Reduçao de Dimensionalidade - Guilherme Marson.pdf
O documento apresenta uma agenda para um encontro sobre redução de dimensionalidade e clustering. A agenda inclui introdução ao tema, por que reduzir dimensionalidade, estudo de caso com regressão, seleção de variáveis, PCA e t-SNE.
Reduçao de Dimensionalidade - Guilherme Marson.pdf
2.
JÁ VAI COMEÇAR
ENQUANTOISSO…
- Escolha um lugar confortável para você sentar e se acomodar
- Que tal pegar um snack pra matar a fome, uma água, um chá
- Abra o chat, envie um “olá” e #sentimento de como chega
- Que tal pegar caderno e caneta para anotações
Extração, Transformação e Carga de Dados
_
QUE
BOM
QUE
VOCÊ
VEIO
Quem ainda nãodigitou, abra o Chat e coloque um #sentimento que
chega aqui hoje
CHECK-IN &
WARMUP
5.
RELEMBRANDO OS ACORDOS
Maisalgum acordo?
- Tenha ao alcance: carregador, snacks, água e fone de ouvido
- Cuidado com o horário: procure entrar na sala um pouco antes do horário
- Luz, câmera, ação! Mantenha a câmera aberta para a gente se ver e se
conhecer.
- Participe! Não esqueça do “leadership”. Se coloquem, falem, chutem,
participem! Usem tanto o chat, aberto ou privado, como o microfone para isso.
- Facilitação está aqui para ajudar: além do fluxo do conteúdo e do tempo,
conto com vocês para me dizerem se algo não está claro, pode ser melhor ou
só para trocar uma ideia =)
- Autocuidado, cuide da sua energia para estar presente na hora da aula
Guilherme Marson
Data andInsights Manager
no Mercado Livre
Clustering - Modelagem e
Algoritmos + PCA
https:/
/www.linkedin.com/in/gmarson
8.
AGENDA
● Bloco 1:O que é redução de dimensionalidade?
● Bloco 2: Por que reduzir dimensionalidade?
● Bloco 3: Estudo de caso: uma regressão para entender
clusterização (redução de dimensionalidade)
● Bloco 4: Seleção de Variáveis
+ Intervalo - 10 min
● Bloco 4: PCA (1933)
● Bloco 5: t-sne (2008)
_
NOSSO
ENCONTRO
DE
HOJE
9.
Metodologia: Stress +Rest = Growth
“Peak Performance: Elevate Your Game, Avoid Burnout, and Thrive with the New Science of Success”
Brad Stulberg e Steve Magness
Redução de
Dimensionalidade -
Introdução
❖O número de variáveis (features) de um
dataset é chamado de dimensionalidade
do dataset
❖ Reduzir a dimensionalidade consiste em
reduzir a quantidade de variáveis de um
dataset
❖ Técnicas para redução de
dimensionalidade:
➢ Seleção de Variáveis
➢ Fatorização Matricial (PCA)
➢ Aprendizado Múltiplo (t-sne)
➢ Autoencoder
12.
Redução de
Dimensionalidade -
Introdução
❖O número de variáveis (features) de um
dataset é chamado de dimensionalidade
do dataset
❖ Reduzir a dimensionalidade consiste em
reduzir a quantidade de variáveis de um
dataset
❖ Técnicas para redução de
dimensionalidade:
➢ Seleção de Variáveis
➢ Fatorização Matricial
➢ Aprendizado Múltiplo
➢ Autoencoder
13.
Por que reduzir
dimensionalidade?
❖ Dificuldade em visualizar objetos com
mais de 3 dimensões
1 Dimension 2 Dimensions 3 Dimensions
4 Dimensions 5 Dimensions
14.
Por que reduzir
dimensionalidade?
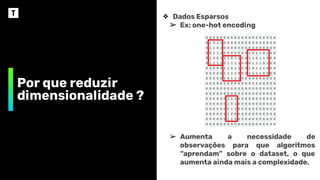
❖ Dados Esparsos
➢ Ex: one-hot encoding
➢ Aumenta a necessidade de
observações para que algoritmos
“aprendam” sobre o dataset, o que
aumenta ainda mais a complexidade.
Por que reduzir
dimensionalidade?
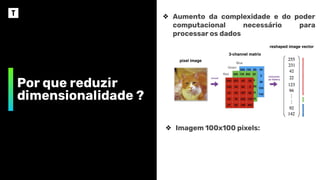
❖ Aumento da complexidade e do poder
computacional necessário para
processar os dados
❖ Imagem 100x100 pixels:
18.
Por que reduzir
dimensionalidade?
