Transferir como PDF, PPTX















![VALIDAÇÃO ESTATÍSTICA
• Uma forma de prosseguir seria utilizar uma abordagem estatística
clássica
• Assumir que x é uma amostra selecionada aleatoriamente de uma
população normalmente distribuída com m=5.8433 e dp=0.8253
• Sendo assim, x também tem uma distribuição normal
• Portanto, com 95% de confiança, a média está no intervalo m
+- 1.96*(dp/sqrt(n)), [5.7108, 5.9759]](https://image.slidesharecdn.com/iad-aula08-141016095531-conversion-gate01/85/Sumarizacao-Estatistica-1D-23-320.jpg)

![VALIDAÇÃO COM
BOOTSTRAPPING
• N = 4, M = 3,
• N = número de entidades
• M = número de amostras
sample(N,M,
replace=T)
!
sample(4,3,replace=T)
!
[1]
2
3
1
[2]
1
1
3
[3]
2
3
4
[4]
4
1
1](https://image.slidesharecdn.com/iad-aula08-141016095531-conversion-gate01/85/Sumarizacao-Estatistica-1D-25-320.jpg)
![VALIDAÇÃO COM
BOOTSTRAPPING
sample(iris$Sepal.Length,4)
[1]
6.2
6.3
6.3
6.2
[2]
5.2
4.9
5.7
7.2
[3]
6.7
5.2
5.2
6.0](https://image.slidesharecdn.com/iad-aula08-141016095531-conversion-gate01/85/Sumarizacao-Estatistica-1D-26-320.jpg)
![VALIDAÇÃO COM
BOOTSTRAPING
lapply(1:1,
function(i)
sample(iris$Sepal.Length,
replace=T))
[[1]]
[1]
6.2
6.0
6.1
4.8
4.4
5.8
7.4
6.3
4.8
7.2
7.7
4.8
6.4
4.9
5.7
5.1
6.0
7.2
[19]
4.9
5.8
5.4
4.7
6.6
6.7
5.7
5.6
5.7
6.4
6.6
5.1
4.4
4.4
6.3
7.2
4.6
5.6
[37]
5.0
7.7
5.1
4.9
5.0
4.9
5.7
6.4
6.9
5.8
6.8
5.0
5.1
4.7
7.7
5.6
6.7
5.9
[55]
6.3
5.5
5.4
6.7
4.9
4.4
6.3
6.0
6.3
5.0
6.0
5.4
5.4
6.9
6.4
5.7
6.8
5.2
[73]
5.7
5.1
6.0
4.8
4.6
5.2
6.7
5.0
5.7
6.7
5.0
6.3
6.3
6.0
6.0
6.1
6.3
4.3
[91]
6.7
6.3
6.7
4.7
5.5
7.7
6.8
5.1
5.9
6.7
4.9
5.8
5.8
4.9
4.8
5.6
5.4
5.7
[109]
4.9
6.7
6.7
5.1
6.3
6.4
4.8
7.6
7.1
4.8
7.2
4.4
6.2
5.8
6.3
6.5
7.4
6.3
[127]
5.5
6.3
5.7
6.3
5.4
6.5
5.5
4.6
5.9
5.8
5.1
5.6
5.7
6.3
5.1
5.2
4.8
6.7
[145]
4.8
6.2
4.8
5.5
5.9
6.4](https://image.slidesharecdn.com/iad-aula08-141016095531-conversion-gate01/85/Sumarizacao-Estatistica-1D-27-320.jpg)
![VALIDAÇÃO COM
BOOTSTRAPING
• Método pivotal (95% confiança)
• Assume que as 5000 médias seguem uma
distribuição normal.
mean(rs.mean)
[1]
5.843325
sqrt(var(rs.mean))
[1]
0.0669005
Intervalo = m +- 1.96 *dp
[5.7122, 5.9744]](https://image.slidesharecdn.com/iad-aula08-141016095531-conversion-gate01/85/Sumarizacao-Estatistica-1D-29-320.jpg)
![VALIDAÇÃO COM
BOOTSTRAPING
• Método não-pivotal (95% de confiança)
• Pega como limite os percentis em 2.5% e 97.5%
• 1% de 5000 é 50, 2.5% é 125 e 97.5% é 4875
smean=sort(rs.mean)
smean[125]
[1]
5.714667
smean[4875]
[1]
5.979333
Intervalo [p2.5, p97.5]
[5.7145, 5.9793]](https://image.slidesharecdn.com/iad-aula08-141016095531-conversion-gate01/85/Sumarizacao-Estatistica-1D-30-320.jpg)
![ONDE ESTÁ A MÉDIA?
• Hipótese de distribuição normal: [5.7108, 5.9759]
• Bootstrapping pivotal: [5.7122, 5.9744]
• Bootstrapping não-pivotal: [5.7145, 5.9793]
• Como 95% de confiança!](https://image.slidesharecdn.com/iad-aula08-141016095531-conversion-gate01/85/Sumarizacao-Estatistica-1D-31-320.jpg)

