que AM seja uma ferramenta poderosa para a
aquisição automática de conhecimento, deve ser
observado que não existe um único algoritmo que
apresente o melhor desempenho para todos os
problemas.
Vídeo - Watson
CLIQUENA IMAGEM PARA ASSISTIR AO VÍDEO
ou acesse: https://www.youtube.com/watch?v=Zct7M5j3Bls
19.
Estudo de Caso
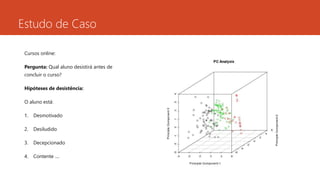
Cursosonline:
Pergunta: Qual aluno desistirá antes de
concluir o curso?
Hipóteses de desistência:
O aluno está:
1. Desmotivado
2. Desiludido
3. Decepcionado
4. Contente ....












![Questionamentos e agrupamentos
O que posso fazer para evitar que o aluno desista?
Alunos = []
Alunos << [12, 150, 3, 15]
Alunos << [4, 170,12, 25]
Alunos << [1, 10, 3, 25]
Alunos << [ 12, 20, 31, 15]
Labels = [1, 1, 0, 0]
Juremo = [6, 140, 25, 10]
Model.predict(Node.feature(Juremo))](https://image.slidesharecdn.com/meetup-machinelearning-140704091704-phpapp01/85/AlfaCon-LABs-Meetup-Machine-Learning-03-07-2014-20-320.jpg)























![[Entertainment] Tomorrowland Brazil 2015](https://cdn.slidesharecdn.com/ss_thumbnails/tomorrowland-brasil-englishversion-20150703-150715210737-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)



















