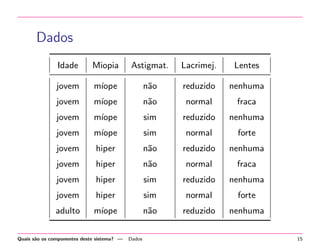
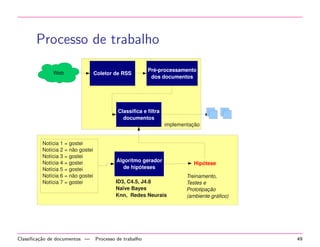
Baixado 13 vezes



















![´
Algoritmos Indutores de Arvores de
Decis˜o
a
• Que algoritmo utilizar para gerar hip´teses na
o
forma de ´rvores de decis˜o?
a
a
• ID3, C4.5[2]: s˜o algoritmos indutores de ´rvore de
a
a
decis˜o, top-down, recursivos e que fazem uso do
a
conceito de entropia para identificar os melhores
atributos que representam o conjunto de dados.
Quais s˜o os componentes deste sistema? —
a
´
Algoritmos Indutores de Arvores de Decis˜o
a
21](https://image.slidesharecdn.com/adatatextmining-140204134706-phpapp01/85/Data-Text-and-Web-Mining-21-320.jpg)

![Sistema Especialista: Regras de Produ¸˜o
ca
• Baseado na premissa que o processo de tomada de
decis˜o humano pode ser modelado por meio de regras
a
˜
do tipo SE condi¸˜es ENTAO conclus˜es [FACA
co
o
¸
a¸˜es]
co
• Convertendo uma ´rvore de decis˜o em regras de
a
a
produ¸˜o:
ca
Quais s˜o os componentes deste sistema? —
a
Sistema Especialista: Regras de Produ¸˜o
ca
23](https://image.slidesharecdn.com/adatatextmining-140204134706-phpapp01/85/Data-Text-and-Web-Mining-23-320.jpg)
































![References
[1] Tom M. Mitchell. Machine Learning. McGraw-Hill, 1997.
[2] J. R. Quinlan. Knowledge Acquisition for Knowledge-Based
Systems, chapter Simplifying Decision Trees. Academic
Press, 1988.
[3] Stuart J. Russel and Peter Norvig. Artificial intelligence: a
modern approach. Prentice-Hall, 2 edition, 2003.
[4] Ian H. Witten and Eibe Frank. Data Mining: Practical
Machine Learning Tools and Techniques. Elsevier, second
edition, 2005.
56-1](https://image.slidesharecdn.com/adatatextmining-140204134706-phpapp01/85/Data-Text-and-Web-Mining-57-320.jpg)

O documento apresenta os conceitos de mineração de dados, texto e web. Discute a importância do tema e apresenta alguns exemplos de aplicações como extrair conhecimento médico a partir de registros, agrupar notícias e identificar padrões de navegação em sites.





![Web Data Mining com R: pré-processamento de dados [no R]](https://cdn.slidesharecdn.com/ss_thumbnails/aprocessamentodados-140207143831-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![Pré-processamento [no R] e Análise Exploratória - Curso de Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/analiseexploratoriav2-150622235900-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)













