








![Um Pouco de História
…
void drawBox(void)
{
int i;
for (i = 0; i < 6; i++) {
glBegin(GL_QUADS);
glNormal3fv(&n[i][0]);
glVertex3fv(&v[faces[i][0]][0]);
glVertex3fv(&v[faces[i][1]][0]);
glVertex3fv(&v[faces[i][2]][0]);
glVertex3fv(&v[faces[i][3]][0]);
glEnd();
}
}
…](https://image.slidesharecdn.com/senacads2016minicursofilipov1-161018182257/75/Desenvolvendo-Aplicacoes-de-Uso-Geral-para-GPU-com-CUDA-16-2048.jpg)








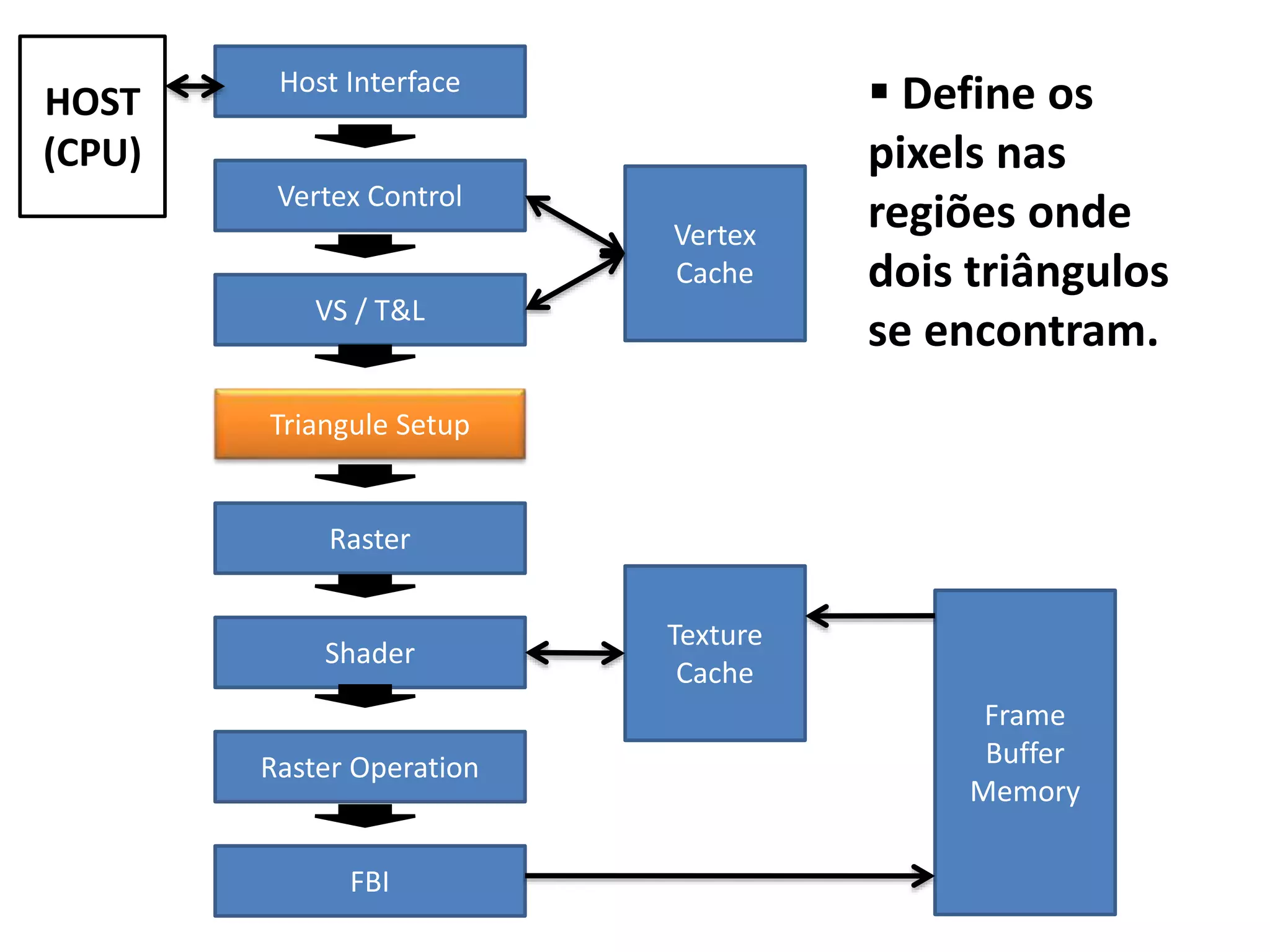
