Baixado 69 vezes












![Manual de Estatística Aplicada
Classes de
valores da variável
[x1; x2[
[x2; x3[
[x3; x4[
Frequências absolutas
n1
f1
nj
fj
n
n: dimensão da amostra
[xn-1; xn]
Total
Frequências relativas
fn
1
Exemplo: Estudo do rácio de autonomia financeira de uma amostra de 68
empresas
Rácio (X)
[0; 0.5[
[0.5; 1[
[1; 1.5[
[1.5; 2[
[2; 3[
[3; 6]
Total
Nº de empresas (ni)
4
22
26
10
4
2
68
% de empresas (fi)
5.9%
32.4%
38.2%
14.7%
5.9%
2.9%
1
Amplit (hi)
0.5
0.5
0.5
0.5
1.0
3.0
fi/hi
11.8%
64.7%
76.5%
29.4%
5.9%
1%
A distribuição de frequências representa-se através de um histograma.
Um histograma é uma sucessão de rectângulos adjacentes, em que a base é
uma classe e a altura a frequência (relativa ou absoluta) por unidade de
amplitude (ni/ai ou fi/ai), sendo a amplitude de cada classe ai=ei-ei-1. A área total
do histograma é a soma das frequências relativas, isto é, 1.
fi/hi
90%
80%
70%
60%
50%
40%
30%
20%
10%
0%
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
5
5,5
6
racio
Manual Técnico de Formando
12](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-13-320.jpg)
![Manual de Estatística Aplicada
1. Esta distribuição permite visualizar o tipo de distribuição e deve salientar
alguns aspectos mais relevantes desta (moda, classe modal, ...). Como
as classes podem ter amplitudes diferentes, para que todos os
rectângulos (colunas) sejam comparáveis é necessário corrigir as
frequências das classes (calculando as frequências que se teria se a
amplitude de todas as classes fosse igual e igual a 1)
2. É preferível representar o histograma com fi/hi do que com ni/hi uma vez
que deste modo é possível comparar distribuições com diferente número
de observações amostrais.
Também é possível calcular as frequências (absolutas – Ni - e relativas - Fi)
acumuladas:
Rácio (X)
[0; 0.5[
[0.5; 1[
[1; 1.5[
[1.5; 2[
[2; 3[
[3; 6]
Total
Nº empresas (ni)
4
22
26
10
4
2
68
% empresas (fi)
5.9%
32.4%
38.2%
14.7%
5.9%
2.9%
1
Ni
Fi
4
5.9%
4+22
5.9%+32.4%
4+22+26
76.5%
4+22+26+10
91.2%
66
97.1%
68
100%
2.4. Medidas de localização
2.4.1. Média ( X )
É a medida de localização mais usada, sobretudo pela sua facilidade de
cálculo.
Dados não-classificados (não agrupados numa tabela de frequências)
x =
1
n
n
i =1
xi
Média aritmética simples
Dados classificados (isto é, agrupados numa tabela de frequências)
Variáveis discretas
Manual Técnico de Formando
13](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-14-320.jpg)









![Manual de Estatística Aplicada
n −1
G=
i =1
( pi − qi )
n −1
pi
i =1
Quando G = 0, a concentração é nula, havendo igual repartição. Caso o valor
de G seja 1, a concentração será máxima. O valor de G varia entre 0 e 1, e
quanto maior o seu valor, maior a concentração.
Exemplo
Considere-se a seguinte amostra de dimensão 200, referente aos lucros
obtidos por empresas de um dado sector industrial, expressas numa
determinada unidade monetária.
Lucros
[0; 50[
[50; 100[
[100; 200[
[200; 300[
[300; 500]
Total
ni
20
60
80
30
10
200
Lucro total
600
4400
14000
7500
3500
30000
pi (=Fi)
0.1
0.4
0.8
0.95
1
qi
0.02
0.16(6)
0.63(3)
0.883(3)
1
Curva de Lorenz
1
0,8
0,6
0,4
0,2
0
0
Manual Técnico de Formando
0,2
0,4
0,6
0,8
1
23](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-24-320.jpg)






