Baixar para ler offline









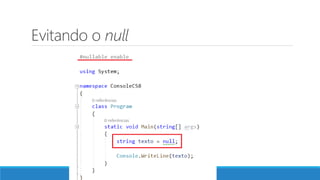
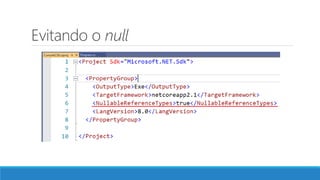


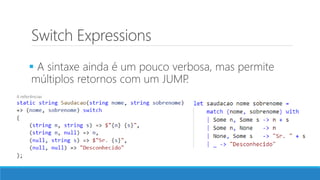
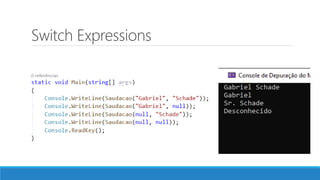

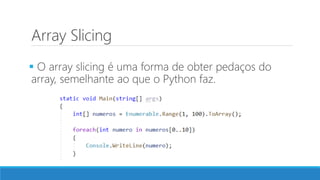
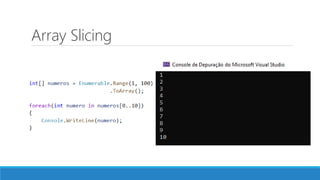
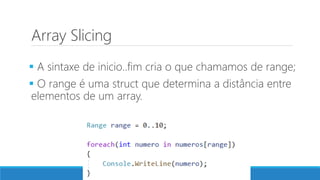
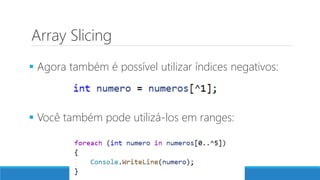
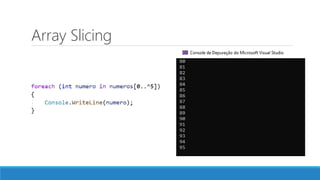



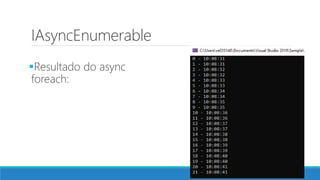

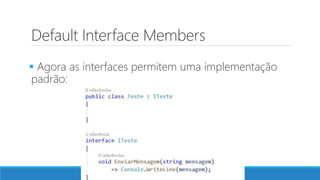
















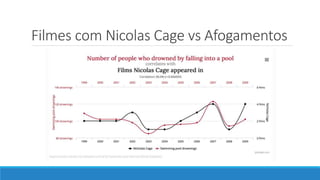







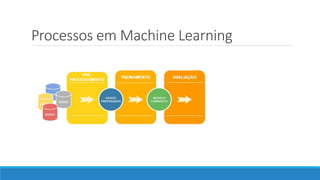
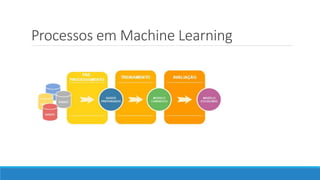
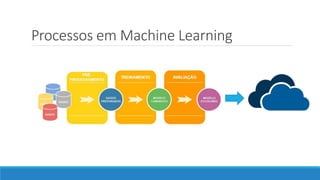




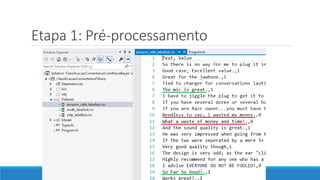



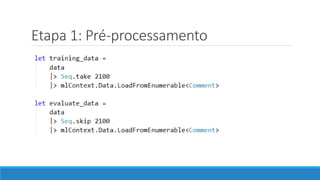


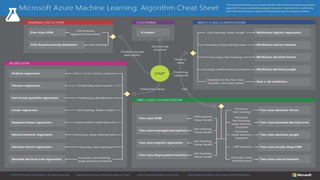










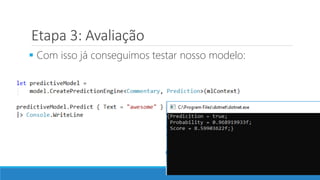

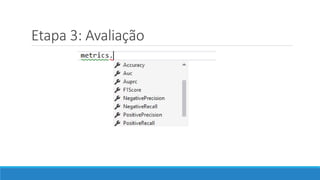






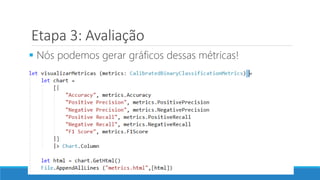
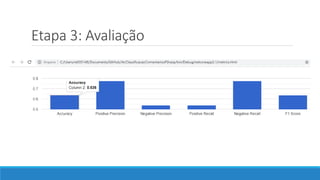



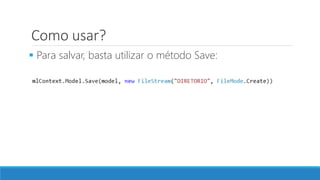



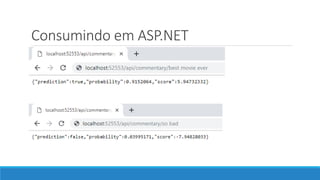



O documento aborda as novidades do C# 8 e a implementação de machine learning com ML.NET, destacando novos recursos como evitando null, array slicing, e iasyncenumerable. Em machine learning, o processo é dividido em pré-processamento, treinamento e avaliação, onde dados são coletados e algoritmos são aplicados para classificar comentários como positivos ou negativos. O documento enfatiza o uso de métricas de avaliação e a acessibilidade do modelo treinado, seja em código .NET ou em formatos como ONNX.


![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)









