❖ Aumento da complexidade e do poder
computacional necessário para
processar os dados
❖ Imagem 100x100 pixels:
➢ Red: 100x100=10.000
➢ Green: 100x100=10.000
➢ Blue: 100x100=10.000
19.
Por que reduzir
dimensionalidade?
❖ Aumento da complexidade e do poder
computacional necessário para
processar os dados
❖ Imagem 100x100 pixels:
➢ Red: 100x100=10.000
➢ Green: 100x100=10.000
➢ Blue: 100x100=10.000
➢ Total: 30.000 features
O problema
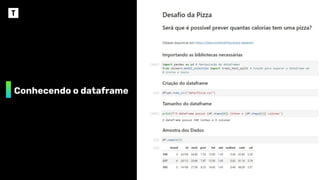
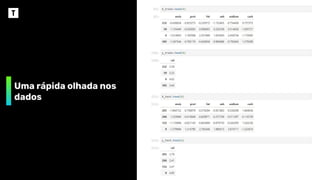
❖ Quantascalorias tem uma pizza?
➢ Precisamos de um dataset*
brand Marca da Pizza
id Identificador
mois Quantidade de água por 100g
prot Quantidade de proteína por 100g
fat Quantidade de gordura por 100g
ash Quantidade de farinha não incorporada por 100g
sodium Quantidade de sódio por 100g
carb Quantidade de carboidratos por 100g
cal Quantidade de calorias por 100g
* https:/
/data.world/sdhilip/pizza-datasets
25.
O problema
❖ Quantascalorias tem uma pizza?
➢ Precisamos de um dataset*
brand Marca da Pizza
id Identificador
mois Quantidade de água por 100g
prot Quantidade de proteína por 100g
fat Quantidade de gordura por 100g
ash Quantidade de farinha não incorporada por 100g
sodium Quantidade de sódio por 100g
carb Quantidade de carboidratos por 100g
cal Quantidade de calorias por 100g
❖ Será que essas variáveis podem ser
utilizadas como preditores de calorias?
❖ Utilizaremos apenas as variáveis
numéricas
* https:/
/data.world/sdhilip/pizza-datasets
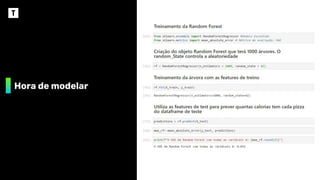
Seleção de variáveis
❖Este processo consiste em selecionar apenas
as variáveis mais importantes para o modelo,
ou seja, os melhores preditores.
❖ Para isso, começamos calculando a
importância de cada variável:
37.
Seleção de variáveis
❖Este processo consiste em selecionar apenas
as variáveis mais importantes para o modelo,
ou seja, os melhores preditores.
❖ Para isso, começamos calculando a
importância de cada variável:
38.
Seleção de variáveis
❖Este processo consiste em selecionar apenas
as variáveis mais importantes para o modelo,
ou seja, os melhores preditores.
❖ Para isso, começamos calculando a
importância de cada variável:
39.
Seleção de variáveis
❖Este processo consiste em selecionar apenas
as variáveis mais importantes para o modelo,
ou seja, os melhores preditores.
❖ Para isso, começamos calculando a
importância de cada variável:
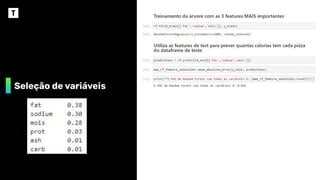
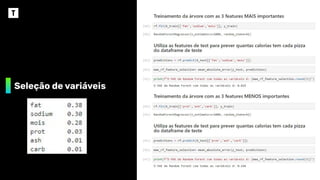
❖ As 3 primeiras variáveis são muito mais
importantes para o modelo do que as últimas 3
❖ Vamos analisar qual o comportamento do
modelo ao utilizarmos apenas as 3 variáveis
mais importantes
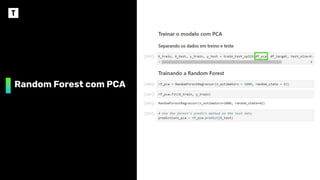
Acompanhamento dos testes
RandomForest
Todas variáveis
padronizadas
Apenas as 3 variáveis
mais importantes
Apenas as 3 variáveis
menos importantes
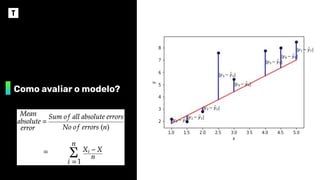
MAE 0,031 0,025 0,144
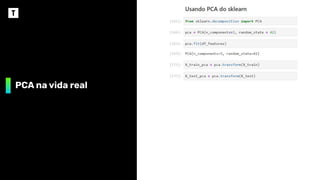
PCA: Principal ComponentAnalysis
❖ PCA é uma técnica de redução de dimensionalidade que geralmente
transforma uma grande quantidade de variáveis em um conjunto menor,
que ainda contém grande parte da informação do conjunto original
❖ O custo de reduzir o número de variáveis normalmente é pago em
acuracidade, mas o ponto interessante é que essa perda de acuracidade
vem acompanhada de ganho de simplicidade. Tudo isso por que datasets
menores são:
➢ Mais fáceis de explorar
➢ Mais simples de serem visualizados
➢ Mais rápidos para modelos de M.L.
