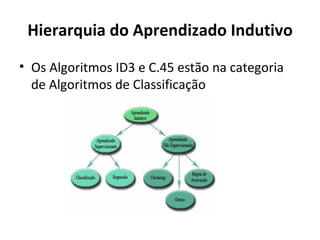
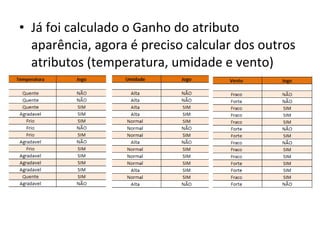
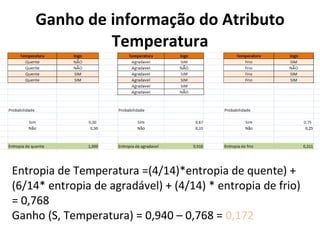
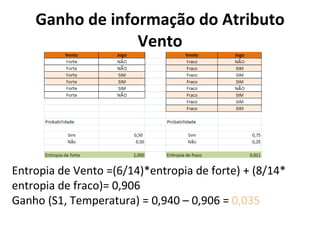
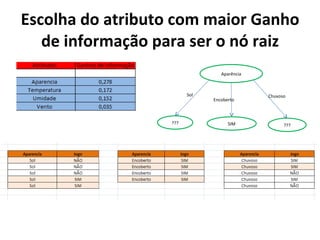
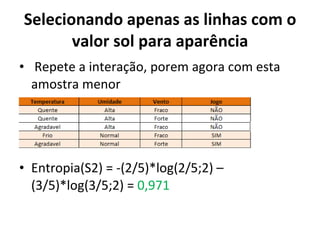
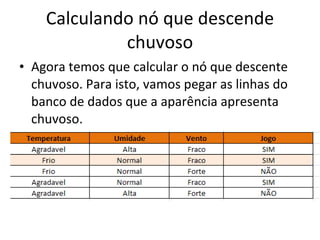
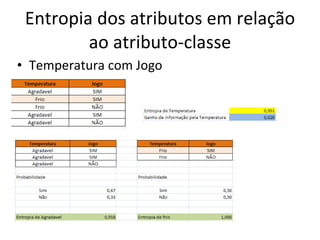
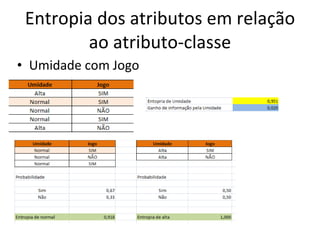
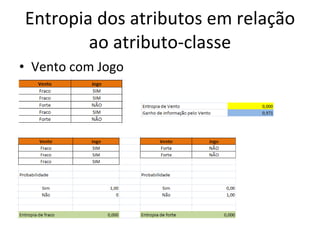
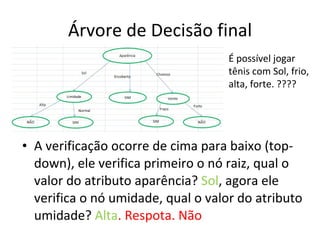
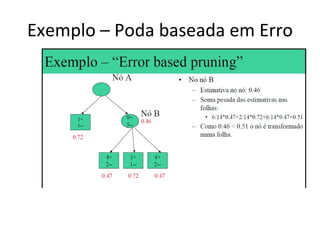
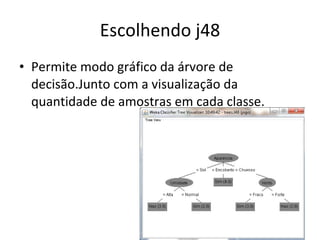
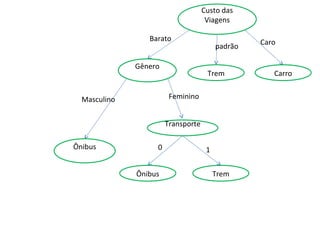
O documento descreve os algoritmos ID3 e C4.5 para mineração de dados, que constroem árvores de decisão induzidas. O ID3 usa entropia para selecionar o melhor atributo divisor, enquanto o C4.5 lida com atributos contínuos e usa razão de ganho para gerar árvores menos complexas, além de permitir poda pós-construção.














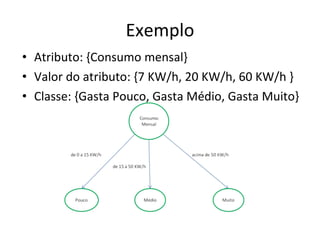

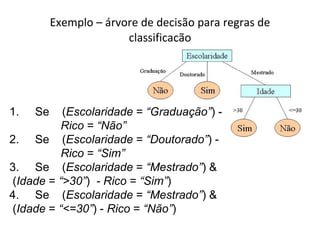






![Transformando valores contínuos de atributos em valores discretos temperatura = [6 25 30 50 0 32 3 10 5 32] Definir o valor maximo e minimo da amostra Dividir a soma do valor Max e Min pelo quantidade de classes. Ex: Quente, normal e frio ou seja, (0 + 50) / 3 = 16,66](https://image.slidesharecdn.com/gilcimarapresentaocommodificaes-110608091523-phpapp02-110620214245-phpapp01/85/Algoritmo_ID3_e_C-45_Gilcimar-24-320.jpg)



![Entropia dos dados da amostra Entropia dos Dados (S1) =-0,64* LOG(0,64;2)- 0,36*LOG(0,36;2) = 0,940 Obs: se a entropia estiver fora do intervalo [0,1], alguma coisa no calculo está errado](https://image.slidesharecdn.com/gilcimarapresentaocommodificaes-110608091523-phpapp02-110620214245-phpapp01/85/Algoritmo_ID3_e_C-45_Gilcimar-29-320.jpg)







































































![[José Ahirton Lopes] Treinamento - Árvores de Decisão, SVM e Naive Bayes](https://cdn.slidesharecdn.com/ss_thumbnails/treinamentodeveloperssp-180611021639-thumbnail.jpg?width=640&height=640&fit=bounds)





















