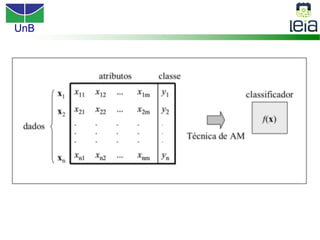
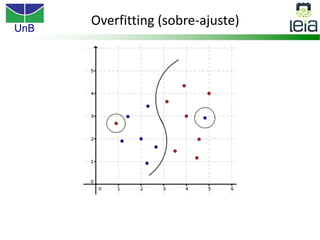
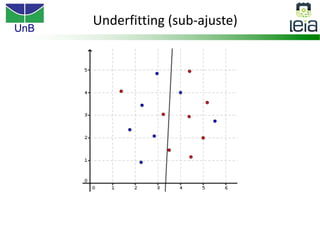
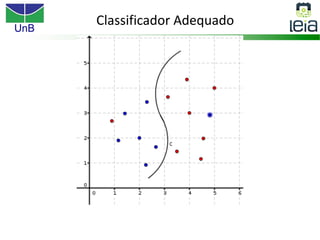
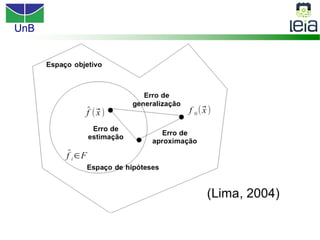
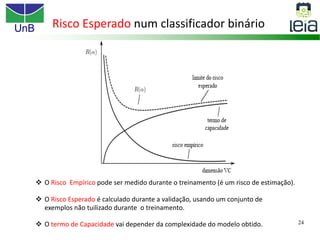
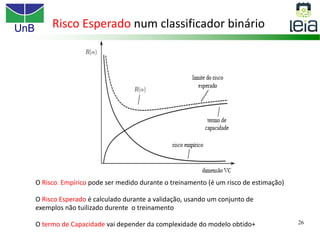
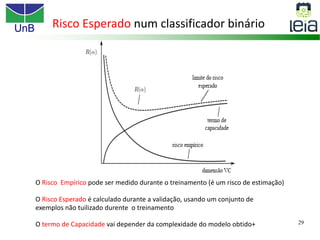
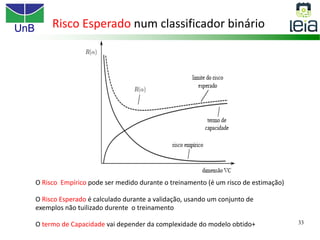
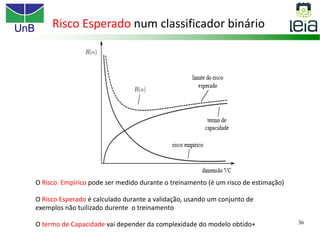
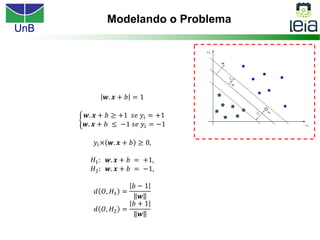
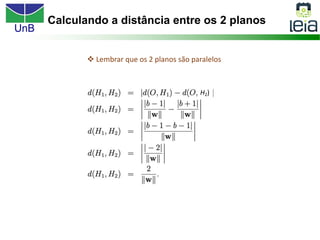
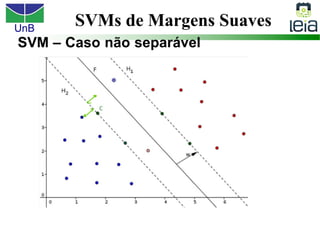
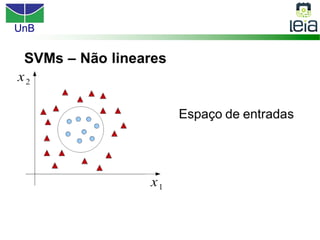
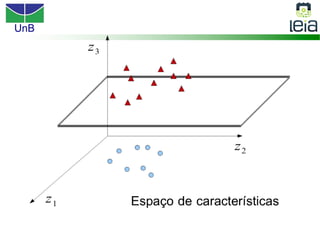
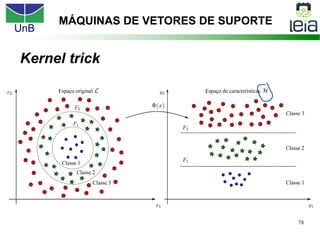
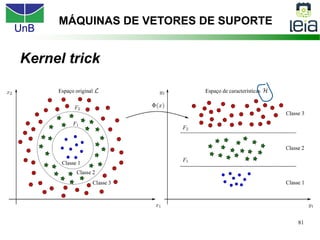
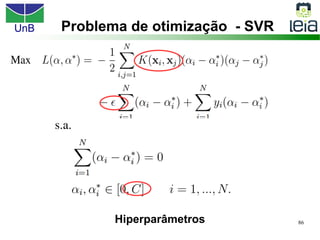
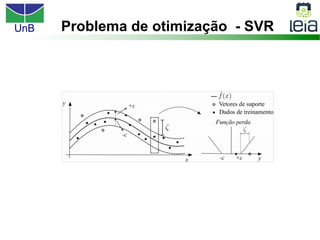
O documento discute sobre máquinas de vetores de suporte (SVMs), apresentando: 1) os tipos de aprendizagem supervisionada, não supervisionada e por reforço; 2) modelos de classificação e regressão para problemas binários e multi-classes; 3) o problema de seleção de parâmetros em SVMs.



































































![[José Ahirton Lopes] Support Vector Machines](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopes-apresentacaosupportvectormachines-180326014519-thumbnail.jpg?width=640&height=640&fit=bounds)


![[José Ahirton Lopes] Treinamento - Árvores de Decisão, SVM e Naive Bayes](https://cdn.slidesharecdn.com/ss_thumbnails/treinamentodeveloperssp-180611021639-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)