❖ Em resumo, a ideia do PCA é: reduza o número de variáveis, enquanto
preserva o máximo de informação possível
❖ Os componentes principais não são interpretáveis
47.
PCA: Etapas doProcesso
1. Padronize o intervalo das variáveis input
2. Calcule a matriz de covariância para identificar
correlações
3. Calcule os autovalores e autovetores da matriz
de covariância para identificar os componentes
principais
4. Crie um vetor de features para decidir quais
componentes principais manter
5. Transforme os dados utilizando os eixos dos
componentes principais
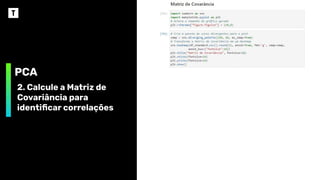
PCA
2. Calcule aMatriz de
Covariância para
identificar correlações
56.
PCA
2. Calcule aMatriz de
Covariância para
identificar correlações
57.
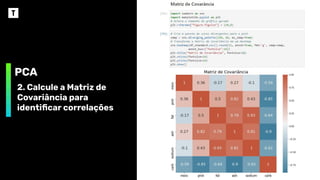
PCA
2. Calcule aMatriz de
Covariância para
identificar correlações
58.
PCA
2. Calcule aMatriz de
Covariância para
identificar correlações
59.
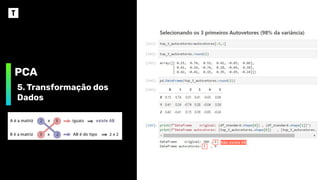
PCA
3. Calcule osautovalores e
autovetores da Matriz de
Covariância
Componentes Principais
❖ São novas variáveis que são construídas como
combinações lineares ou misturas das variáveis
iniciais
❖ X variáveis originais geram os mesmos X
componentes principais
❖ São não-correlacionadas
❖ Grande parte da informação das variáveis
originais está concentrada nos primeiros
componentes
❖ Em seguida ele tenta adicionar o máximo de
informação restante possível na segunda
componente e assim até o final das X variáveis
❖ Os componentes principais não são
interpretáveis
60.
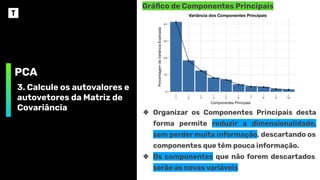
PCA
3. Calcule osautovalores e
autovetores da Matriz de
Covariância
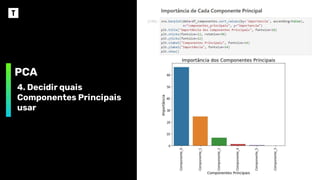
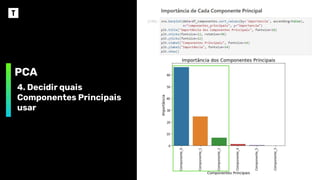
Gráfico de Componentes Principais
Componentes Principais
Porcentagem
de
Variância
Explicada
Variância dos Componentes Principais
❖ Organizar os Componentes Principais desta
forma permite reduzir a dimensionalidade,
sem perder muita informação, descartando os
componentes que têm pouca informação.
❖ Os componentes que não forem descartados
serão as novas variáveis
61.
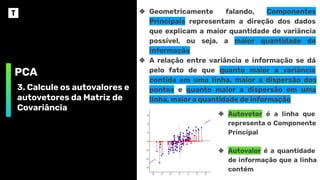
PCA
3. Calcule osautovalores e
autovetores da Matriz de
Covariância
❖ Geometricamente falando, Componentes
Principais representam a direção dos dados
que explicam a maior quantidade de variância
possível, ou seja, a maior quantidade de
informação
❖ A relação entre variância e informação se dá
pelo fato de que quanto maior a variância
contida em uma linha, maior a dispersão dos
pontos e quanto maior a dispersão em uma
linha, maior a quantidade de informação
❖ Autovetor é a linha que
representa o Componente
Principal
❖ Autovalor é a quantidade
de informação que a linha
contém
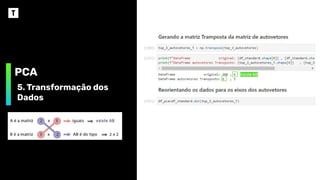
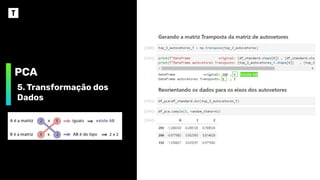
PCA
5. Transformação dos
Dados
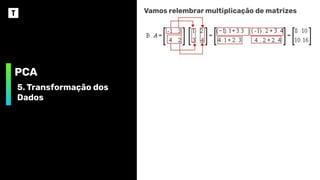
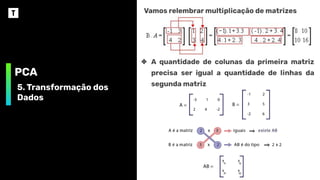
Vamosrelembrar multiplicação de matrizes
❖ A quantidade de colunas da primeira matriz
precisa ser igual a quantidade de linhas da
segunda matriz
74.