![Manual de Estatística Aplicada
[0; 1[
[1; 3[
[3; 5[
[5; 15[
[15; 25[
[25; 50]
X
Total
b) x =
1
n
fi
10%
25%
35%
15%
10%
5%
1
n
i =1
ni c i
=
n
i =1
f i ci
hi
1
2
2
10
10
25
fi/hi
0.1
0.125
0.175
0.015
0.01
0.002
Fi
10%
35%
70%
85%
95%
100%
ci
0.5
2
4
10
20
37.5
= (0,5 x10%) + (2 x 25%) + ... + (37.5 x5%) = 7,325
Em média, o resultado líquido de uma empresa é de 7325 unidades
monetárias.
A classe modal é aquela a que corresponde maior frequência por unidade de
amplitude. Neste caso, o maior valor de fi / hi é 0,175. correspondente à classe
[3; 5[, isto é, os valores de resultado líquido mais prováveis para uma empresa
situam-se entre 3000 u.m. e 5000 u.m.
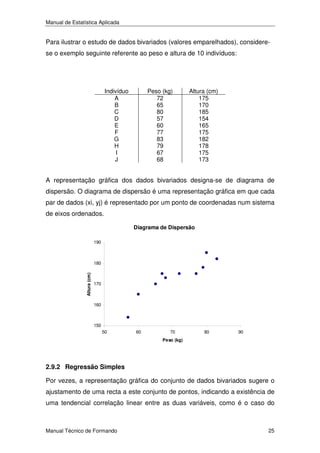
c) A representação gráfica das frequências acumuladas (ver tabela) designa-se
de polígono integral:
Fi
1
0,8
0,6
0,4
0,2
0
0
20
40
60
80
100
120
Classe mediana (classe a que corresponde uma frequência acumulada 0,5): [3; 5[
3 : Fi=0,35
5 : Fi = 0,7
Manual Técnico de Formando
31](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-32-320.jpg)



![Manual de Estatística Aplicada
b)
r=
s xy
s xx s yy
1
[(10 − 21,429)(3 − 6,714) + ... + (35 − 21,429)(13 − 6,714)]
7
=
= 0,98
69,9408 x 11,0651
Existe uma correlação positiva linear forte entre as duas variáveis. Em média,
quando as despesas em publicidade aumentam (diminuem), as vendas
aumentam (diminuem) de forma quase exactamente proporcional.
Recta de Regressão
c)
y = 2,4649x + 4,8782
Vendas
30
20
10
0
3
8
13
Desp. Public.
Manual Técnico de Formando
35](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-36-320.jpg)
![Manual de Estatística Aplicada
ESTATÍSTICA DESCRITIVA
Exercícios para resolver
1. O quadro que se segue descreve a distribuição do rendimento anual (em
milhares de u.m.) de 2500 famílias consideradas representativas da população
de um país:
Rendimento anual
[0, 1[
[1, 2[
[2, 5[
[5, 15[
[15, 25[
[25, 50[
Nº de famílias
250
375
625
750
375
125
a) Represente as frequências acumuladas graficamente.
b) Determine o rendimento médio e mediano.
c) Determine os três primeiros quartis. Que indicações lhe dão sobre a
(as)simetria?
d) O que pode concluir quanto à dispersão?
e) Calcule o índice de Gini. O que conclui sobre a concentração do
rendimento?
2. Considere a seguinte tabela que representa a distribuição dos empregados
de uma instituição bancária segundo a remuneração bruta mensal (em milhares
de unidades monetárias):
Remuneração
[60; 80[
[80; 100[
[100; 120[
[120; 140[
[140; 160[
[160; 200[
[200; 250[
[250, 300[
[300; 350]
Total
Manual Técnico de Formando
Frequência. Relativa
(%)
7.8
15.2
31.2
19.5
7.2
8.1
5.4
2.6
3.0
100
36](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-37-320.jpg)
![Manual de Estatística Aplicada
a) Calcule os quartis e faça a sua representação gráfica. O que pode
concluir?
b) Analise a dispersão da distribuição em causa.
c) Analise a assimetria da distribuição em causa.
3. Os dados seguintes referem-se ao peso, expresso em gramas, do conteúdo
de uma série de 100 garrafas que, no decurso de um teste, saíram de uma
linha de enchimento automático:
Peso (em gramas)
[297; 298[
[298; 299[
[299; 300[
[300; 301[
[301; 302[
[302; 303[
[303; 304[
[304; 305[
[305; 306]
Total
Frequência. Relativa
(%)
8
21
28
15
11
10
5
1
1
100
a) Represente graficamente os dados acima.
b) Calcule as frequências acumuladas e represente-as graficamente.
c) Determine o peso médio, mediano e modal. Qual o seu significado?
d) Determine os quartis da distribuição. Faça a sua representação gráfica.
e) Analise a dispersão do peso das garrafas.
4. Numa faculdade, mediram-se as alturas de 100 alunos do primeiro ano:
Altura (em metros)
[1,4; 1,5[
[1,5; 1,55[
[1,55; 1,6[
[1,6; 1,65[
[1,65; 1,7[
[1,7; 1,75[
[1,75; 1,8[
[1,8; 1,9]
Total
Manual Técnico de Formando
Nº Alunos
2
10
25
13
17
20
10
3
100
37](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-38-320.jpg)
![Manual de Estatística Aplicada
a) Represente graficamente os dados acima.
b) Determine a altura média e a altura modal. Qual o seu significado?
c) Calcule as frequências acumuladas e represente-as graficamente.
d) Determine os quartis da distribuição e diga qual o seu significado.
e) Faça a representação gráfica dos quartis.
f) Analise a dispersão da distribuição.
g) Analise a (as)simetria da distribuição.
5. Em determinada central telefónica, registou-se a duração das chamadas
realizadas em Dezembro de 2001:
Duração (em minutos)
[0; 5[
[5; 10[
[10; 20[
[20; 30[
[30; 50]
Total
Nº Chamadas
2000
1500
1000
300
200
5000
a) Represente graficamente as frequências simples e acumuladas.
b) Determine a duração média das chamadas e respectivo desvio-padrão.
c) Qual a duração da chamada mediana? Qual o significado do valor
encontrado?
d) Sabe-se que as chamadas realizadas durante o ano de 2001
apresentaram uma duração média de 10 minutos, com desvio-padrão de
8,7 minutos. Compare, quanto à dispersão, as chamadas efectuadas em
Dezembro com a s que tiveram lugar durante todo o ano de 2001.
6. Uma empresa coligiu dados relativos à produção de 12 lotes de um tipo
especial de rolamento. O volume de produção e o custo de produção de cada
lote apresentam-se na tabela:
Manual Técnico de Formando
38](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-39-320.jpg)


