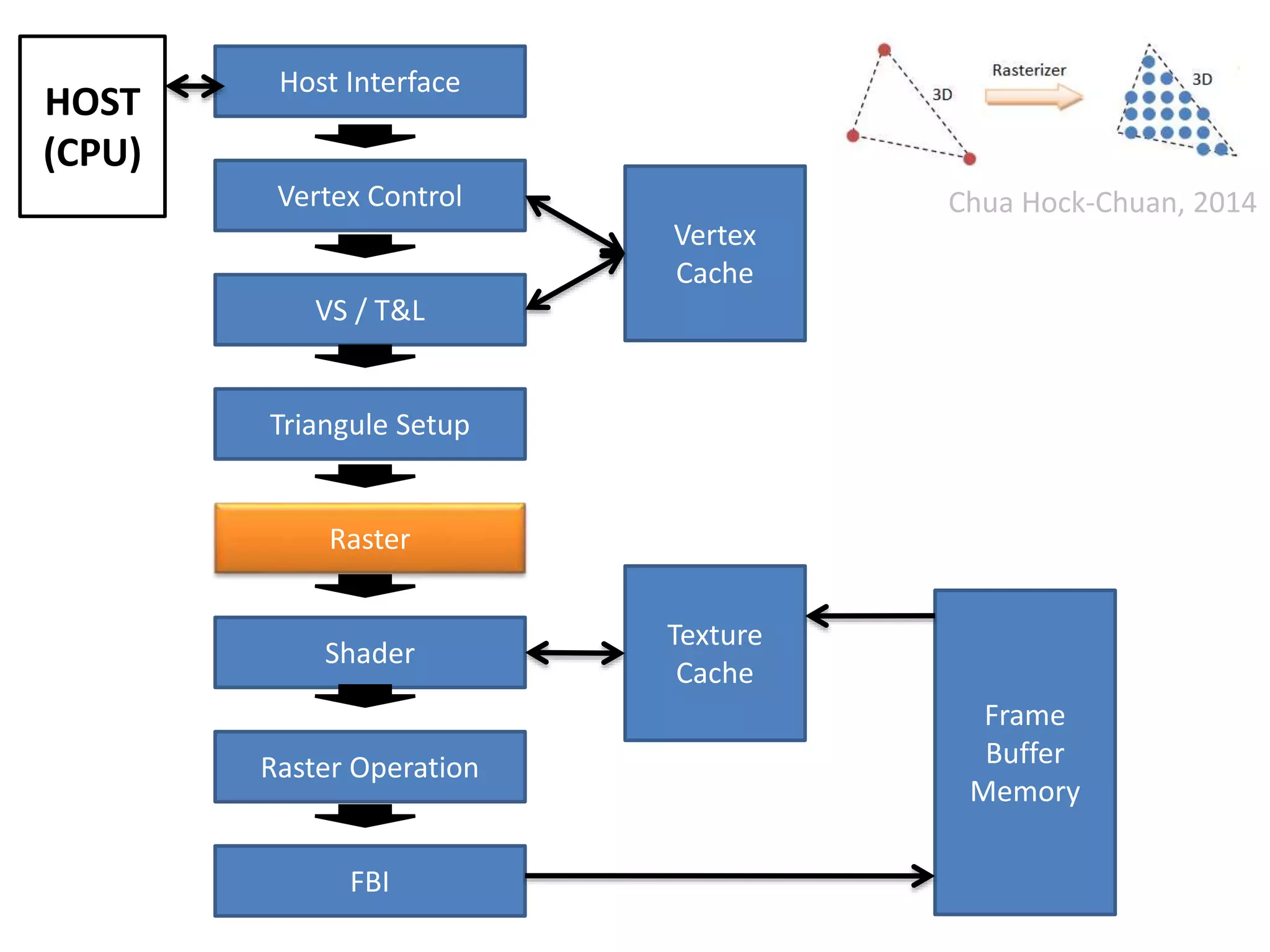
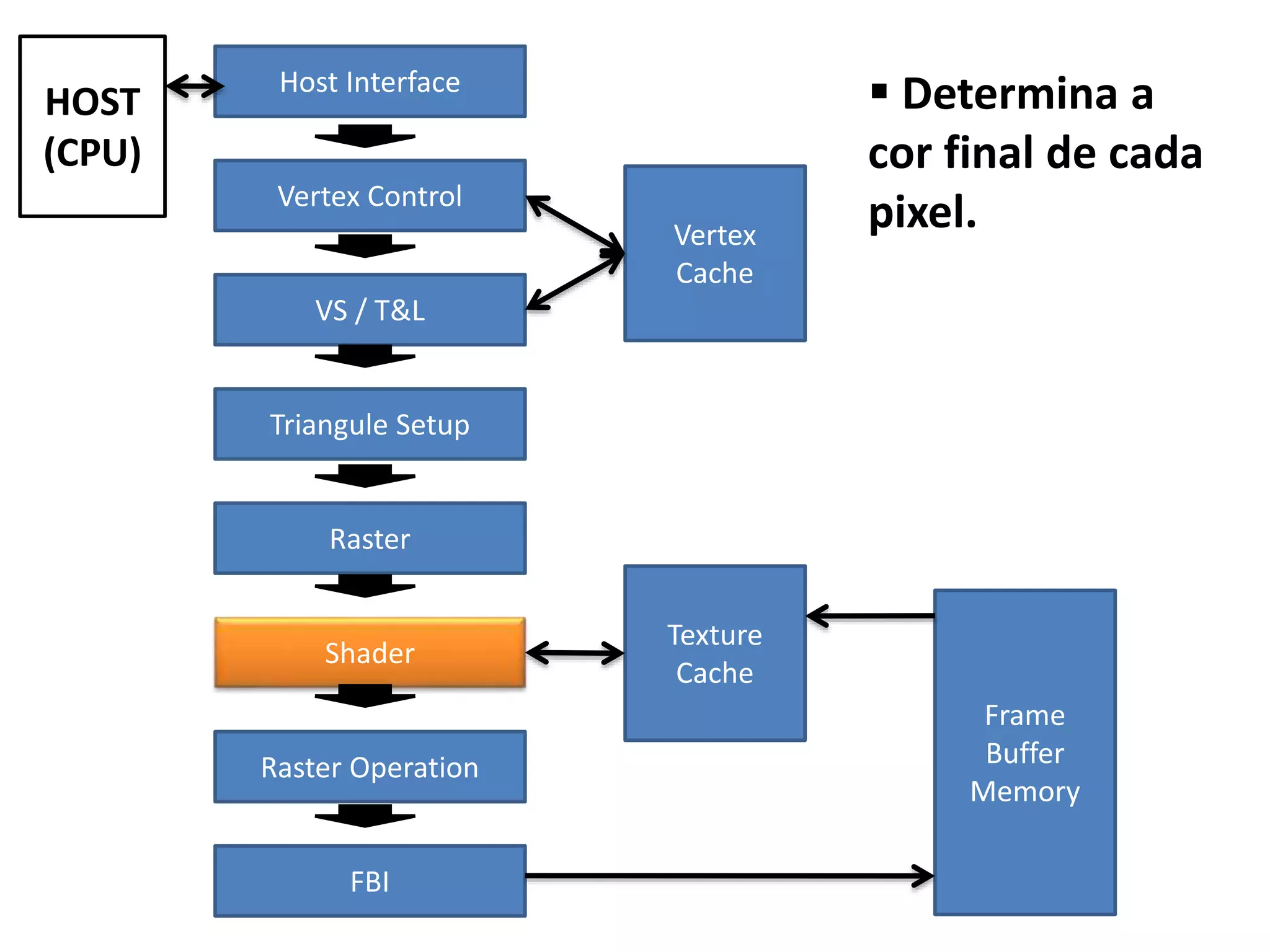
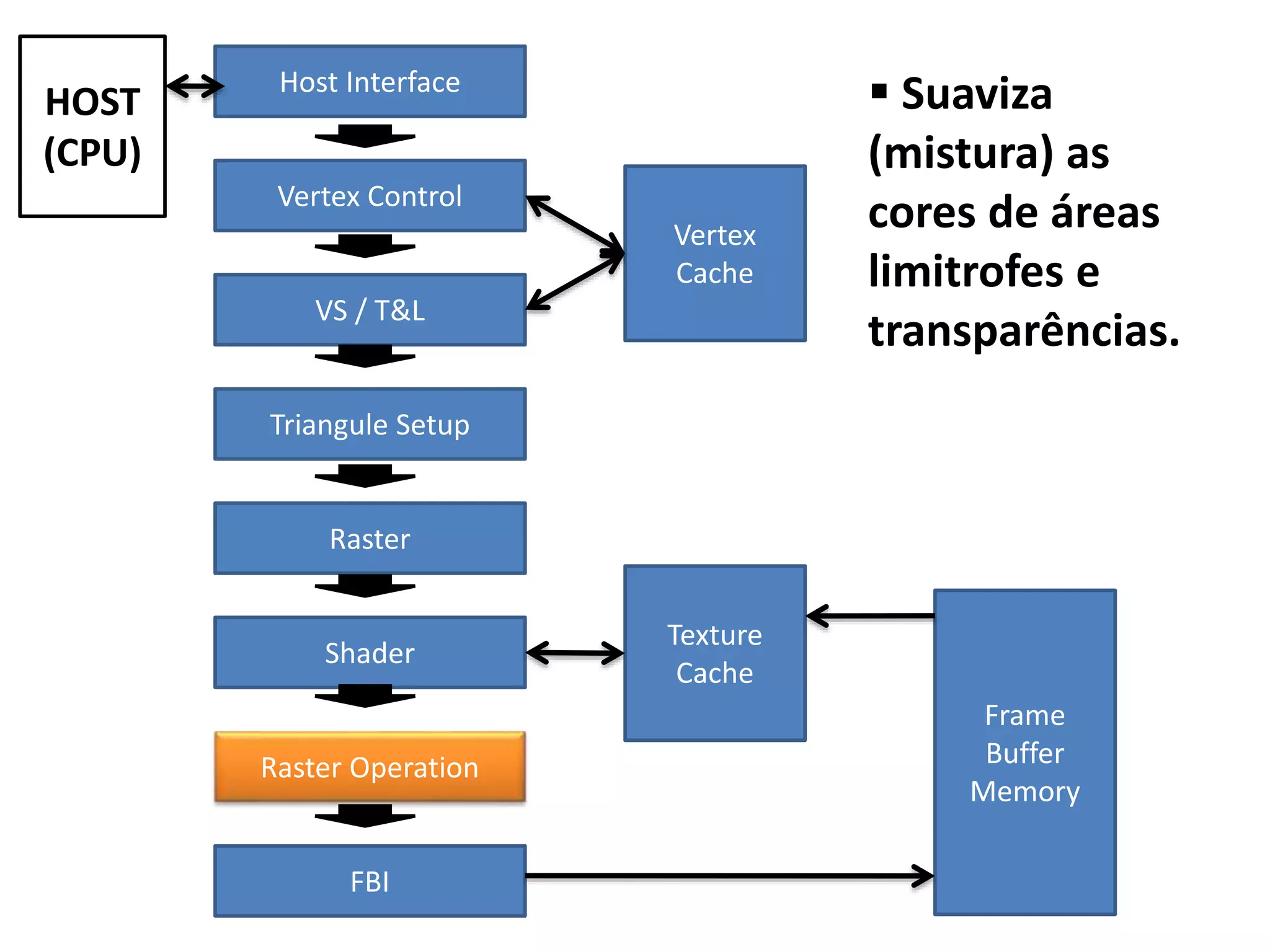
















![Soma de Vetores
Programação GPU com CUDA
c[0] = a[0] + b[0];
Bloco 0
c[1] = a[1] + b[1];
Bloco 1
