O documento discute o método de agrupamento K-means. Ele explica as iterações do K-means, como escolher o número de grupos K e critérios para avaliar a qualidade de um agrupamento, como pureza.
AGENDA
• Oque é agrupamento
• Iterações do K-Means
• Critérios e Propriedades do K-Means
• O que é um bom agrupamento
• Quantos grupos
3.
O QUE ÉAGRUPAMENTO
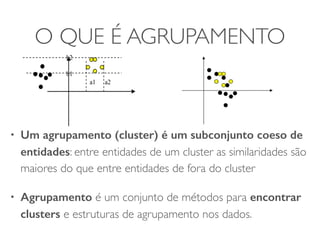
• Um agrupamento (cluster) é um subconjunto coeso de
entidades: entre entidades de um cluster as similaridades são
maiores do que entre entidades de fora do cluster
• Agrupamento é um conjunto de métodos para encontrar
clusters e estruturas de agrupamento nos dados.
4.
DIFERENTES PERSPECTIVAS
•Aprendizagem de máquina: análise não-supervisionada
de padrões
• Descoberta de conhecimento: construção de
classificadores
• Análise de dados: Identificar estruturas de
agrupamento nos dados
5.
IDENTIFICANDO ESTRUTURAS
DEAGRUPAMENTO NOS DADOS
• Agrupamento individual
• Detectando comunidades em uma rede
• Determinando um subconjunto de proteínas
similares a uma determinada proteína
• Identificando um subconjunto de documentos
sobre um mesmo tema
6.
IDENTIFICANDO ESTRUTURAS
DEAGRUPAMENTO NOS DADOS
• Particionamento
• Divisão da população de acordo com diferentes
estilos de vida
• Agrupamento de territórios em regiões econômicas
• Particionamento de imagens em segmentos
homogêneos
7.
IDENTIFICANDO ESTRUTURAS
DEAGRUPAMENTO NOS DADOS
• Agrupamento hierárquico
• Taxonomia de organismos
• Classificação de sub-áreas da computação
• Ontologia de conceitos em um domínio
8.
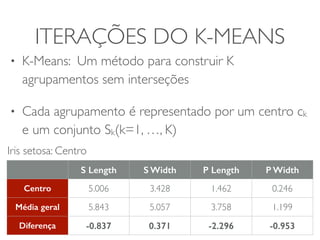
ITERAÇÕES DO K-MEANS
• K-Means: Um método para construir K
agrupamentos sem interseções
• Cada agrupamento é representado por um centro ck
e um conjunto Sk(k=1, …, K)
Iris setosa: Centro
S Length S Width P Length P Width
Centro 5.006 3.428 1.462 0.246
Média geral 5.843 5.057 3.758 1.199
Diferença -0.837 0.371 -2.296 -0.953
9.
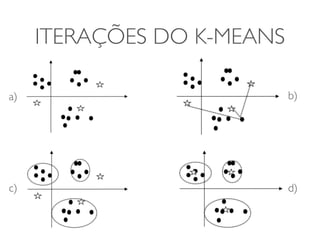
ITERAÇÕES DO K-MEANS
1. Especifique K, o número de agrupamentos, e os
centros iniciais ck (k=1, …, K)
2. Atualize os conjuntos Sk (k=1, …, K)
3. Atualize os centros ck (k=1,…, K)
4. Se os novos centros coincidem com os
anteriores, pare, senão, vá para 2.
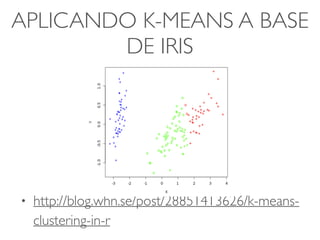
APLICANDO K-MEANS ABASE
DE IRIS
• Pré-processamento
• A: Sem pré-processamento: todas as medidas estão
relacionadas ao mesmo tipo de flor e na mesma unidade
• B: (Z-Scoring) Cada variável é centralizada em relação a
média e normalizada pelo desvio padrão
• C: Cada variável é centralizada em relação a média e
normalizada pelo range
12.
APLICANDO K-MEANS ABASE
DE IRIS
• Especifique K = 3 e os exemplares 1, 51 e 101 como
os centros iniciais (conhecimento preliminar)
• A (sem pré-processamento): Convergiu em 4 iterações
• B (Z-scoring): Convergiu em 7 iterações
• C (Normalização pelo range): Convergiu em 5
iterações
13.
APLICANDO K-MEANS ABASE
DE IRIS
• http://blog.whn.se/post/28851413626/k-means-clustering-
in-r
14.
VANTAGENS
• Computaçãoé intuitiva
• Processamento é rápido e não requer memória
adicional
• Processamento é fácil de paralelizar (big data)
15.
DISCUSSÃO
• OK-means sempre converge?
• Os resultados são independentes da inicialização?
• Se não, como devemos inicializar?
• Como escolher o número de clusters K ?