![Manual de Estatística Aplicada
e logo
X −c
σ
n
;X +c
σ
n
= X−
[
1,96 x3
1,96 x3
;X −
= X − 0,535; X + 0,535
11
11
[
]
]
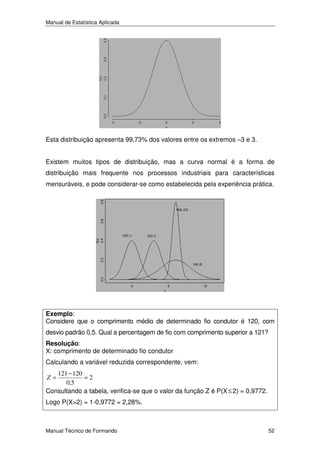
O intervalo X − 0,535; X + 0,535 contém o verdadeiro valor do parâmetro µ
com probabilidade ou confiança de 95%. Conhecida uma estimativa particular
daquele parâmetro, torna-se possível calcular entre que valores seria de
esperar que, com 95% de confiança, variasse µ .
Se o desvio - padrão da população fôr desconhecido, utiliza-se este intervalo
considerando-se como estimativa de σ o desvio - padrão corrigido da amostra,
ou seja, s’=
( xi − x ) 2
n −1
, tal que:
X −c
s'
n
;X +c
s'
n
(ii) Intervalo de confiança para a proporção p de uma população binomial
ˆ
Seja p (proporção amostral ou frequência observada na amostra) o estimador
da proporção p de uma população binomial. Sendo a amostra de grande
dimensão, a distribuição deste estimador será:
ˆ
p ∩ N ( p;
p(1 − p )
)
n
Uma vez que apenas se encontra tabelada a distribuição N(0,1), torna-se
necessário calcular a variável reduzida correspondente:
Z=
ˆ
p− p
p (1 − p )
n
∩ N (0;1)
Esta variável permitirá deduzir a fórmula geral do intervalo de confiança para a
proporção p de uma população binomial:
ˆ
p−c
ˆ
ˆ
ˆ
ˆ
p (1 − p )
p (1 − p )
ˆ
;p+c
n
n
ˆ
ˆ
(como estimativa de p (1 − p ) foi utilizado p (1 − p ))
Manual Técnico de Formando
57](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-59-320.jpg)
![Manual de Estatística Aplicada
Exemplo:
Numa cidade pretende-se saber qual a proporção da população favorável a
certa modificação de trânsito. Faz-se um inquérito a 100 pessoas, e 70
declaram-se favoráveis.
Determine um intervalo de confiança a 95% para a proporção de habitantes
dessa cidade favoráveis à modificação de trânsito.
Resolução:
n=100
ˆ
p=
70
= 0,7
100
c: P (−c ≤ Z ≤ c) = 95% ⇔ D (c) = 95% ⇔ c = 1,96
e logo
ˆ
p−c
ˆ
ˆ
ˆ
ˆ
p (1 − p )
0,7 x0,3
p (1 − p )
0,7 x0,3
ˆ
;p+c
= 0,7 − 1,96
;0,7 − 1,96
=
n
100
n
100
= [0,6102;0,7898]
O intervalo [0,6102;0,7898] contém o verdadeiro valor do parâmetro p com
probabilidade ou confiança de 95%.
Ou seja, a proporção de habitantes favoráveis à modificação de trânsito está
situada entre 61,02% e 78,98%, com probabilidade de 95%.
Como é óbvio, pretende-se que o resultado possua o máximo de confiança
possível. No entanto, se uma maior confiança é pretendida na estimação, esta
conduz a possibilidades de erro maiores, dado que um elevado nível de
confiança conduz a um intervalo maior e, como tal, a precisão da estimação
diminui.
Exemplo:
Consideremos 3 afirmações de alunos que aguardam a saída das pautas de
um exame de Estatística:
Afirm. 1: “Tenho a sensação que as pautas serão afixadas durante a manhã”
Afirm. 2: “Tenho quase a certeza que as pautas serão afixadas entre as 10h e
as 11h
Manual Técnico de Formando
58](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-60-320.jpg)