c[2] = a[2] + b[2];
Bloco 2
c[3] = a[3] + b[3];
Bloco 3](https://image.slidesharecdn.com/senacads2016minicursofilipov1-161018182257/75/Desenvolvendo-Aplicacoes-de-Uso-Geral-para-GPU-com-CUDA-64-2048.jpg)










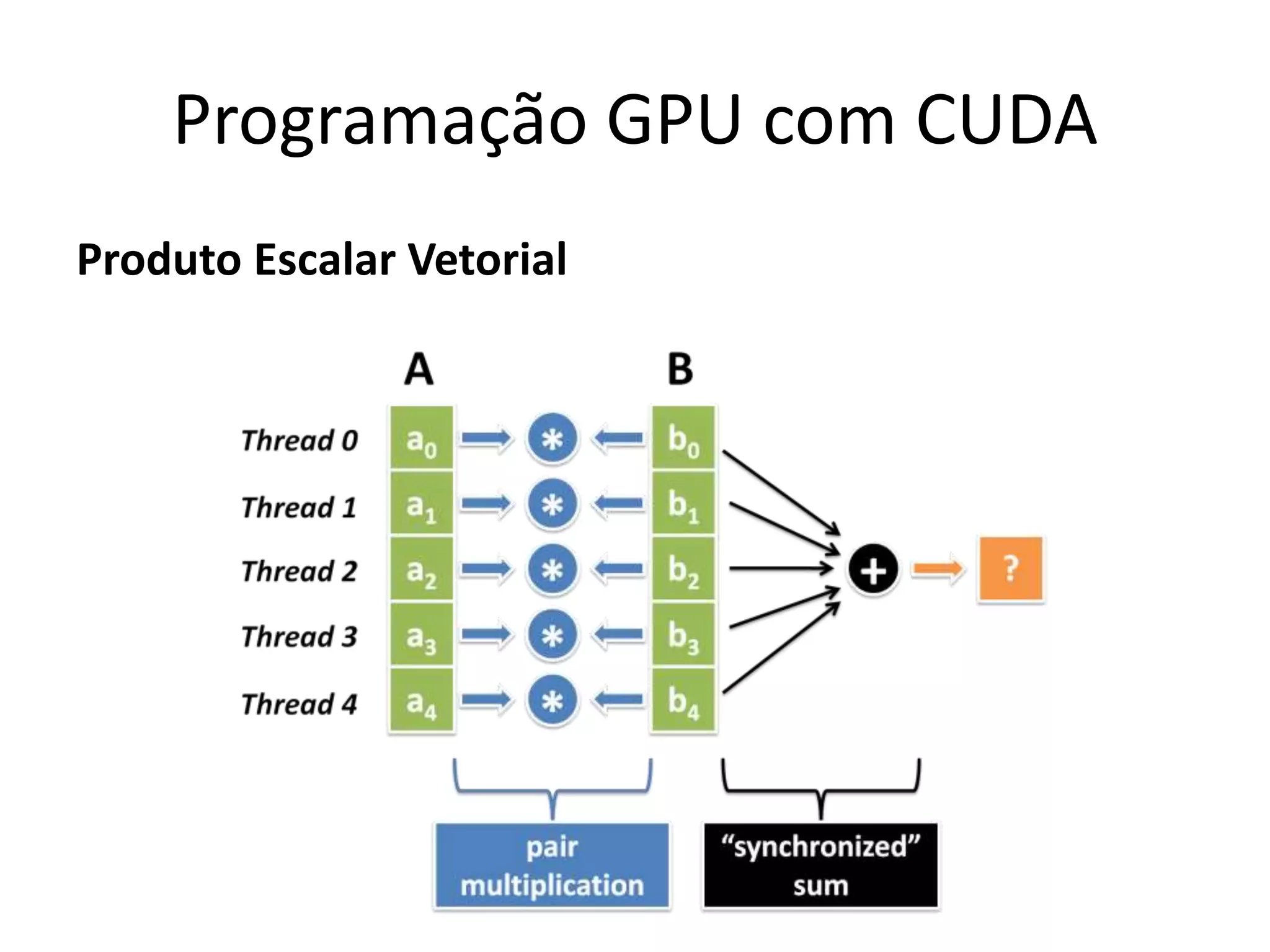

