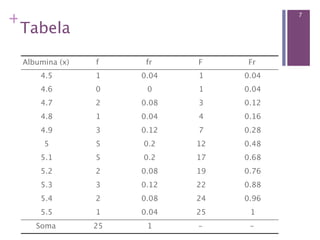
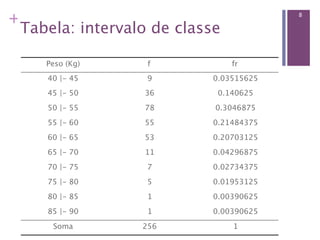
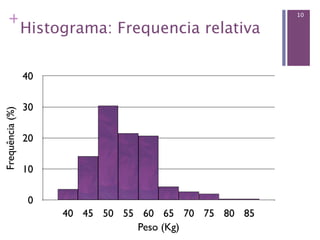
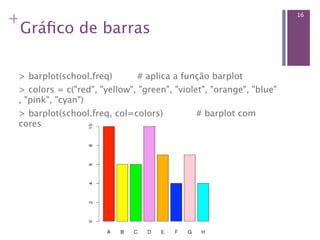
Este documento apresenta conceitos básicos sobre estatística descritiva e inferencial, incluindo: (1) variáveis quantitativas e qualitativas, (2) medidas de tendência central e dispersão, (3) distribuições de frequências. Também mostra como organizar e resumir dados no software R, como criar tabelas, histograma e calcular frequências.










![+ 13
No R
Nacoluna School contém a informação da classificação da
escola de cada um dos pintores. Elas são nomeadas como
A, B, C,... etc. E School é uma variável qualitativa.
> painters$School
[1] A A A A A A A A A A B B B B B B C C C C C C D D D D
[27] D D D D D D E E E E E E E F F F F G G G G G G G H H
[53] H H
Levels: A B C D E F G H
Para
mais informações pode pedir uma ajuda sobre o
pacote.
> help(painters)](https://image.slidesharecdn.com/gabriel-estatistica-aula2-120503201106-phpapp01/85/Gabriel-estatistica-aula-2-13-320.jpg)



![+ 18
Estatística em uma categoria
Qual escola tem a maior média de composições?
#Criar um índice lógico para School C
> c_school = school == "C" # the logical index vector
#Encontrar os subdados de pintores onde a School = C
> c_painters = painters[c_school, ] # seleciona subdados
#Encontrar a média da composição para School C
> mean(c_painters$Composition)
[1] 13.167
Aoinvés de calcular a média para cada School, podemos
usar a função tapply
> tapply(painters$Composition, painters$School, mean)](https://image.slidesharecdn.com/gabriel-estatistica-aula2-120503201106-phpapp01/85/Gabriel-estatistica-aula-2-18-320.jpg)

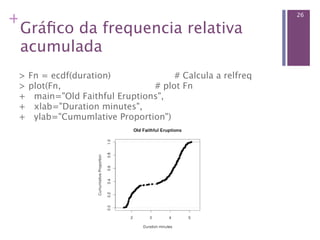
![+ 20
Distribuição de frequências de
dados quantitativos
Saber a amplitude da duração das erupções.
> duration = faithful$eruptions
> range(duration)
[1] 1.6 5.1
Dividir essa amplitude em intervalos.
> breaks = seq(1.5, 5.5, by=0.5) # sequência de meio ponto
> breaks
[1] 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5
Classificar as durações das erupções de acordo com os
intervalos.
> duration.cut = cut(duration, breaks, right=FALSE)
Calcular a frequência das erupções dentro dos intervalos.
> duration.freq = table(duration.cut)](https://image.slidesharecdn.com/gabriel-estatistica-aula2-120503201106-phpapp01/85/Gabriel-estatistica-aula-2-20-320.jpg)





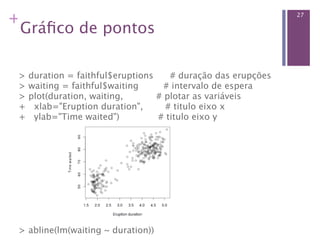
![+ 28
Media, mediana, quartil,
percentil, distância interquartil,
> mean(duration)
[1] 3.4878
> median(duration)
[1] 4
> quantile(duration)
0% 25% 50% 75% 100%
1.6000 2.1627 4.0000 4.4543 5.1000
> quantile(duration, c(.32, .57, .98))
32% 57% 98%
2.3952 4.1330 4.9330
> IQR(duration)
[1] 2.2915
> boxplot(duration, horizontal=TRUE)](https://image.slidesharecdn.com/gabriel-estatistica-aula2-120503201106-phpapp01/85/Gabriel-estatistica-aula-2-28-320.jpg)
























![Estatistica[1]](https://cdn.slidesharecdn.com/ss_thumbnails/estatistica1-120719160006-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














