Transferir como PDF, PPTX






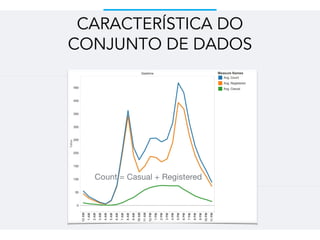
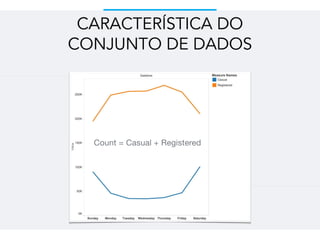


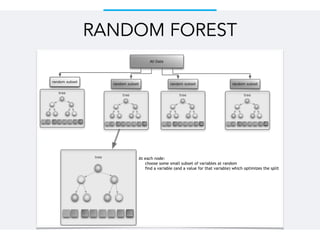

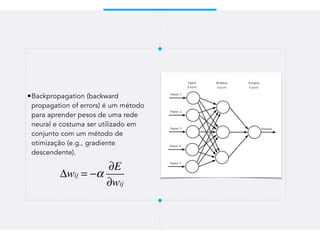
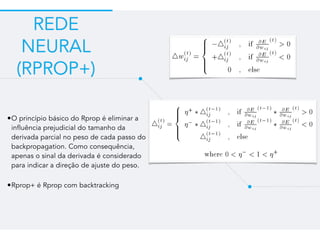
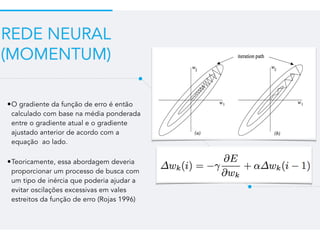


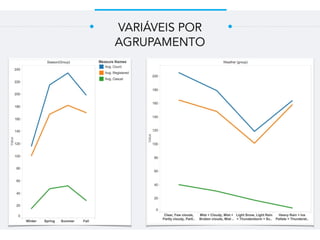
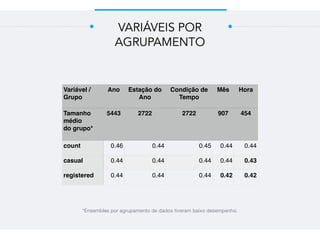
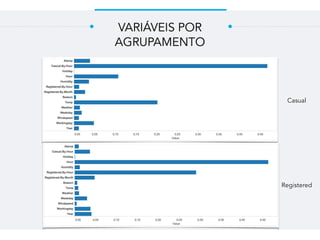
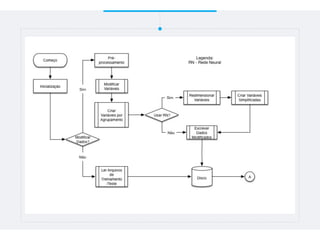
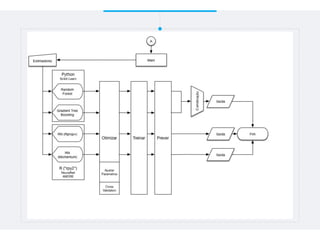
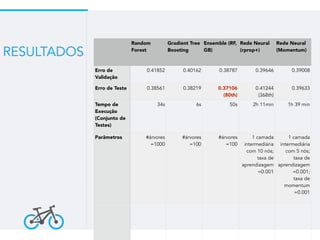




Este documento resume um trabalho de graduação sobre aprendizagem de máquina para previsão de demanda em um sistema de compartilhamento de bicicletas. O objetivo era prever o número total de bicicletas retiradas em um determinado horário usando técnicas como ensembles, random forest, gradient tree boosting e redes neurais. Os resultados mostraram que gradient tree boosting teve o menor erro de validação, enquanto random forest foi mais rápido. Redes neurais tiveram desempenho inferior devido à dificuldade na parametriza


























![[TDC2016] Apache SparkMLlib: Machine Learning na Prática](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachesparkmllibmachinelearningnapratica-160711163948-thumbnail.jpg?width=640&height=640&fit=bounds)