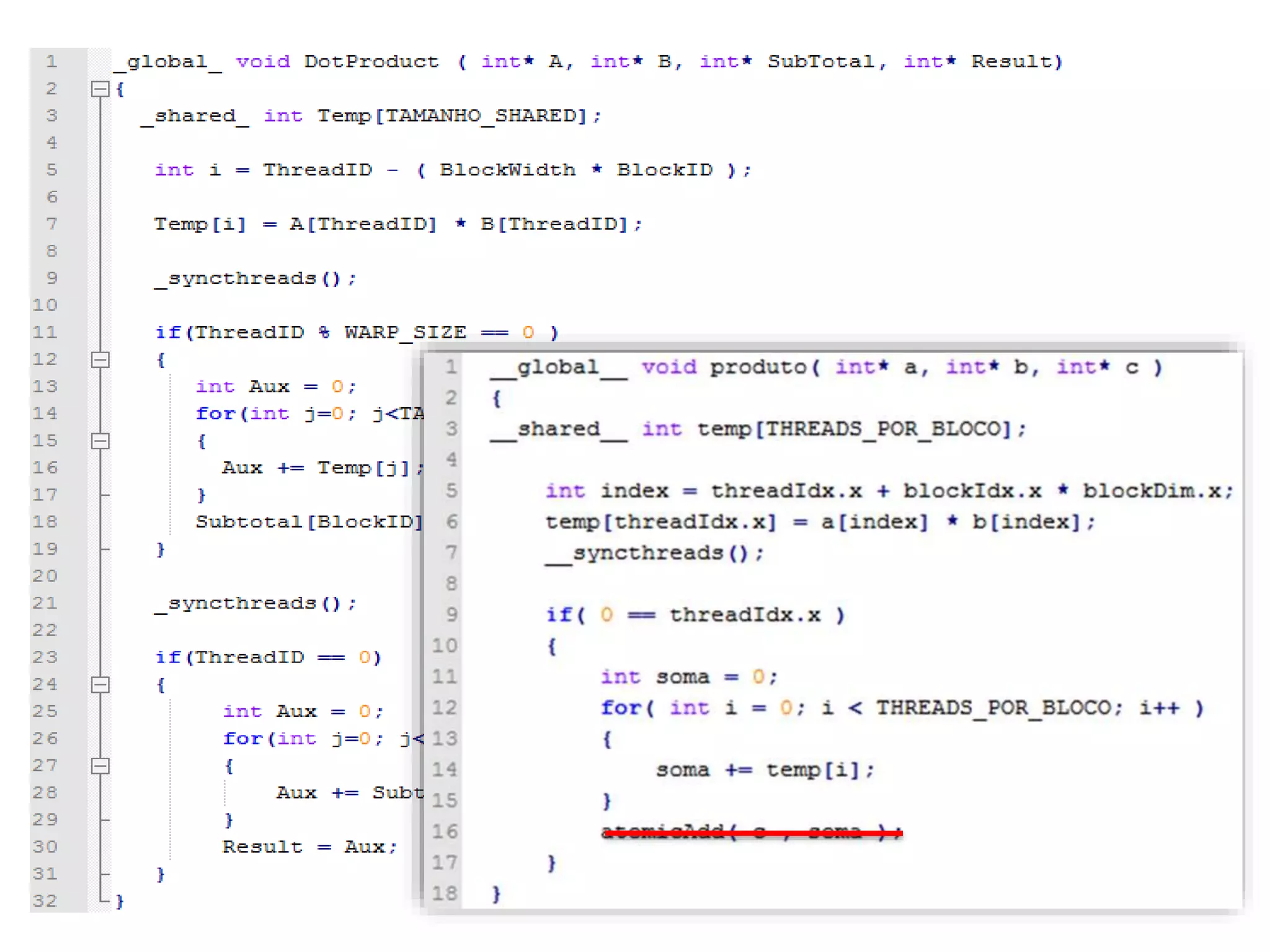

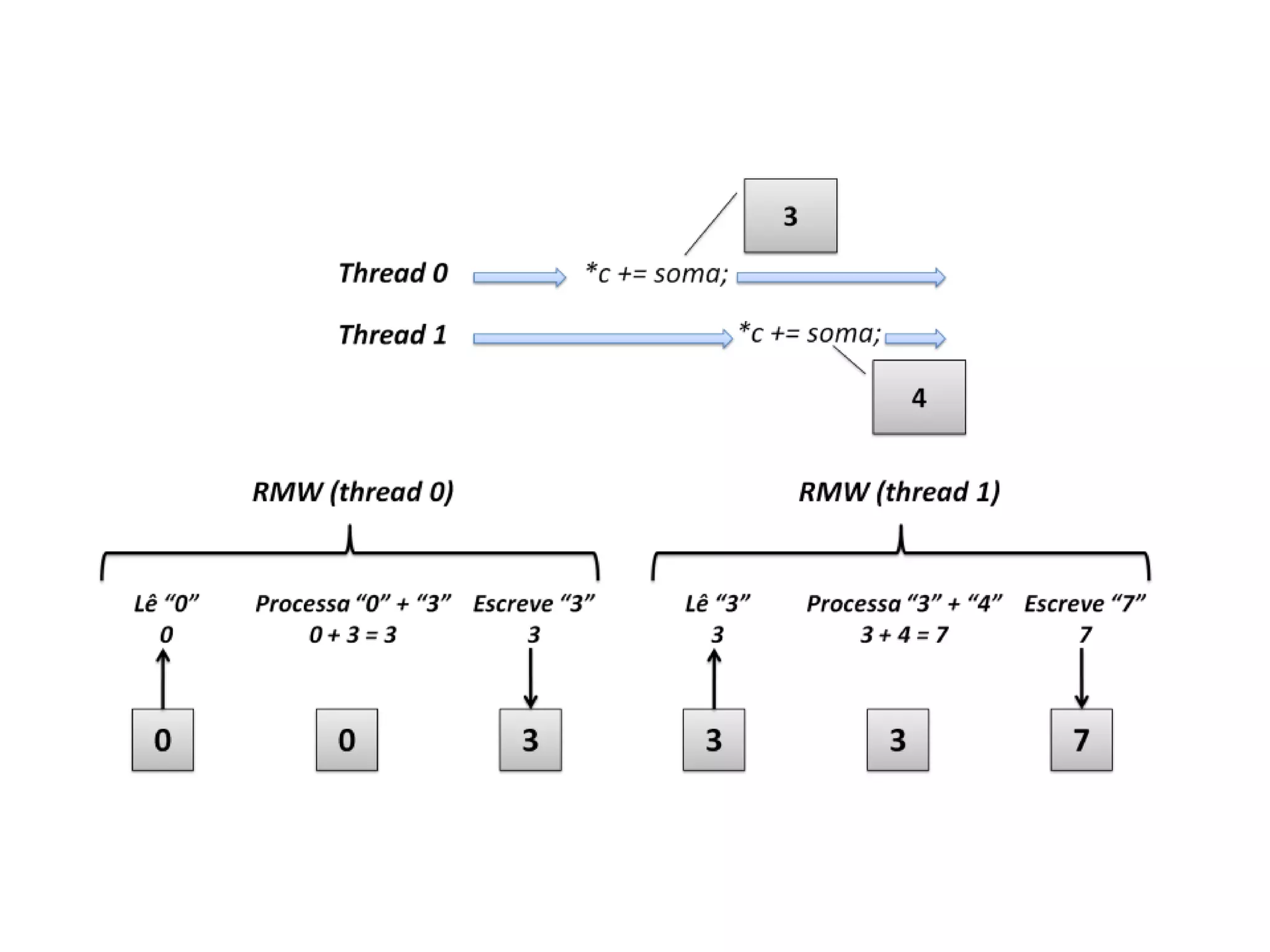
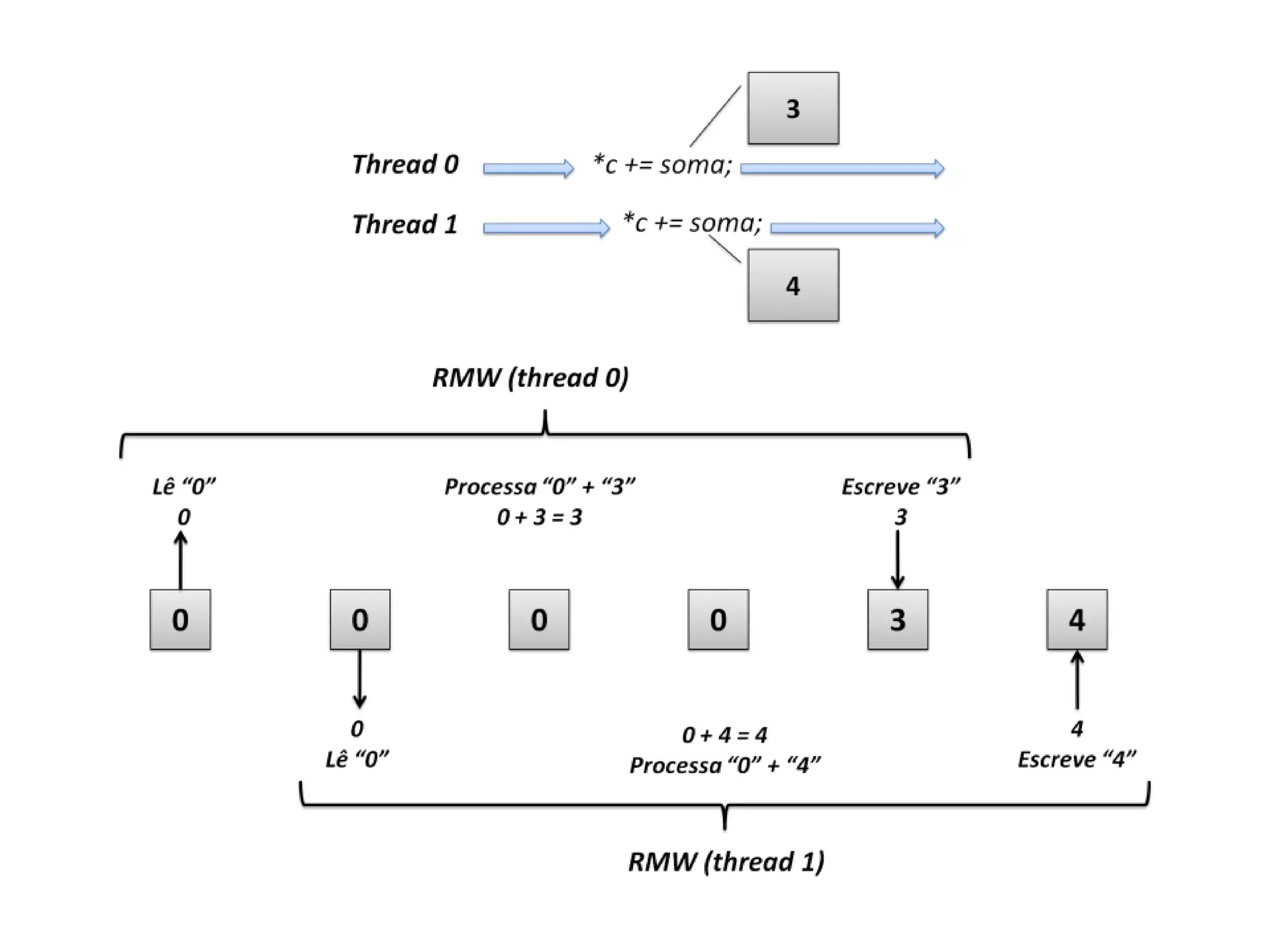
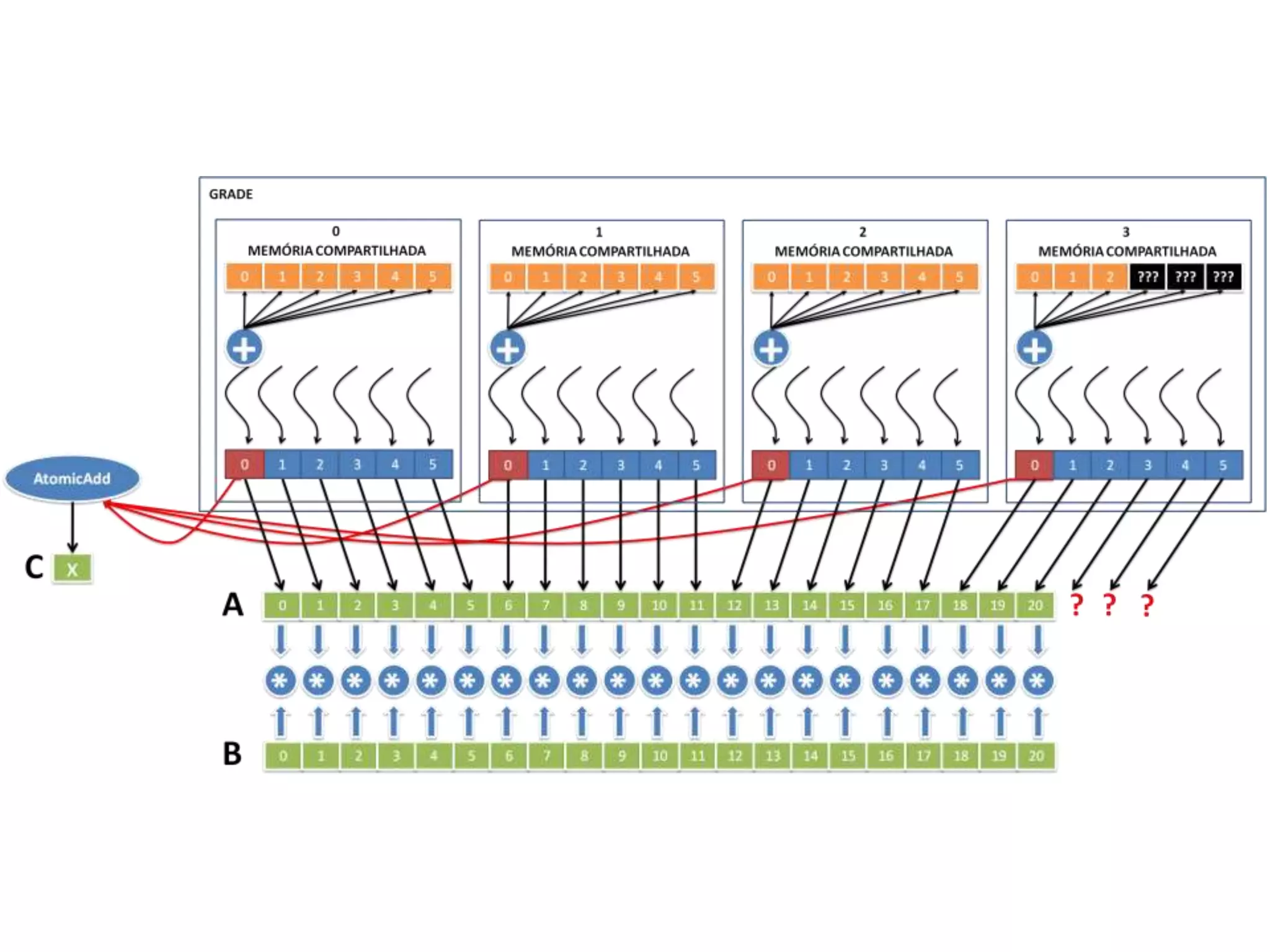

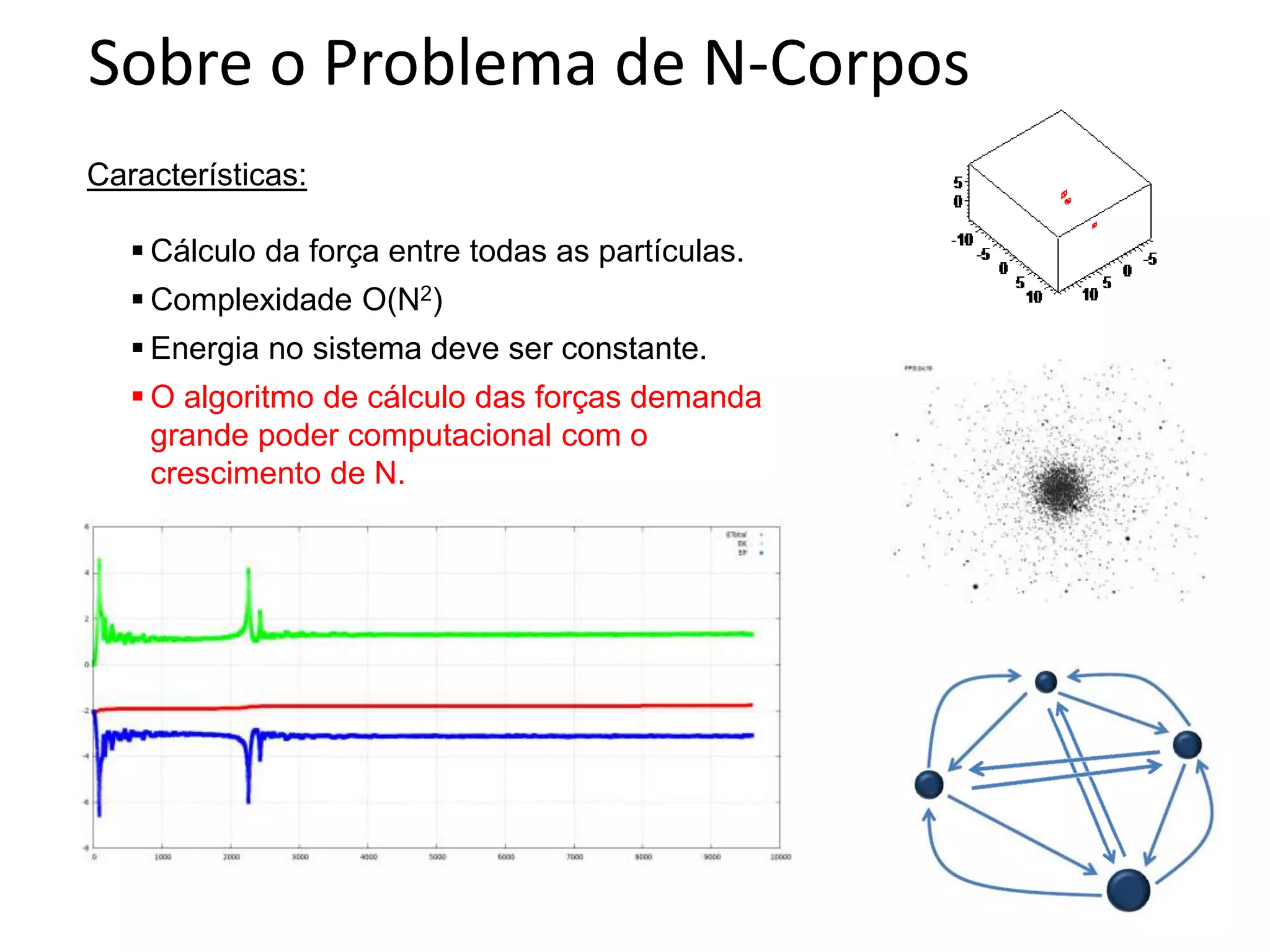

