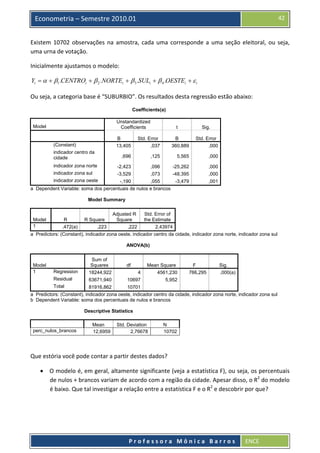
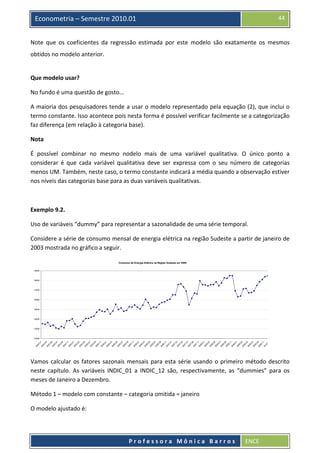
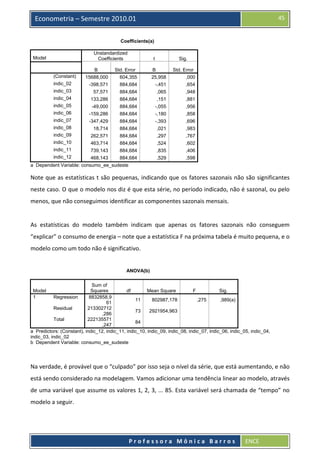
Baixado 91 vezes





1. O documento descreve modelos de regressão com variáveis binárias, explicando como especificar corretamente variáveis qualitativas com m categorias para evitar colinearidade. 2. É apresentado um exemplo usando dados eleitorais do Rio de Janeiro para ilustrar como interpretar os coeficientes em modelos com e sem termo constante. 3. Os resultados mostram que a região da cidade influencia os percentuais de votos brancos e nulos, sendo menores nas zonas Sul e Norte.















































































