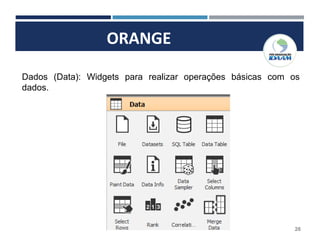
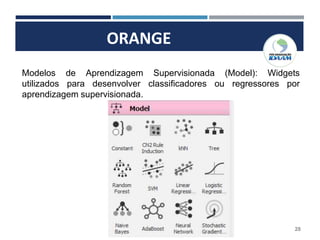
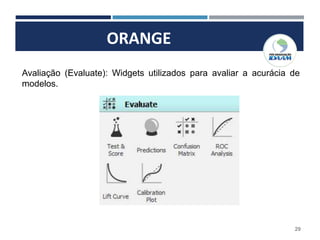
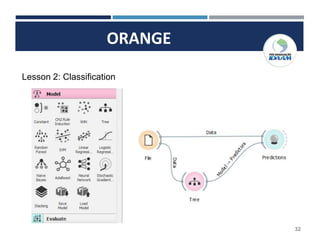
O documento apresenta o plano de um curso de Big Data e Data Mining para Indústria 4.0, com módulos sobre mapa de fluxo de valor, simulação de processos industriais, análise de big data, internet das coisas, robótica, drones, manutenção aditiva e segurança cibernética. Inclui também conceitos sobre estruturação e modelagem de dados, ferramentas de business intelligence, inteligência artificial, armazenamento em nuvem e conceitos estatísticos e de probabilidade.












![PROBABILIDADE
16
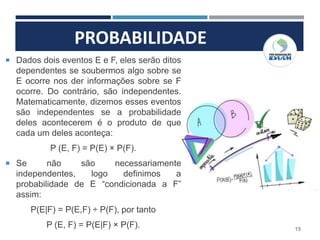
TEOREMA DE BAYES:
O teorema de Bayes é uma maneira de “reverter” as probabilidades
condicionais. Quando for necessário saber a probabilidade de algum
evento E ser condicionado à ocorrência de outro evento F, se
houver apenas a informação sobre a probabilidade da ocorrência de
F sendo condicionado a E, usando a definição de probabilidade
condicional duas vezes, pode-se dizer que:
P(E|F) = P(E, F) / P(F) = P(F|E) × P(E) / P(F)
Como o evento F pode ser dividido em dois eventos mutuamente
exclusivos “F e E” e “F e não E”, logo: P(F) = P(F, E)+P(F,¬E).
Portanto:
P(E|F) = P(F|E) × P(E) / [P(F|E) × P(E) + P(F|¬E) × P(¬E)]](https://image.slidesharecdn.com/aula3bigdatadatamining-190327203520/85/Aula-3-Big-Data-e-DataMining-16-320.jpg)
![PROBABILIDADE
17
TEOREMA DE BAYES:
Imagine que uma determinada doença afete 1 a cada 10.000
pessoas. E imagine que haja um teste para essa doença que mostra
o resultado correto (“doente” se não tiver a doença e “não doente”
se não) 99% das vezes. O que significa um teste positivo? Vamos
usar T para o evento “seu teste é positivo” e D para o evento “você
tem a doença”. O teorema de Bayes diz que a probabilidade de
você ter a doença, condicional ao teste positivo é:
P(D|T) = P(T|D) × P(D) / [P(T|D) × P(D) + P(T|¬D) × P(¬D)]](https://image.slidesharecdn.com/aula3bigdatadatamining-190327203520/85/Aula-3-Big-Data-e-DataMining-17-320.jpg)