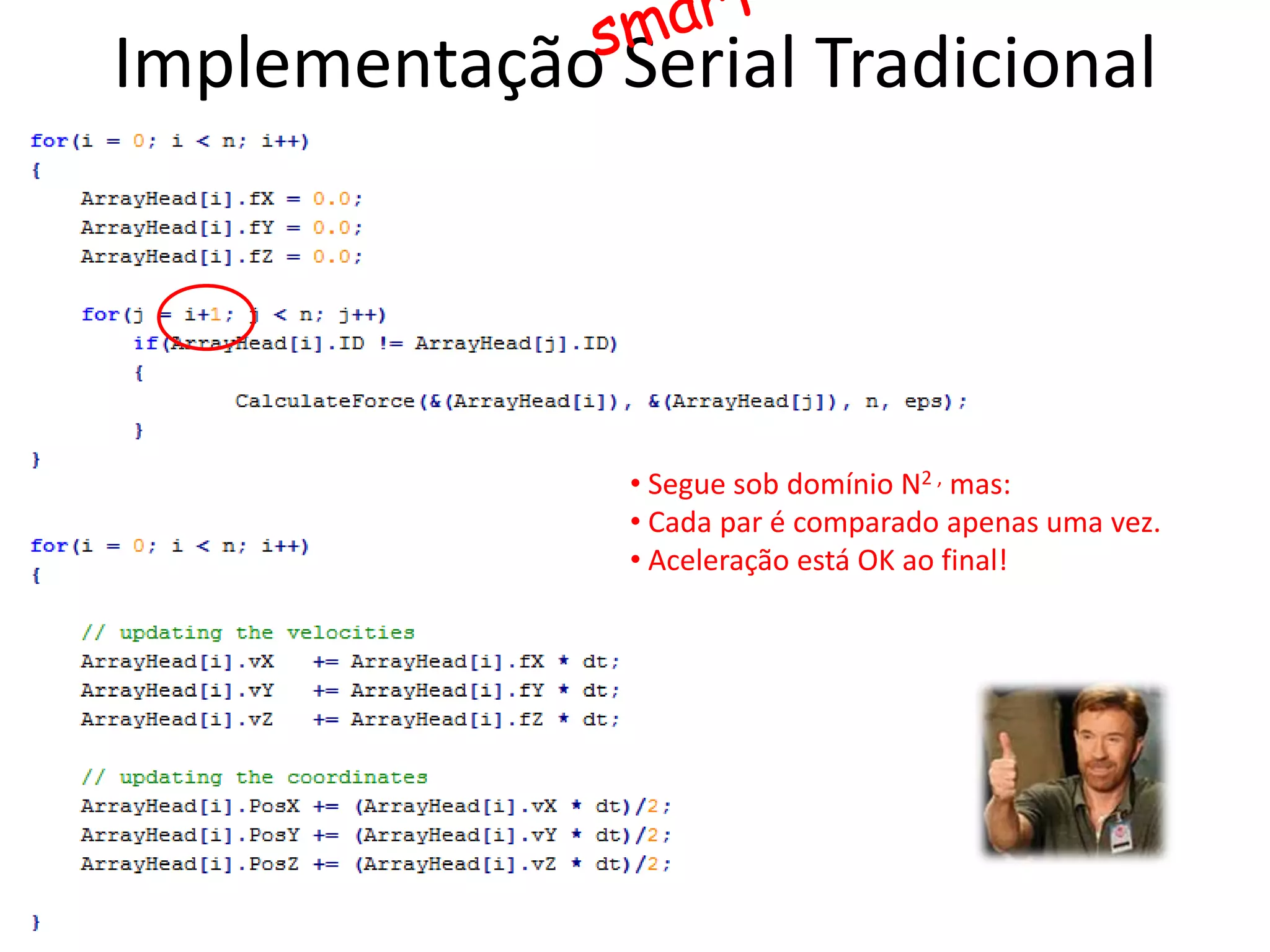

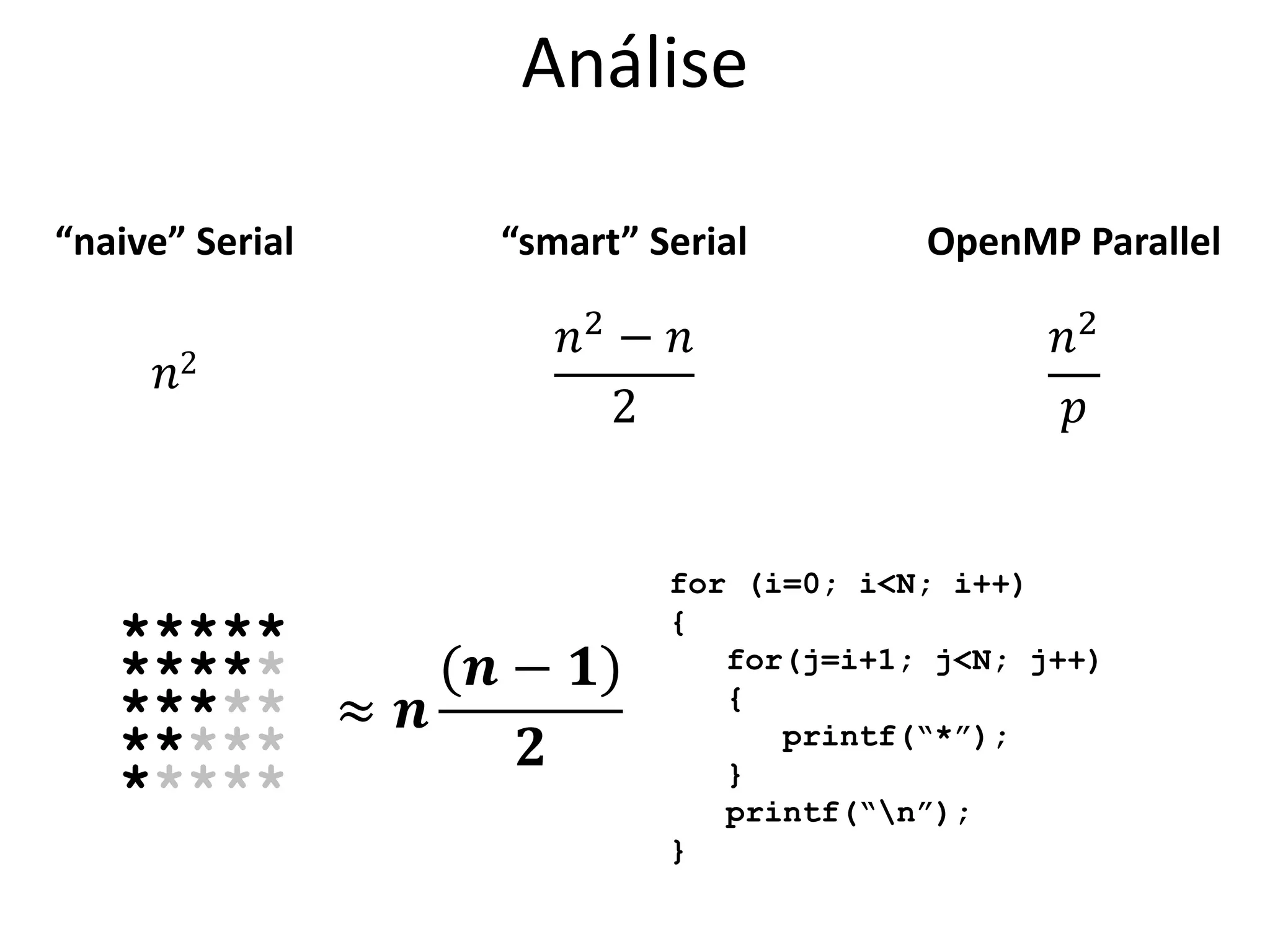













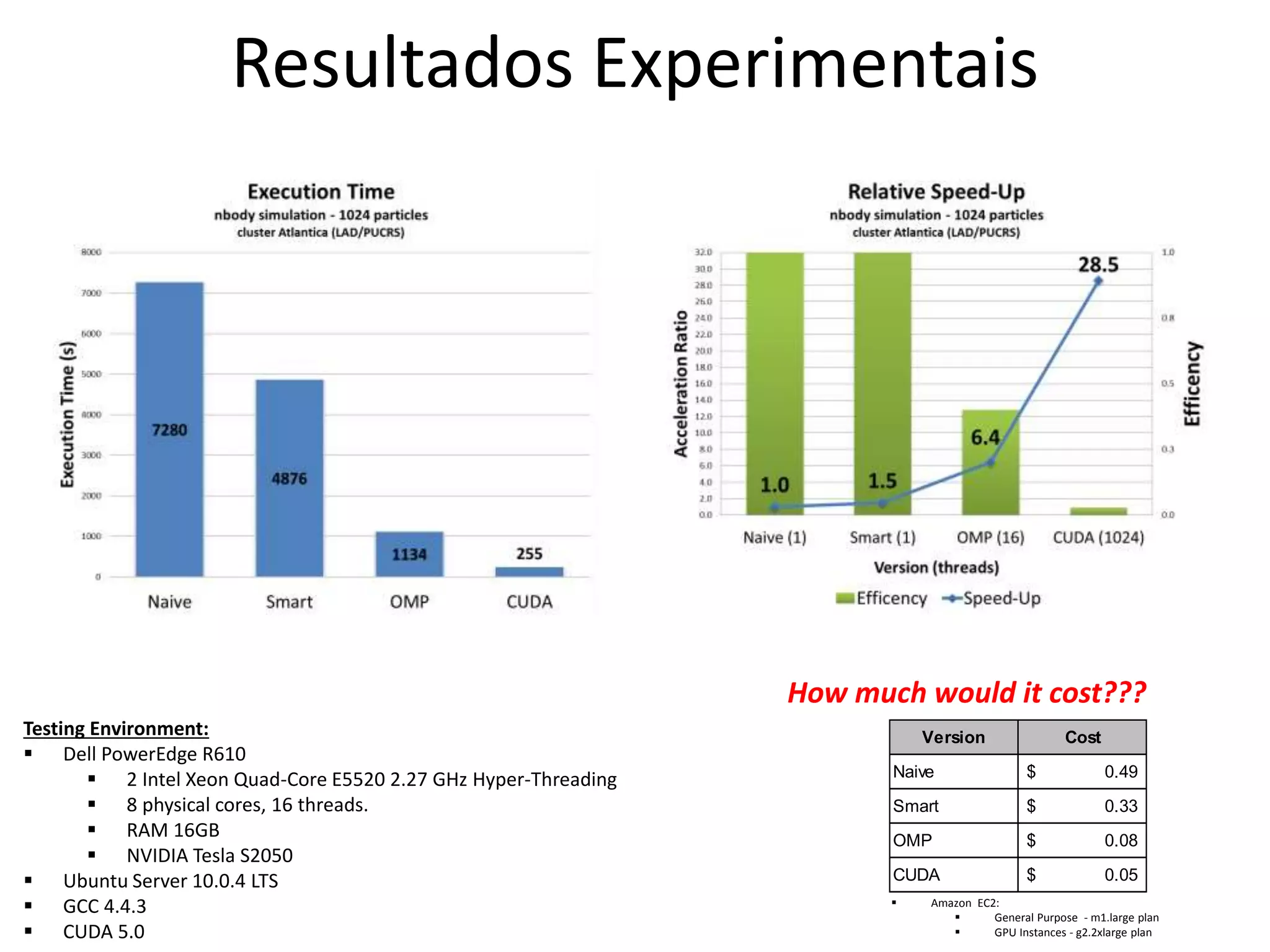
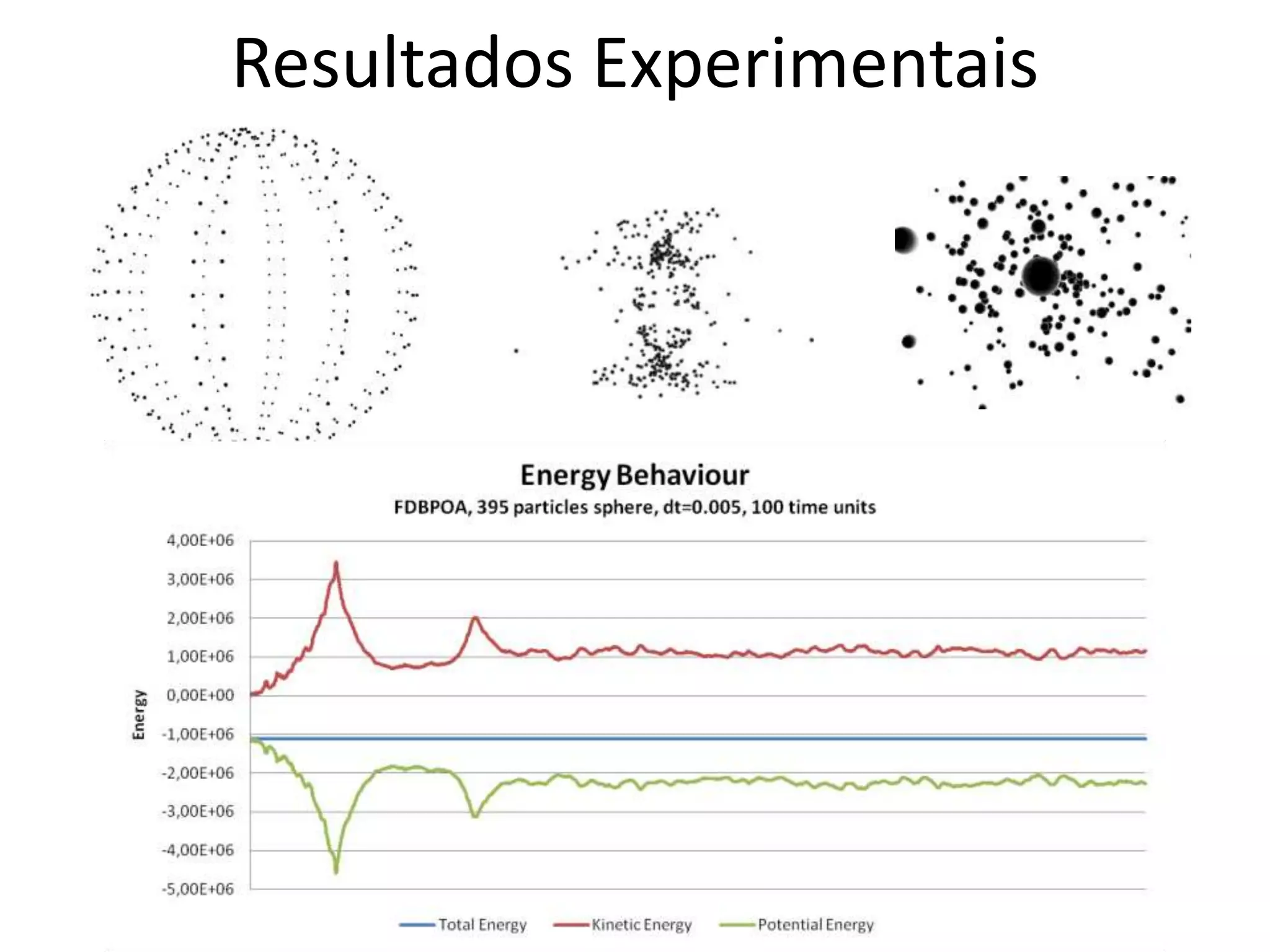
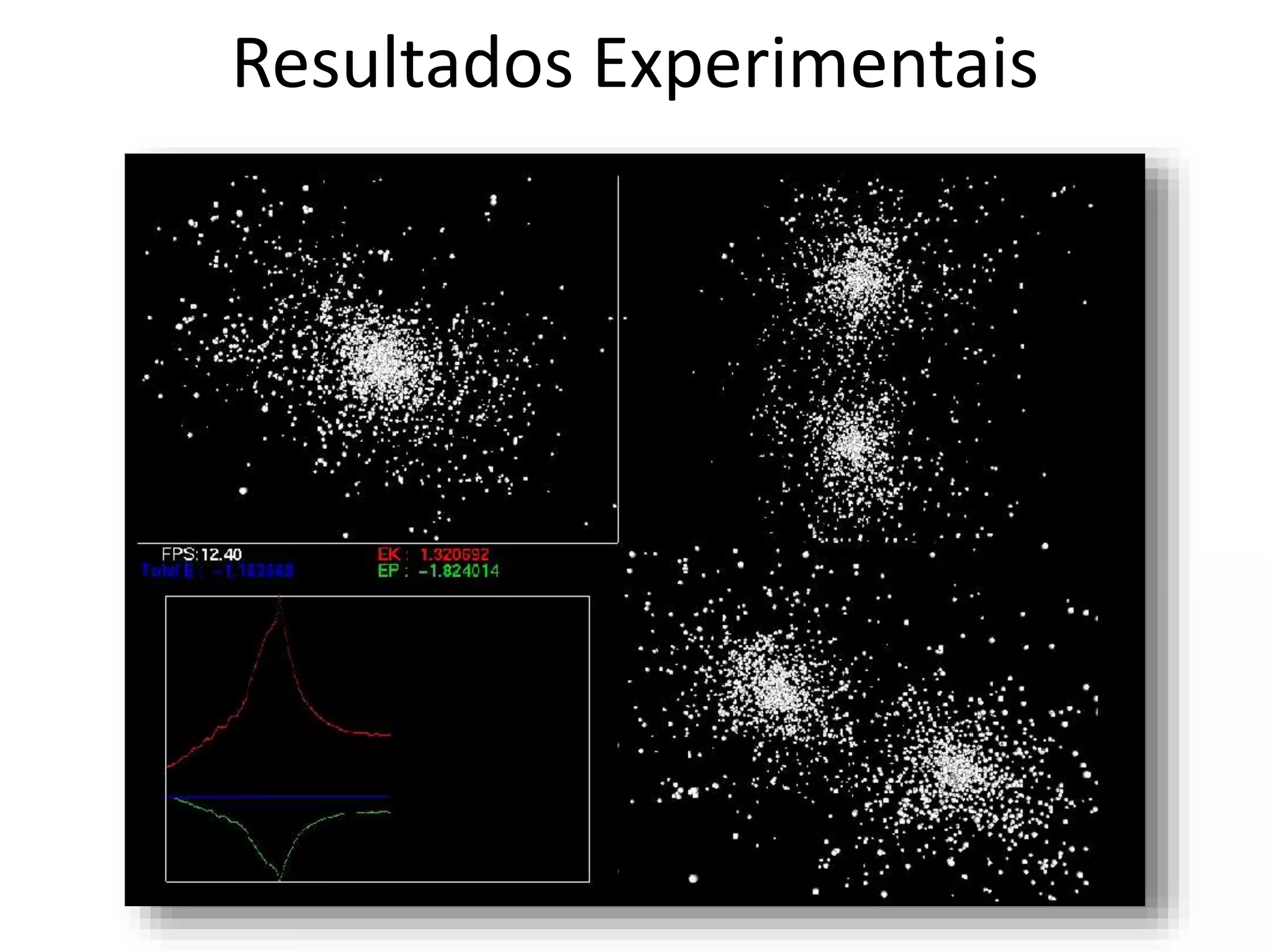
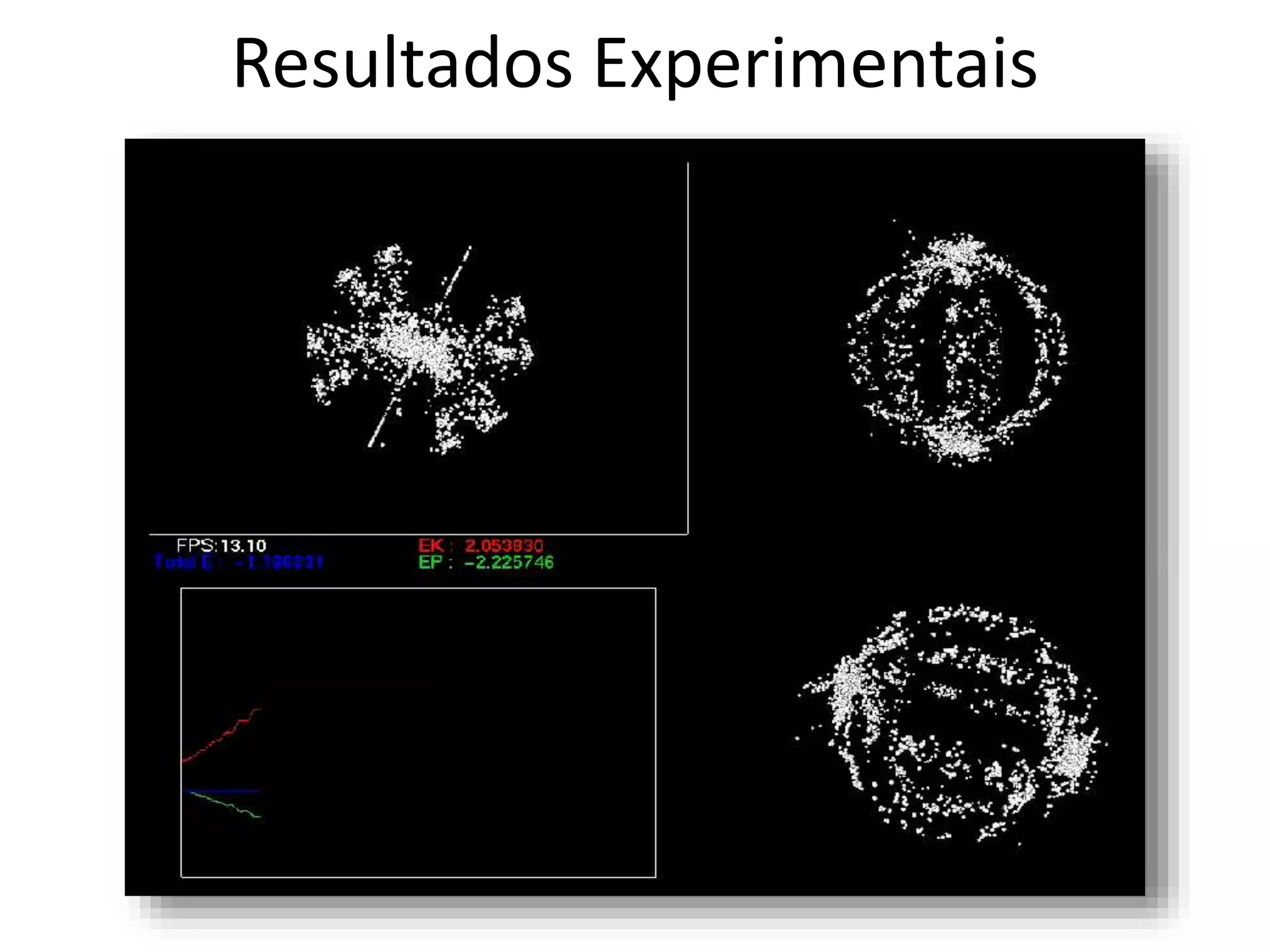








