Baixado 115 vezes




















































![Módulo 4
c) 20 chamadas em uma semana:
λ = 21 chamadas por semana
Uma característica da distribuição de Poisson é que as estatísticas da distribuição (média e variância) apresentam o mesmo valor, ou
seja, são iguais a λ. Então, teremos:
Média = Variância = λ
Como o intervalo
desejado é uma semana, ou seja, sete dias,
então, em uma semana
a freqüência média de
chamadas será de sete
dias vezes 3 chamadas/dia.
Vamos fazer alguns exercícios relativos à distribuição
binomial e de Poisson.
Exercício 7: no Brasil, a proporção de microempresas que fecham em até um ano é de 10%. Em uma amostra aleatória de 20
microempresas, qual a probabilidade de cinco terem fechado em até
um ano de criação?
R: P(X = 5) =
= 0,03192
Exercício 8: entre 2.000 famílias de baixa renda, com quatro
crianças e considerando que a chance de nascer uma criança do sexo
masculino é igual à do sexo feminino, em quantas famílias se esperaria que tivessem:
n=4ep=½
a) dois meninos? R: P(x=2) . 2.000 = 0,3750 . 2.000 = 750
famílias.
b) Um ou dois meninos? R: [P(1) + P(2)] . 2.000 = (0,25 +
0,375) . 2.000 = 1.250 famílias.
c) Nenhum menino? R: P(0) . 2.000 = 0,0625 . 2.000 = 125
famílias.
61](https://image.slidesharecdn.com/estatisticacompletorevisado-140211060301-phpapp01/85/Estatistica-completo-revisado-61-320.jpg)
![Curso de Graduação em Administração a Distância
Exercício 9: a probabilidade de compra de um aparelho de celular é igual a 30%. Observando oito compradores, qual a probabilidade
de quatro deles comprarem este aparelho?
R: P(X = 4) =
= 0,13614
Exercício 10: chegam caminhões a um depósito à razão de 2,8
caminhões/hora, segundo uma distribuição de Poisson. Determine a
probabilidade de chegarem dois ou mais caminhões:
a) num período de 30 minutos;
b) num período de 1 hora; e
c) num período de 2 horas.
R: 1- [P(0) + P(1)]
a) λ = 1,4
R= 0,40817
b) λ = 2,8
R=0,76892
c) λ = 5,6
R=0,97559
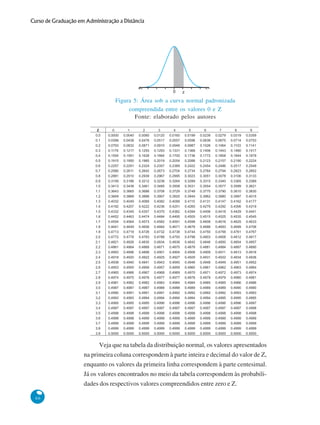
Distribuições de Probabilidade Contínuas
Dentre as várias distribuições de probabilidade contínuas, será
abordada aqui apenas a distribuição normal, pois apresenta grande
aplicação em pesquisas científicas e tecnológicas. Grande parte das
variáveis contínuas de interesse prático segue esta distribuição, aliada
ao Teorema do Limite Central (TLC), que é a base das estimativas e
dos testes de hipóteses, realizados sobre a média de uma população
qualquer, e garante que a distribuição amostral das médias segue uma
distribuição normal, independentemente da distribuição da variável em
estudo, como será visto mais adiante.
62](https://image.slidesharecdn.com/estatisticacompletorevisado-140211060301-phpapp01/85/Estatistica-completo-revisado-62-320.jpg)






























































![Curso de Graduação em Administração a Distância
Exercício 3:
a1) R: 60/100; a2) R: 40/100; a3) R: 24/100; a4) R: 76/100
Exercício 4:
R: 0,05/0,25 = 0,2
Exercício 5:
a) R: 0,4; b) R:0,9; c) R:0,6;
d) R:
1
0
2
0,1
0,3
0,6
3
4
0,9
1
e) R: 0,9. Probabilidade de alugar no máximo três caminhões.
Exercício 6:
R: 0,0089
Exercício 7:
R: P (X = 5) =
= 0,03192
Exercício 8:
Distribuição binomial com n = 4 e p = ½
a) R: P(x=2) . 2.000 = 0,3750 . 2.000 = 750 famílias
b) R: [P(1) + P(2)] . 2.000 = (0,25 + 0,375) . 2.000 = 1.250 famílias
c) R: P(0) . 2.000 = 0,0625 . 2.000 = 125 famílias
Exercício 9:
R: P(X = 4) =
= 0,13614
Exercício 10:
R: 1 – [P(0) + P(1)], onde a distribuição de probabilidade é uma
Poisson com parâmetro lambda.
a) λ = 1,4
R = 0,40817
b) λ = 2,8
R = 0,76892
c) λ = 5,6
R = 0,97559
130](https://image.slidesharecdn.com/estatisticacompletorevisado-140211060301-phpapp01/85/Estatistica-completo-revisado-130-320.jpg)





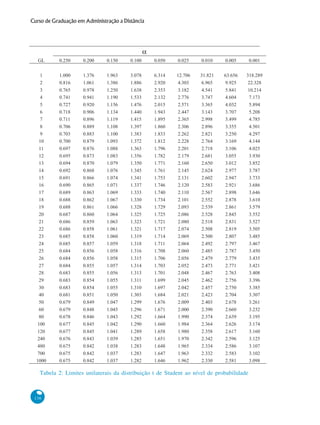







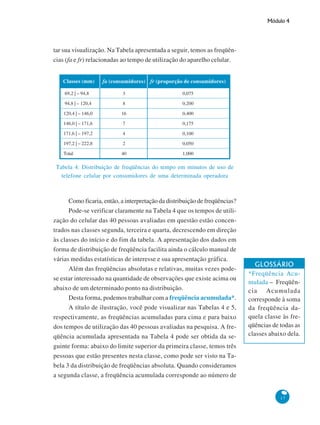
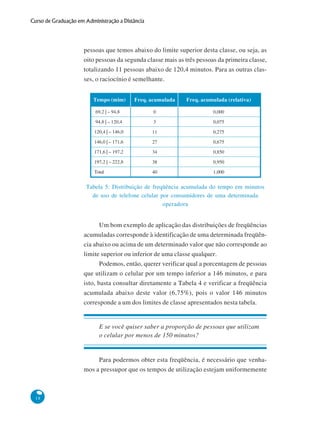
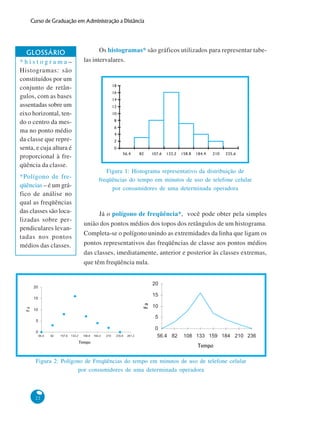
Com base nas informações fornecidas, aqui estão os passos para construir a distribuição de frequências dos dados de tempo de uso de celular: 1. Número de observações (n): 40 2. Número de classes (k): k = √n = √40 = 6 classes 3. Amplitude total (A): A = Maior valor - Menor valor = 210 - 82 = 128 minutos 4. Amplitude de classe (c): c = A/k = 128/6 = 21,33 minutos 5. Arredondando c para 21 minutos 6. Limite inferior da primeira classe: 82 - (c/2)










































































