Baixado 71 vezes






















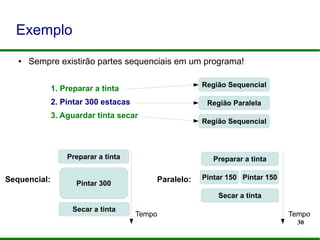



![37
Elementos do OpenMP
#pragma omp diretiva [cláusula]
omp_serviço(...)OMP_NOME](https://image.slidesharecdn.com/minicursoopenmp-130825201253-phpapp02/85/MiniCurso-Programacao-Paralela-com-OpenMP-SACTA-2013-37-320.jpg)
![38
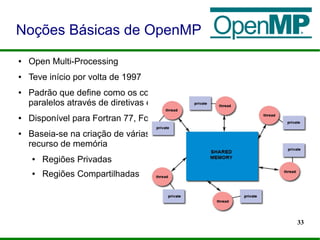
● Consiste em uma linha de código com significado especial para o
compilador.
● Identificadas pelo #pragma omp
● Formato padrão:
#pragma omp nome_diretiva [cláusula,...] novaLinha
● Inclusão header: “omp.h”
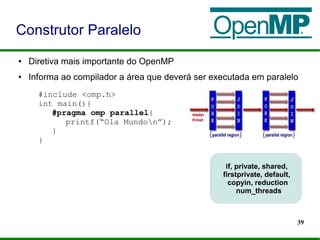
Diretivas de Compilação
Construtor Paralelo
Construtores de Compartilhamento de Trabalho
Diretivas de Sincronização](https://image.slidesharecdn.com/minicursoopenmp-130825201253-phpapp02/85/MiniCurso-Programacao-Paralela-com-OpenMP-SACTA-2013-38-320.jpg)
![40
● Exemplos:
● www.inf.ufrgs.br/~aflorenzon/curso_OpenMP/
● gcc nome_programa.c -o nome_saida -fopenmp
● hello.c e exemplo1.c
Construtor Paralelo
#include <omp.h>
int main(){
#pragma omp parallel
{
for(i=0;i<n;i++)
a[i] = b[i]+c[i];
}
}](https://image.slidesharecdn.com/minicursoopenmp-130825201253-phpapp02/85/MiniCurso-Programacao-Paralela-com-OpenMP-SACTA-2013-40-320.jpg)
![41
● Exemplos:
● www.inf.ufrgs.br/~aflorenzon/curso_OpenMP/
● gcc nome_programa.c -o nome_saida -fopenmp
● hello.c e exemplo1.c
Construtor Paralelo
#include <omp.h>
int main(){
#pragma omp parallel
{
for(i=0;i<n;i++)
a[i] = b[i]+c[i];
}
}
O que há de errado com
o código ao lado?](https://image.slidesharecdn.com/minicursoopenmp-130825201253-phpapp02/85/MiniCurso-Programacao-Paralela-com-OpenMP-SACTA-2013-41-320.jpg)
![42
● Exemplos:
● www.inf.ufrgs.br/~aflorenzon/curso_OpenMP/
● gcc nome_programa.c -o nome_saida -fopenmp
● hello.c e exemplo1.c
Construtor Paralelo
#include <omp.h>
int main(){
#pragma omp parallel
{
for(i=0;i<n;i++)
a[i] = b[i]+c[i];
}
}
O que há de errado com
o código ao lado?
Variáveis compartilhadas
entre todas as
threads, por padrão!](https://image.slidesharecdn.com/minicursoopenmp-130825201253-phpapp02/85/MiniCurso-Programacao-Paralela-com-OpenMP-SACTA-2013-42-320.jpg)
![43
● Exemplos:
● www.inf.ufrgs.br/~aflorenzon/curso_OpenMP/
● gcc nome_programa.c -o nome_saida -fopenmp
● hello.c e exemplo1.c
Construtor Paralelo
#include <omp.h>
int main(){
#pragma omp parallel private(i)
{
for(i=0;i<n;i++)
a[i] = b[i]+c[i];
}
}
Variáveis de controle
de laço devem ser
privadas à cada thread!](https://image.slidesharecdn.com/minicursoopenmp-130825201253-phpapp02/85/MiniCurso-Programacao-Paralela-com-OpenMP-SACTA-2013-43-320.jpg)
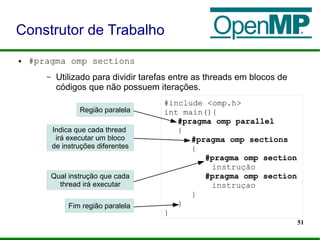
![44
● Construtor de Compartilhamento de Trabalho:
● Responsáveis pela distribuição de trabalho entre as threads e
determinam como o trabalho será dividido entre as threads.
● Necessariamente interna a uma região paralela.
#pragma omp construtor[clausula [clausula] …]
– #pragma omp for
– #pragma omp sections
– #pragma omp single
Construtor Paralelo](https://image.slidesharecdn.com/minicursoopenmp-130825201253-phpapp02/85/MiniCurso-Programacao-Paralela-com-OpenMP-SACTA-2013-44-320.jpg)