![Manual de Estatística Aplicada
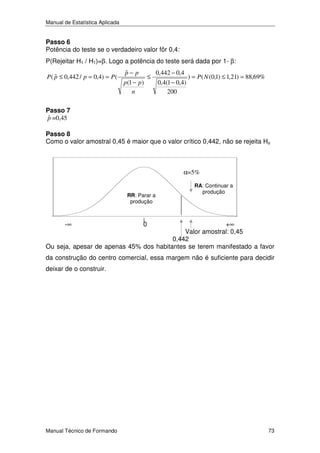
Passo 3
A região crítica é formada por todos os valores menores ou iguais a c
Passo 4
Assumir um nível de significância de 5%
Passo 5
Para α=5%, determinar a região de rejeição e aceitação.
Logo, sendo
P(Rejeitar Ho / Ho) = α = 5%, vem que
P ( X < c / µ = 1) = 0,05 ⇔ P (
X −µ
σ
<
n
c −1
) = 0,05 ⇔
0,01
9
0,01
= 0,9945
3
Logo, RC = ]− ∞;0,9945]
⇔ c = 1 − 1,645 x
Passo 6
Potência do teste se o verdadeiro valor fôr 0,99:
A probabilidade de rejeitar H1 erradamente, isto é, de se cometer um erro de 2ª
espécie, vem então igual a:
P(Rejeitar H1 / H1)=β. Logo a potência do teste será dada por 1- β:
P ( X ≤ 0,9945 / µ = 0,99) = P (
X −µ
σ
n
Passo 7
Calcular a estatística X =
1
9
≤
0,9945 − 0,99
) = P ( N (0,1) ≤ 1,35) = 91,15%
0,01
9
xi = 0,9933
Passo 8
Tomar a decisão
Como o valor da amostra foi 0,9933 e é menor que o valor crítico 0,9945,
rejeita-se Ho
Ou seja, considera-se que o arroz contido em cada pacote era inferior ao
indicado. No entanto, há o risco de se mandar parar a produção para revisão
do equipamento sem necessidade. Reduzindo a probabilidade de isso ocorrer
de 5% para 1%, vem:
Manual Técnico de Formando
70](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-72-320.jpg)
![Manual de Estatística Aplicada
Conceitos
Notação
Parâmetro
p
Percentagem ou proporção de habitantes da
cidade favoráveis à construção de um centro
comercial
Estimador
ˆ
p
Percentagem ou proporção de habitantes da
amostra favoráveis à construção de um centro
comercial
Estimativa
Definição
Valor da proporção daquela amostra
Hipótese nula
Hipótese alternativa
Erro de tipo I
Alfa (α)
Erro de tipo II
Beta (β)
Ho: p = 0,5
H1: p < 0,5
Considerar que a maioria dos habitantes não é favorável à
construção do centro comercial quando de facto são
Considerar que a maioria dos habitantes é favorável à
construção do centro comercial quando são contra
Resolução
Passo 1
Formular as hipóteses:
Ho: p = 0,5
H1: p < 0,5
Passo 2
A estatística a ser utilizada será a proporção amostral, onde o cuidado deve ser
trabalhar com grandes amostras.
Passo 3
A região crítica é formada por todos os valores menores ou iguais a c
Passo 4
Assumir um nível de significância de 5%
Passo 5
Para α=5%, determinar a região de rejeição e aceitação.
Logo, sendo
P(Rejeitar Ho / Ho) = α = 5%, vem que
ˆ
P ( p < c / p = 0,5) = 0,05 ⇔ P (
⇔ c = 0,5 − 1,645 x
ˆ
p− p
p (1 − p )
n
0,5(1 − 0,5)
= 0,442
200
Manual Técnico de Formando
<
c − 0,5
0,5(1 − 0,5)
200
) = 0,05 ⇔
Logo, RC = ]− ∞;0,442]
72](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-74-320.jpg)