PCA
5. Transformação dos
Dados
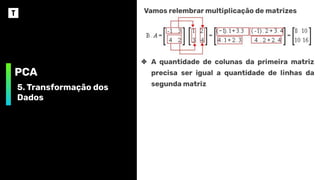
Vamosrelembrar multiplicação de matrizes
❖ A quantidade de colunas da primeira matriz
precisa ser igual a quantidade de linhas da
segunda matriz
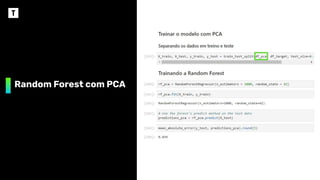
Acompanhamento dos testes
RandomForest
Todas variáveis
padronizadas
Apenas as 3 variáveis
mais importantes
Apenas as 3 variáveis
menos importantes
Com variáveis
do PCA
MAE 0,031 0,025 0,144 0,034
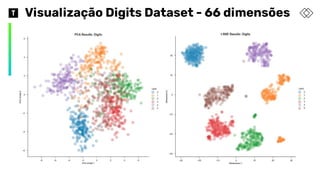
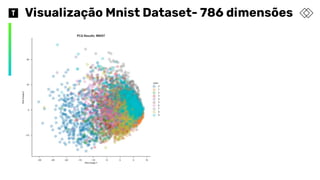
t-sne: t-distributed stochasticneighbor embedding
❖ Técnica não supervisionada e não-linear
❖ Utilizada principalmente para exploração e visualização de dados de alta
dimensionalidade
❖ t-sne traz uma aproximação ou intuição de como os dados estão organizados
em um espaço de alta dimensão
❖ Com ele é possível ganhar tempo, pois é preciso gerar muito menos gráficos
para entender os dados
❖ t-sne encontra padrões nos dados através da identificação de clusters
baseados na similaridade dos dados.
❖ Mesmo parecendo um algoritmo de clustering, ele é um de redução de
dimensionalidade, pois mapeia os dados para um espaço com menor
dimensionalidade.
❖ Variáveis input não são identificáveis.
Acompanhamento dos testes
RandomForest
Todas variáveis
padronizadas
Apenas as 3 variáveis
mais importantes
Apenas as 3 variáveis
menos importantes
Com variáveis
do PCA
Com Variáveis
t-SNE
MAE 0,031 0,025 0,144 0,034 0,155
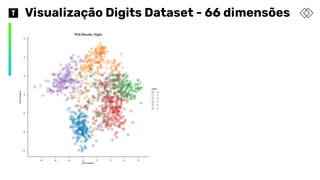
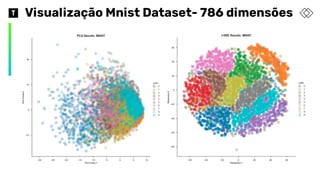
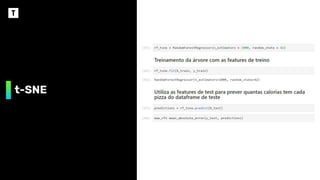
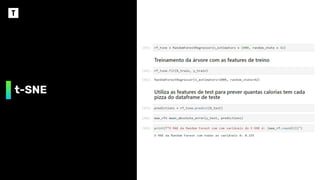
Como usar ot-SNE em Produção
❖ Treinar a t-SNE até chegar em uma
situação onde os grupos estejam bem
separados
❖ Utilizar os valores das variáveis
Dimension 1 e Dimension 2 como target
de duas regressões que utilizem as
features originais do dataset:
➢ Regressão1 -> Target Dimension 1
➢ Regressão2 -> Target Dimension 2
❖ A combinação das respostas das
regressões implicará na posição do
gráfico ao lado, que poderá ser utilizado
para classificar o dígito