Baixado 45 vezes

















































![22 – O número de gols marcados no último campeonato da Federação Paulista de
Futebol pelos 20 clubes participantes nos seus 38 jogos é uma variável com os
seguintes valores:
Clube 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Gols 32 42 73 35 79 57 37 52 35 25 55 70 42 41 68 66 74 29 47 53
a) Classifique a variável. Você acha razoável construir uma tabela de freqüência de
acordo com a classificação dada?
b) Construa uma tabela de freqüência agrupando as observações em intervalos de
classes.
c) Obtenha o histograma.
d) Que porcentagem dos clubes marcaram mais de 38 gols?
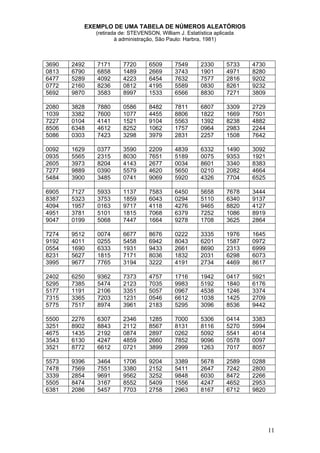
23 – Uma nova ração foi fornecida a suínos recém desmamados e deseja-se avaliar
sua eficiência. A ração tradicional dava um ganho de peso ao redor de 3,5 Kg em um
mês. A seguir, apresentamos os dados referentes ao ganho, em quilos, para essa
nova ração, aplicada durante um mês em 200 animais nas condições acima.
a) Construa o histograma.
b) Você acha que a nova ração é mais eficiente que a tradicional? Justifique.
Ganho F
1,0├ 2,0 45
2,0├ 3,0 83
3,0├ 4,0 52
4,0├ 5,0 15
5,0├ 6,0 4
6,0├ 7,0 1
Total 200
24 – num estudo sobre rotatividade de mão de obra na indústria, anotou-se o número
de empregos nos últimos 3 anos para operários especializados e não especializados.
a) Construa o diagrama de barras correspondente a cada tabela usando a freqüência
relativa.
b) Junte as informações das duas tabelas em uma só e obtenha um diagrama de
barras da rotatividade de mão de obra na indústria sem diferenciar a especialização.]
c) Você acha que os trabalhadores especializados trocam menos de emprego?
Justifique.
Não Especializados Especializados
Empregos f Empregos f
1 106 1 210
2 222 2 342
3 338 3 109
4 292 4 91
5 164 5 35
Total 1122 Total 787
25 – Como parte de uma avaliação médica em uma certa universidade, foi medida a
freqüência cardíaca dos alunos do primeiro ano. Os dados são apresentados em
seguida.
a) Obtenha o histograma.
b) Freqüências cardíacas que estejam abaixo de 62 ou acima de 92 requerem
acompanhamento médico. Qual a porcentagem de alunos nessas condições?
c) Uma freqüência ao redor de 72 batidas por minuto é considerada padrão. Você
acha que de modo geral esses alunos se encaixam nesse caso?
Freqüência Cardíaca f
60├ 65 11
65├ 70 35
70├ 75 68
75├ 80 20
55](https://image.slidesharecdn.com/apostiladeestatstica-130106172616-phpapp02/85/Apostila-de-estat_stica-55-320.jpg)




1) O documento é uma apostila sobre estatística que apresenta conceitos básicos da disciplina, incluindo a natureza da estatística, probabilidade, inferência estatística, amostragem e aplicações da estatística em empresas. 2) A estatística é definida como uma parte da matemática aplicada que fornece métodos para coleta, organização, análise e interpretação de dados para tomada de decisões. 3) O trabalho estatístico consiste em cinco etapas: coleta e cr


















![Estatistica[1]](https://cdn.slidesharecdn.com/ss_thumbnails/estatistica1-120719160006-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















