16.
O K-MEANS SEMPRE
CONVERGE?
• Minimizar W(S,c) alternando
• Mins W(S,c): atualização dos clusters
• Minc W(S,c): atualização dos centros
• Portanto, W(S,c) diminui a cada passo:
convergência
Σ
KΣ
W(s,c) = d(i,ck )
i∈Sk
k=1
17.
OS RESULTADOS SÃO
INDEPENDENTES DA INICIALIZAÇÃO?
• Qual seria o agrupamento
ótimo para K = 2 ?
• Convergimos para esse
agrupamento com
qualquer dois pontos
escolhidos como centros
iniciais ?
18.
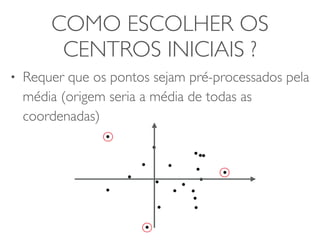
COMO ESCOLHER OS
CENTROS INICIAIS ?
• Escolher os pontos que maximizem D(S,c)
• onde:
• Nk é o número de entidades em Sk
• <ck,ck> é distância entre a origem e ck ao
quadrado
KΣ
D(S,c) = Nk < ck ,ck >
k=1
19.
COMO ESCOLHER OS
CENTROS INICIAIS ?
• Requer que os pontos sejam pré-processados pela
média (origem seria a média de todas as
coordenadas)
20.
O QUE ÉUM BOM
AGRUPAMENTO?
• Critério interno
• Exemplo de critério interno: média do quadrado das distâncias
no K-means
• Porém, um critério interno muitas vezes não avalia a utilidade do
agrupamento para uma aplicação.
• Alternativa: Critério externo
• Avaliar de acordo com um critério definido por humanos
21.
O QUE ÉUM BOM
AGRUPAMENTO?
• Baseado em algum padrão amplamente adotado
• Objetivo: O agrupamento deve reproduzir a
classes definidas no padrão
• Exemplo de medida de quão bem conseguimos
reproduzir classes pré-definidas: pureza
22.
CRITÉRIO EXTERNO: PUREZA
• Ω= {ω1, ω2, . . . , ωK} é o conjunte de grupos e
• C = {c1, c2, . . . , cJ} é o conjunto de classes
• Para cada grupo ωk : encontrar a cj com mais membros nkj em ωk
• Somar todos os nkj e dividir pelo número total de pontos
23.
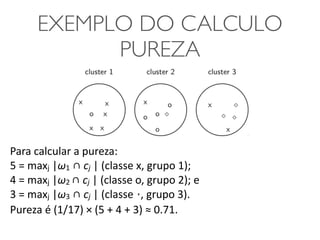
EXEMPLO DO CALCULO
PUREZA
Para
calcular
a
pureza:
5
=
maxj
|ω1
∩
cj
|
(classe
x,
grupo
1);
4
=
maxj
|ω2
∩
cj
|
(classe
o,
grupo
2);
e
3
=
maxj
|ω3
∩
cj
|
(classe
⋄,
grupo
3).
Pureza
é
(1/17)
×
(5
+
4
+
3)
≈
0.71.
QUANTOS GRUPOS?
•O número de grupos K é dado em muitas aplicações.
• Mas e quando isso não acontece? Há um número bom ou ruim para a
quantidade de grupos?
• Uma forma de agir: definir um critério de otimização
• Dado o conjunto de dados, encontrar o K para o qual o valor ótimo é obtido
• Que critérios de otimização podemos usar?
• Não podemos utilizar a média dos quadrados das distâncias do centróide
como critério: o valor ótimo sempre seria fazer K = N.
26.
QUANTOS GRUPOS
•Ideia básica:
• Começar com 1 grupo (K = 1)
• Continue adicionando grupos (= continue a aumentar K)
• Adicione uma penalidade para cada novo grupo
• Balancear a penalidade da adição de novos grupos e o quadrado das
distâncias até os centroides
• Escolher o valor K com o melhor tradeoff
27.
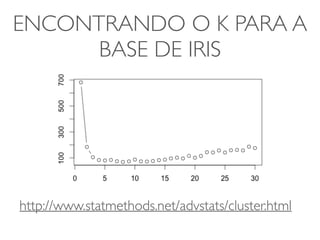
ENCONTRANDO O KPARA A
BASE DE IRIS
http://www.statmethods.net/advstats/cluster.html







































![[Phd Thesis Defense] CHAMELEON: A Deep Learning Meta-Architecture for News Re...](https://cdn.slidesharecdn.com/ss_thumbnails/chameleondefesadoutorado1-191209202516-thumbnail.jpg?width=640&height=640&fit=bounds)





![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)
















