![Manual de Estatística Aplicada
-
n=16
-
σ=0,25
-
Proceder-se-á à paragem da produção sempre que os limites de controlo
sejam desrespeitados
-
Um condutor é considerado não defeituoso se a sua resistência em Ω
estiver compreendida entre [49,530; 50, 470]
Nestas condições, determine:
a)
O valor da norma µ0
b)
A probabilidade de se proceder a uma paragem indevida da produção
c)
A probabilidade de, estando a norma a ser cumprida, se produzir um
artigo defeituoso.
Resolução
X: resistência de um componente em Ω
X ∩ N ( µ ; (0,25) 2 )
a)
LIC = µ −
LSC = µ +
cσ
n
cσ
n
= 49,8775
= 50,1225
Como LIC + LSC = 100 vem que µ −
cσ
n
+ µ+
cσ
n
= 2 µ = 100
Logo µ=100/2 = 50 Ω
b)
P (parar indevidamente o processo produtivo) =
P( X cair fora dos limites de controlo quando µ=µ0) =
1 - P(49,8775 ≤ X ≤ 50,1225 sendo µ=50) =
1 - P(
49,8775 − 50
50,1225 − 50
≤X ≤
)=
0,25
0,25
16
Manual Técnico de Formando
16
85](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-87-320.jpg)











![Manual de Estatística Aplicada
CONTROLE ESTATÍSTICO DE QUALIDADE
Exercícios
1. A empresa “TRADECHO, SA” mantém um diferendo com os seus principais
clientes, que afirmam que os produtos produzidos (em série) por esta empresa
não obedecem às normas de qualidade estabelecidas e que são:
-
a norma para o comprimento médio das peças é de 20 cm;
-
a norma para a variância é de 4;
-
a amplitude do intervalo de controle para a média deve ser de 1,96;
-
a dimensão das amostras a extrair é de 16
Afirmam os clientes que a probabilidade de parar indevidamente o processo
produtivo é superior àquela que decorre das normas.
a) Determine a probabilidade referida.
b) Represente a carta de controle para a média
c) A recolha de 5 amostras forneceu os seguintes resultados para a média:
20,05
19,90
20,00
20,30
20,15
Qual a medida a tomar?
2. Numa empresa procede-se ao exame das condições de produção relativas à
duração (em horas) das lâmpadas fabricadas (produção em série). Sabe-se
que o desvio-padrão da duração de uma lâmpada é de 100 horas.
O Departamento de Produção construiu o seguinte intervalo para a duração
média de uma lâmpada, a partir de uma amostra de dimensão 100:
[983,55; 1016,45]
parando-se o processo produtivo se o valor médio amostral se situar fora deste
intervalo.
a) Calcule o valor adoptado para a norma (µ0)
b) Determine a probabilidade de se parar indevidamente o processo
produtivo.
Manual Técnico de Formando
99](https://image.slidesharecdn.com/23126estatisticaaplicadamanualtecnicoformando-131209132229-phpapp02/85/23126-estatisticaaplicada-manualtecnicoformando-101-320.jpg)



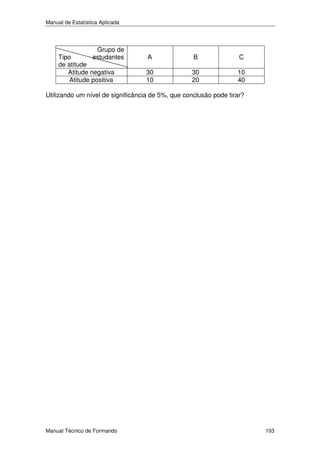



O documento apresenta um manual de estatística aplicada, abordando os seguintes tópicos: 1) Introdução à estatística, definindo conceitos como população, variáveis, amostragem. 2) Estatística descritiva, incluindo medidas de localização, dispersão, concentração e análise bidimensional. 3) Estatística indutiva, abordando probabilidades, estimação por intervalos, testes de hipóteses e aplicações como fiabilidade, controlo de qualidade e tratamento de inquéritos

















![Estatistica[1]](https://cdn.slidesharecdn.com/ss_thumbnails/estatistica1-120719160006-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




































