Baixado 24 vezes







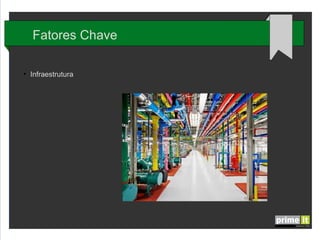













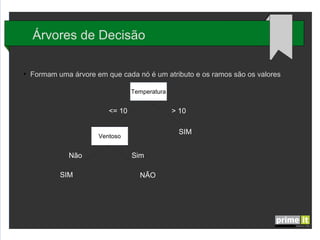

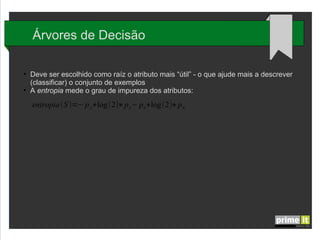
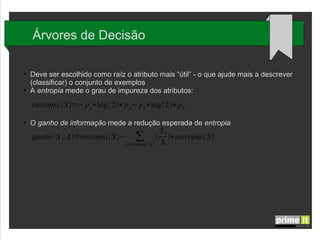





















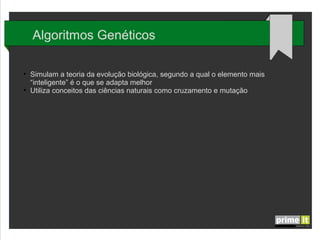
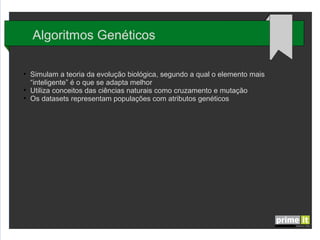
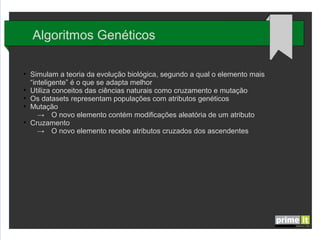

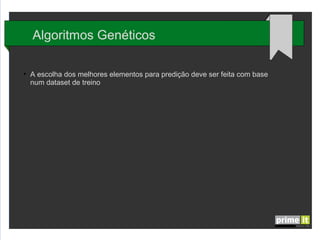
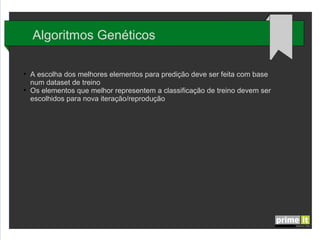

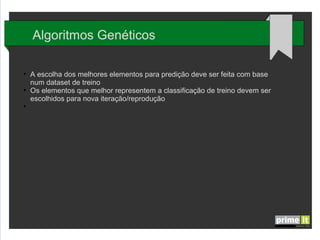









O documento discute Big Data e técnicas de análise de dados. Aborda porque Big Data é importante, fatores-chave como infraestrutura e gestão de dados, e aplicações em empresas. Também explica conceitos como árvores de decisão, redes neurais e algoritmos genéticos.

![Web Data Mining com R: pré-processamento de dados [no R]](https://cdn.slidesharecdn.com/ss_thumbnails/aprocessamentodados-140207143831-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












![[José Ahirton Lopes] Treinamento - Árvores de Decisão, SVM e Naive Bayes](https://cdn.slidesharecdn.com/ss_thumbnails/treinamentodeveloperssp-180611021639-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)