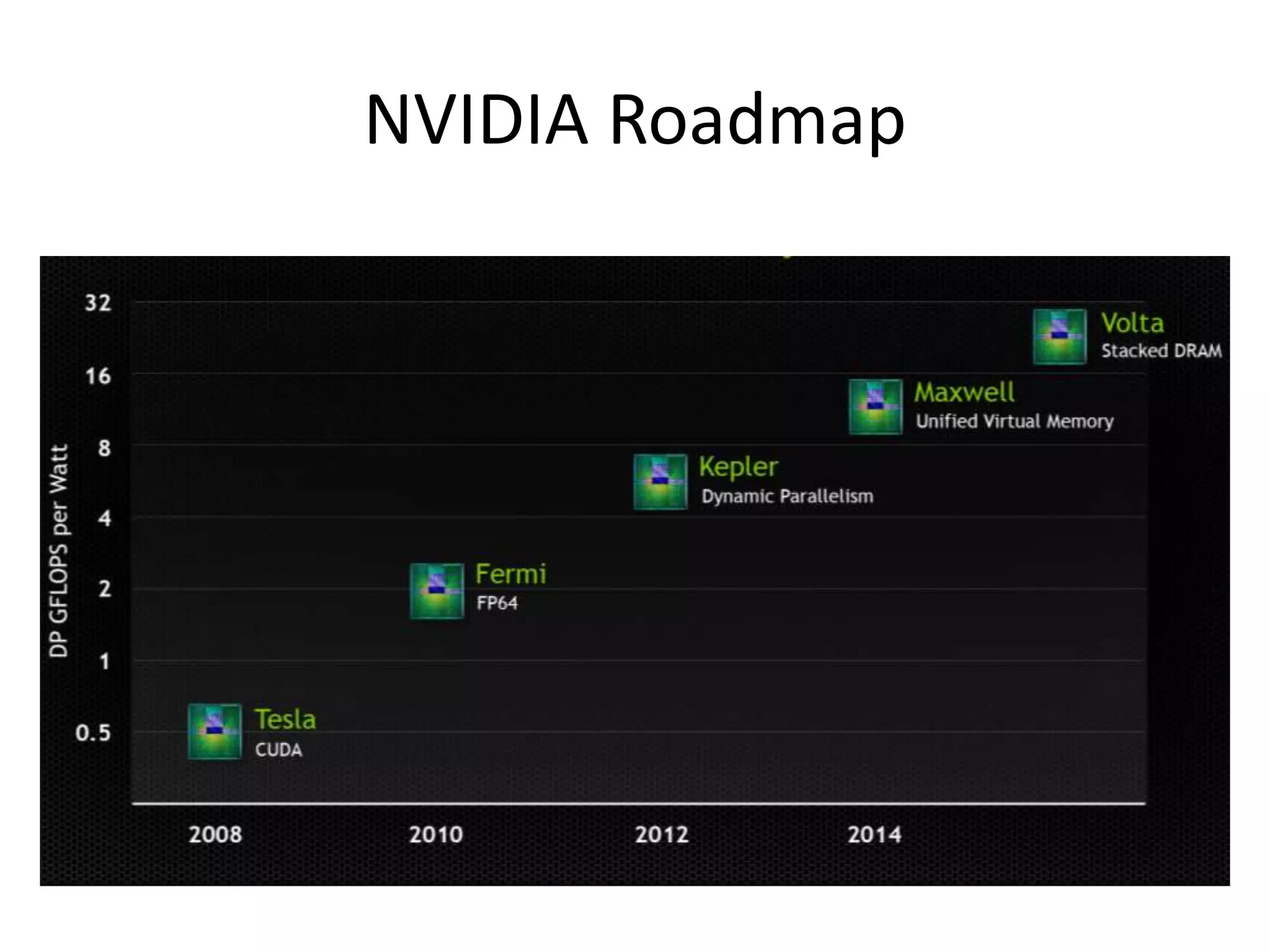


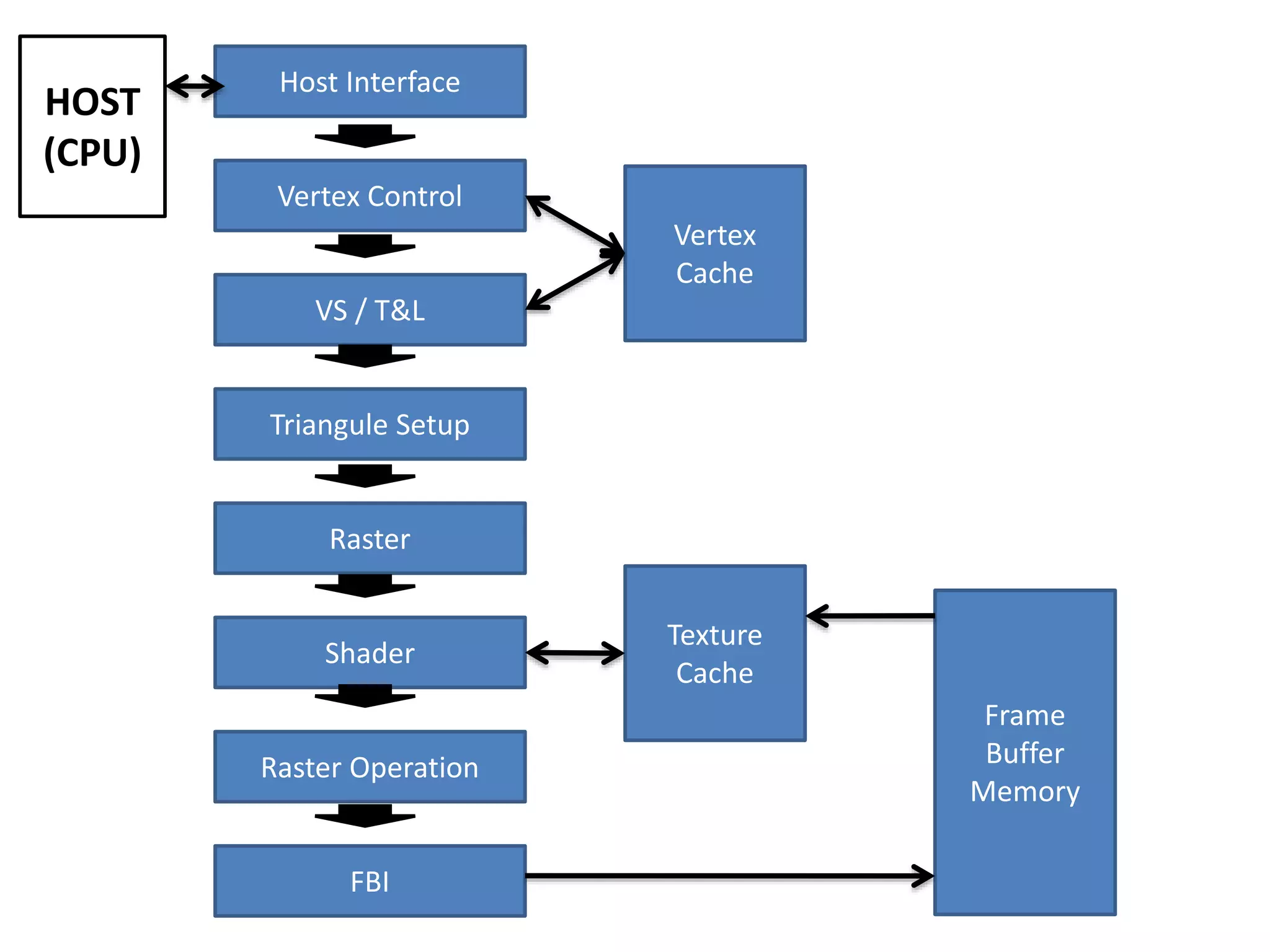
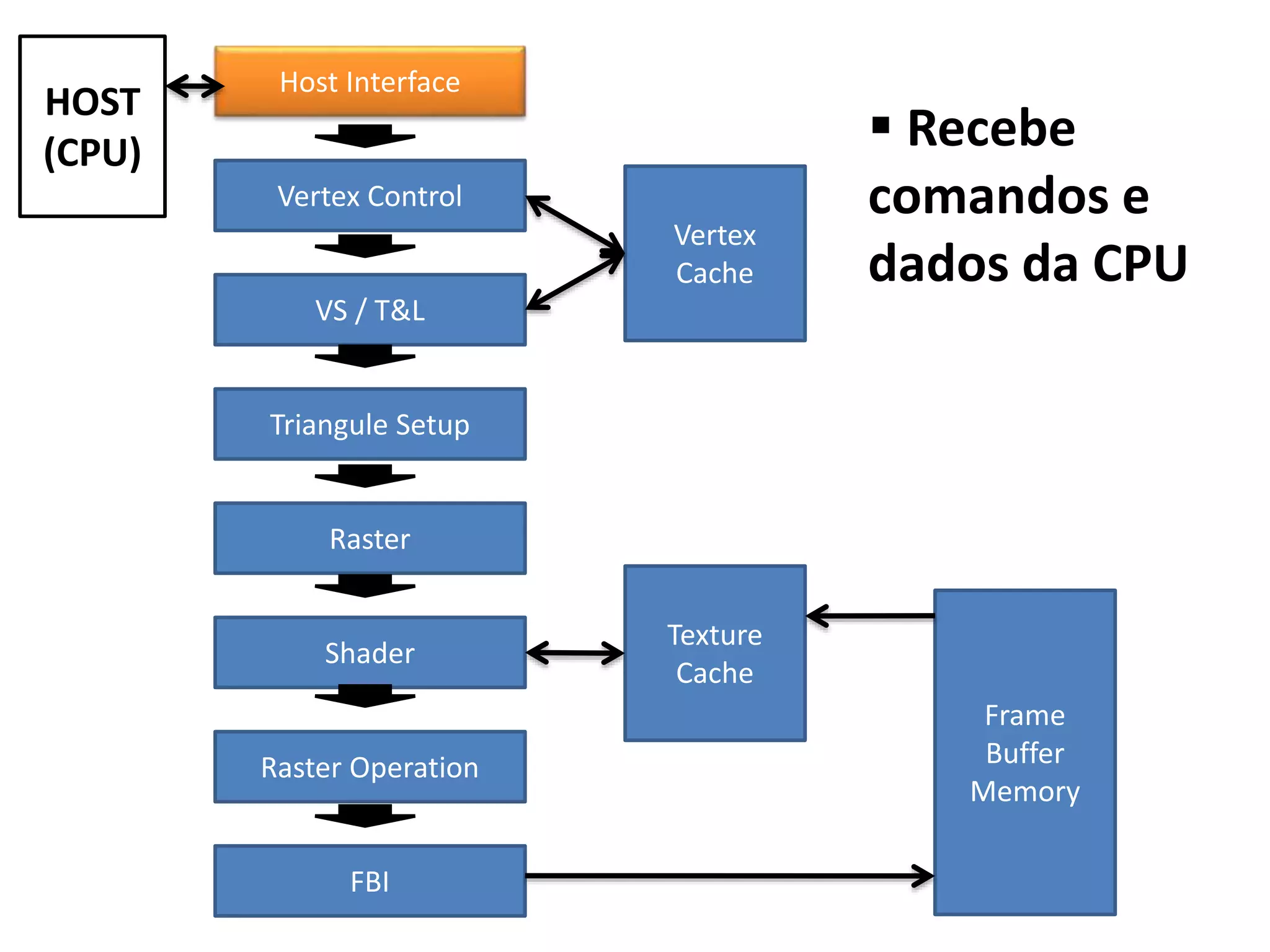
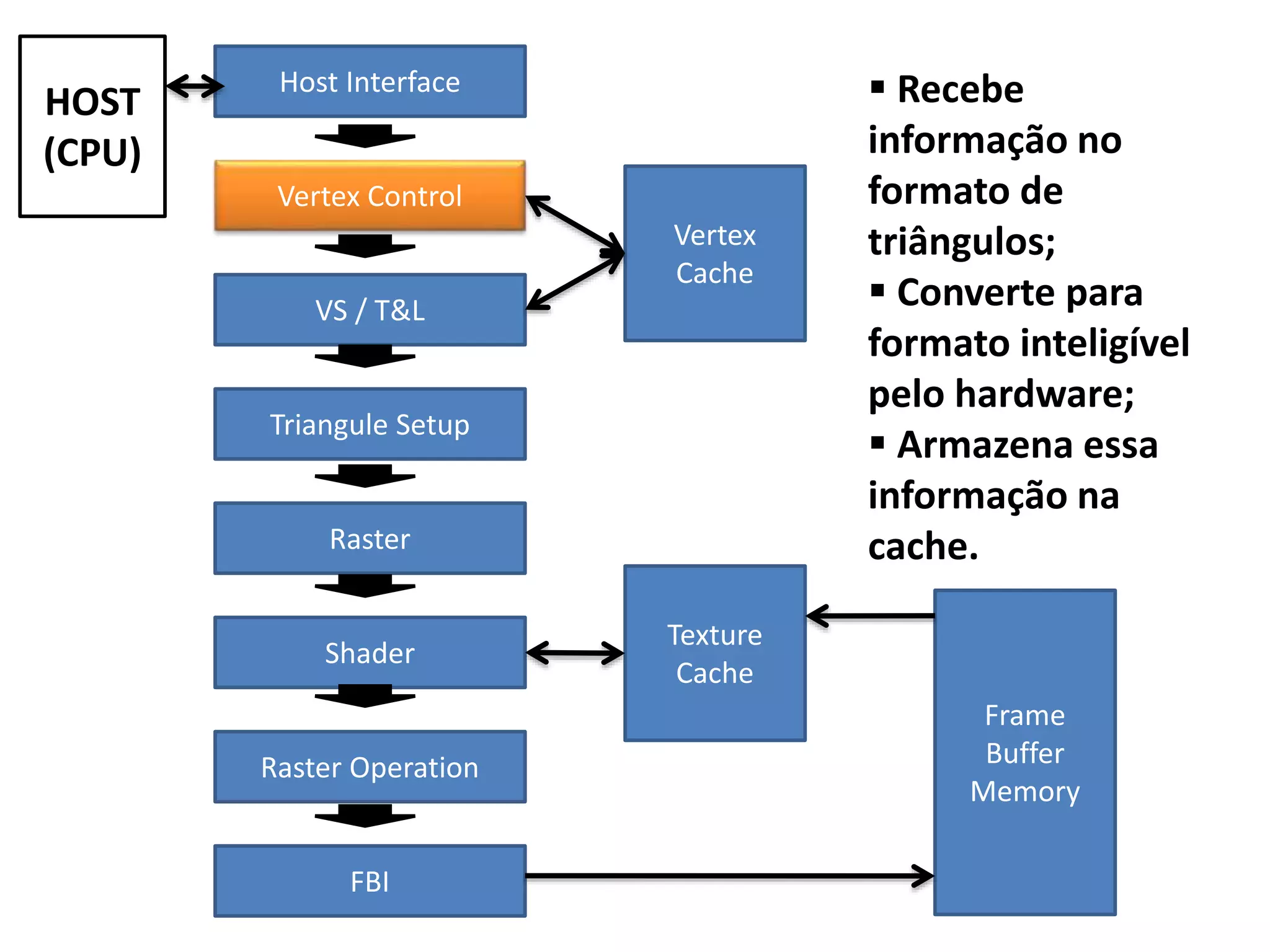
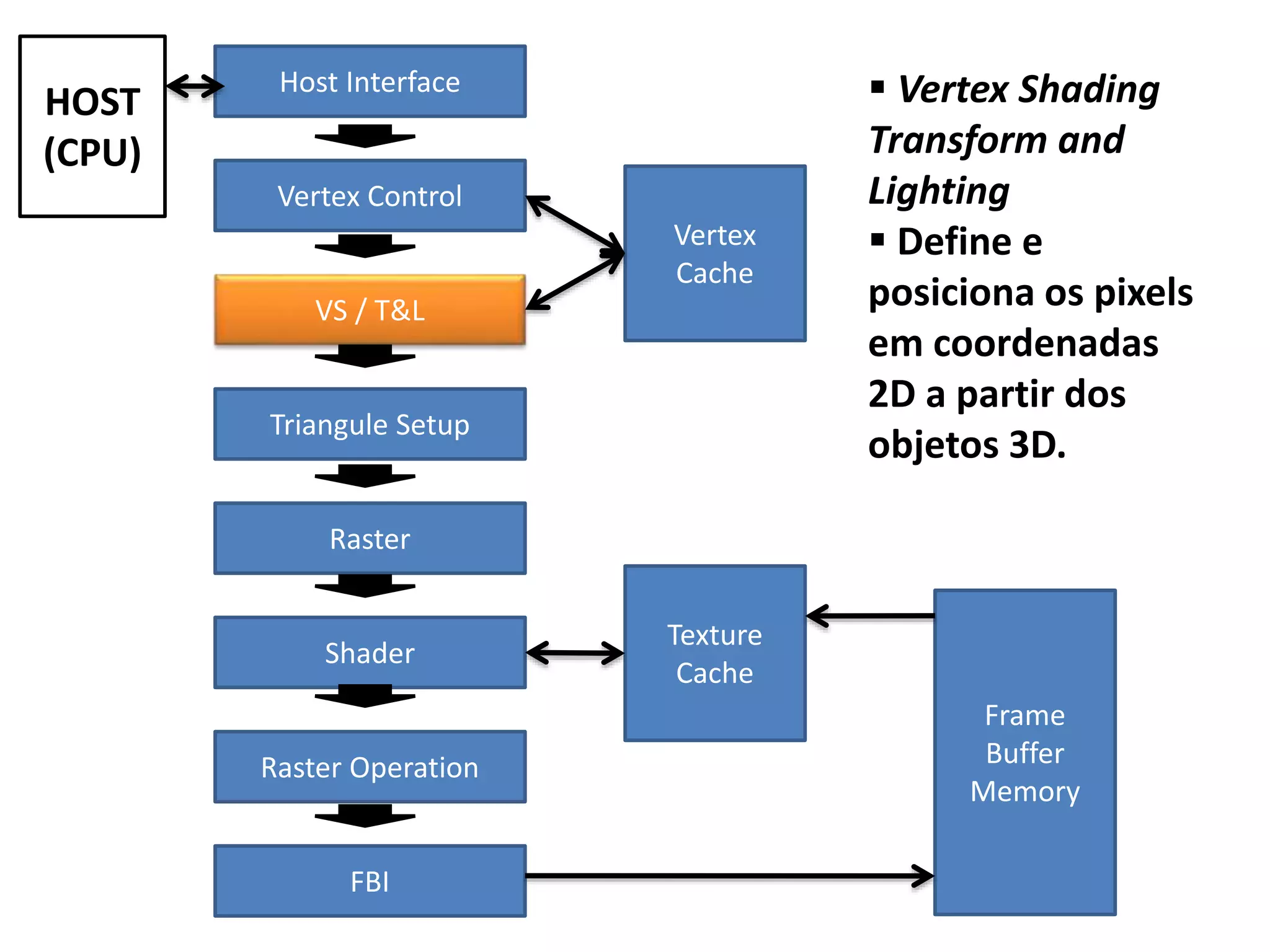
O documento apresenta um mini-curso sobre desenvolvimento de aplicações para GPU usando CUDA. A agenda inclui conceitos básicos sobre GPUs, uma breve história, programação CUDA e um estudo de caso comparativo entre CPU, OpenMP e CUDA para o problema de N-corpos.