Baixado 13 vezes





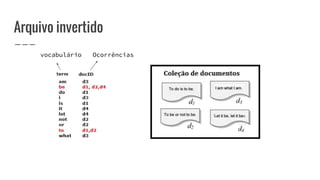

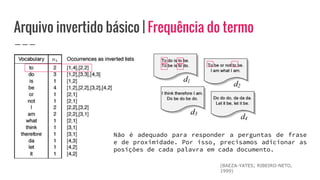
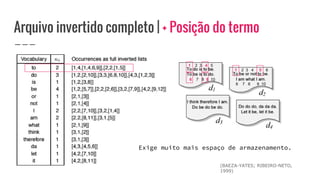



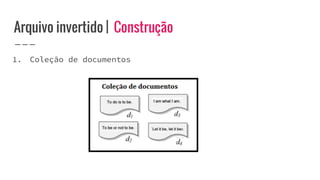
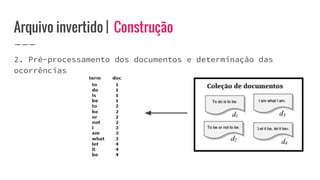
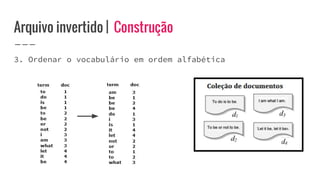
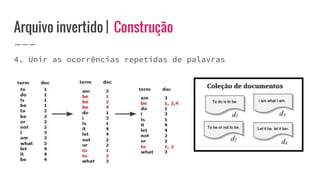

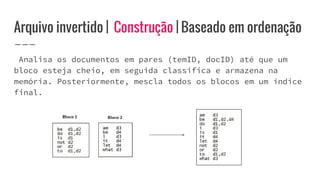

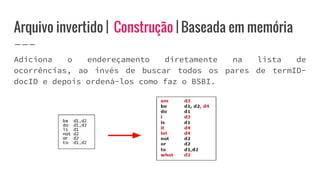

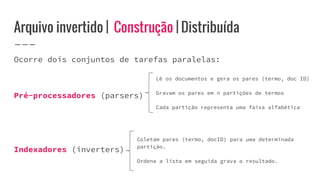
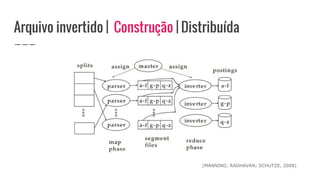



O documento discute o conceito de arquivo invertido, que é um mecanismo de indexação de documentos baseado em palavras para facilitar buscas. Ele detalha a estrutura e construção do arquivo invertido, abordando vocabulário e ocorrências, assim como métodos de construção como ordenação por blocos e divisões distribuídas. Além disso, são apresentados desafios e soluções para a construção de índices em coleções dinâmicas e grandes conjuntos de dados.



























