Baixado 62 vezes











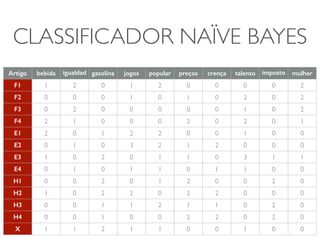

![CLASSIFICADOR NAÏVE BAYES
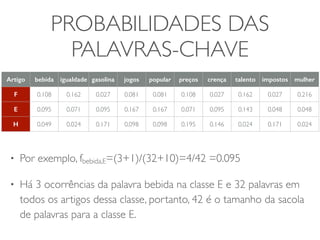
• p(F) = 1/3, p(E) = 1/3 e p(H) = 1/3
• Assuma que podemos derivar as probabilidades para o artigo x pertencer a
cada uma dessas classes [p(x|F), p(x|E), p(x|H)] a partir dos dados da tabela
• Sendo assim, as probabilidades posteriores das classes seriam proporcionais
aos produtos (Teorema de Bayes):
• p(F|x) = p(x|F)p(F)
• p(E|x) = p(x|E)p(E)
• p(H|x)=p(x|H)p(H)](https://image.slidesharecdn.com/iad-aula11-141030075920-conversion-gate02/85/Correlacao-e-Classificacao-16-320.jpg)
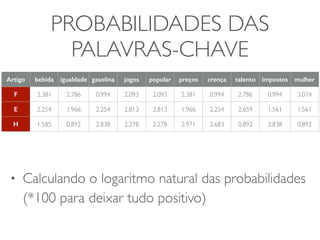
![CLASSIFICADOR NAÏVE BAYES
• x pertence a classe com a maior probabilidade a posterior
• p(F|x) = p(x|F)p(F)
• p(E|x) = p(x|E)p(E)
• p(H|x)=p(x|H)p(H)
• Problema: Como derivar as probabilidades de x pertencer a
cada uma das categorias [p(x|F), p(x|E), p(x|H)] a partir da tabela
?](https://image.slidesharecdn.com/iad-aula11-141030075920-conversion-gate02/85/Correlacao-e-Classificacao-17-320.jpg)
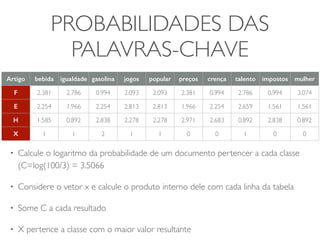
![CLASSIFICADOR NAÏVE BAYES
• Problema: Como derivar as probabilidades de x
pertencer a cada uma das categorias [p(x|F), p(x|E),
p(x|H)] a partir da tabela ?
• Principio Naïve Bayes: assuma que as variáveis são
independentes em cada classe F, E e H
• Depois, calcular o produto das probabilidades f1, f2,
…,f10 de cada palavra chave em cada classe](https://image.slidesharecdn.com/iad-aula11-141030075920-conversion-gate02/85/Correlacao-e-Classificacao-18-320.jpg)




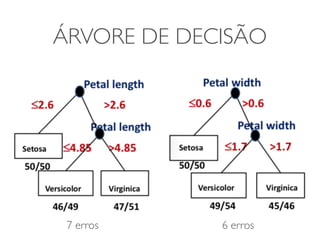
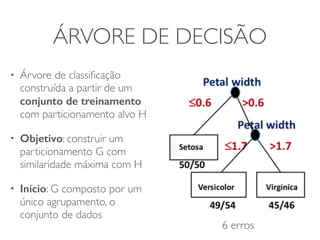


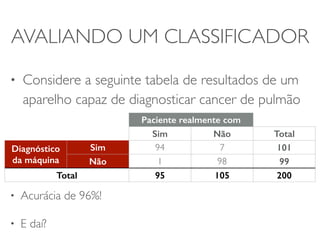

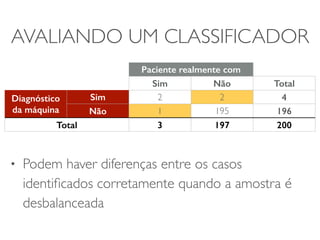
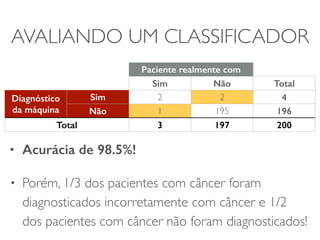

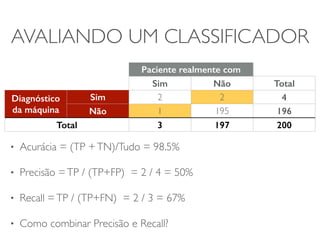



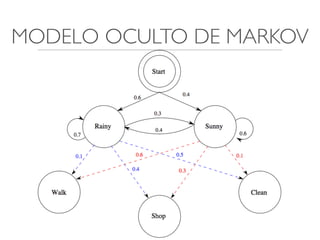
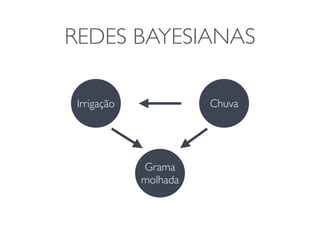
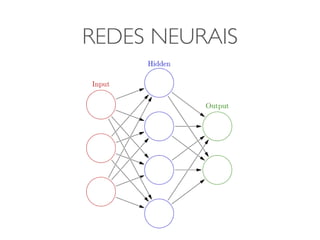
O documento discute diferentes estruturas de correlação e classificadores, incluindo: 1) Modelos ocultos de Markov, redes bayesianas e redes neurais como formas de encontrar regras para prever uma variável alvo a partir de variáveis de entrada. 2) O classificador Naive Bayes, que usa a probabilidade condicional de características dados os rótulos de classe para fazer predições de classe. 3) Árvores de decisão, que constroem particionamentos recursivos dos dados para predição de classe.






































![[José Ahirton Lopes] Treinamento - Árvores de Decisão, SVM e Naive Bayes](https://cdn.slidesharecdn.com/ss_thumbnails/treinamentodeveloperssp-180611021639-thumbnail.jpg?width=640&height=640&fit=bounds)





