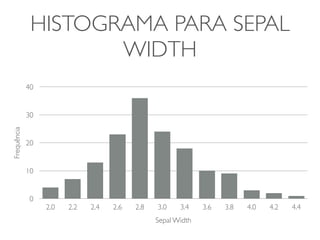
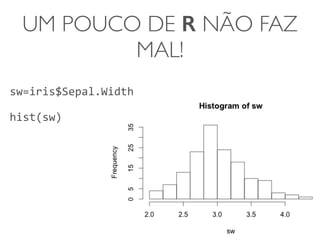
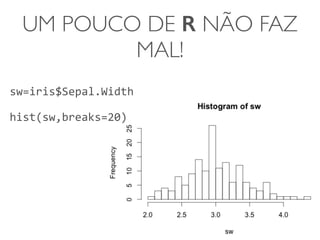
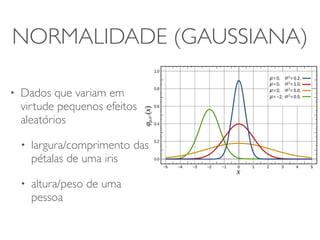
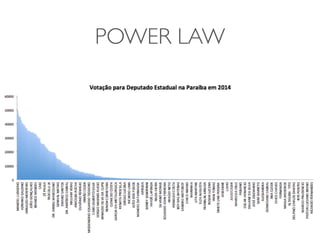
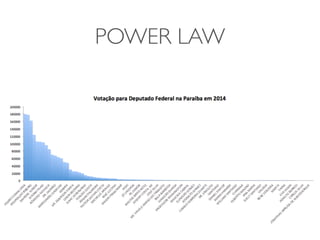
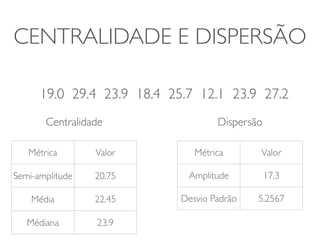
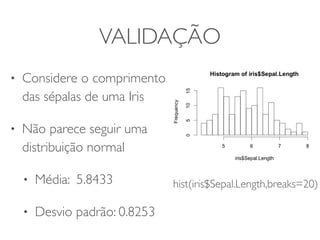
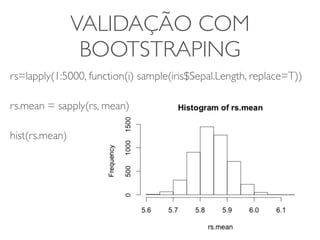
1) O documento discute a summarização estatística unidimensional de variáveis, utilizando como exemplo um conjunto de dados sobre flores Iris. 2) Histogramas e medidas de centralidade e dispersão, como média e desvio padrão, são apresentados para resumir a distribuição de uma variável. 3) A validação da média é discutida por meio de abordagens estatísticas clássicas e bootstrapping.



































