![46
● #pragma omp for
– Iterações dos laços for são executadas em paralelo.
– Número de iterações deve ser previamente conhecido e não
possui variação durante a execução – (while).
– Implementa SIMD (Single Instruction Multiple Data).
Construtor de Trabalho
#include <omp.h>
int main(){
#pragma omp parallel private(i)
{
#pragma omp for
for(i=0;i<n;i++)
a[i] = b[i]+c[i];
}
}
Ex: ex_omp_for_1.c](https://image.slidesharecdn.com/minicursoopenmp-130825201253-phpapp02/85/MiniCurso-Programacao-Paralela-com-OpenMP-SACTA-2013-46-320.jpg)




















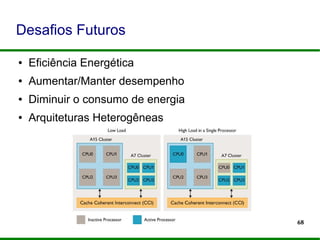









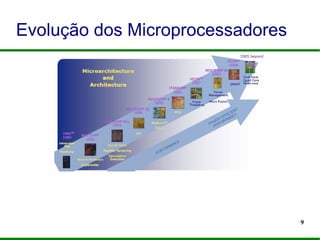
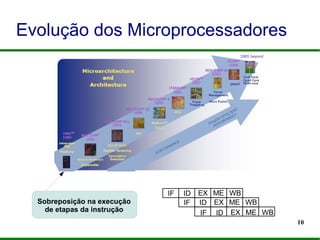
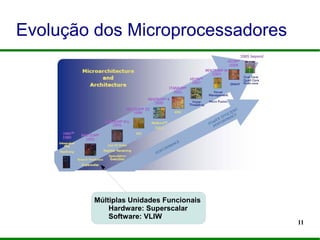
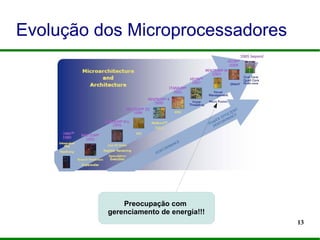
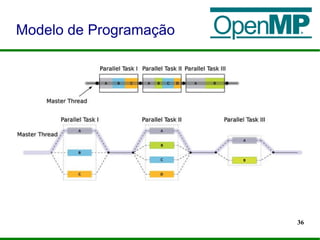
O documento apresenta um mini-curso sobre programação paralela utilizando OpenMP. Ele introduz os palestrantes e seus backgrounds, objetivos do curso, e um roteiro que inclui a evolução dos microprocessadores, programação paralela, OpenMP e desafios futuros.



































































