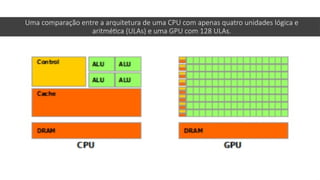
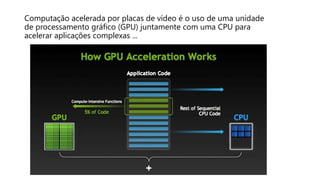
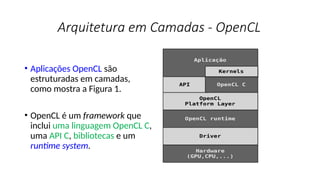
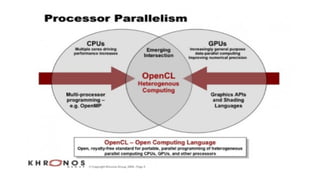
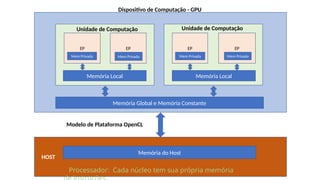
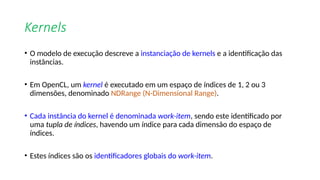
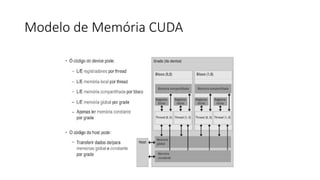
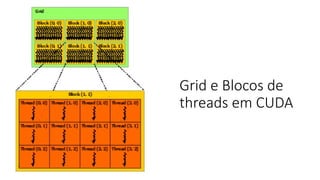
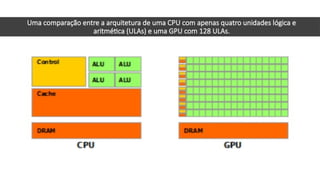
O documento apresenta uma introdução prática à programação em OpenCL, enfatizando suas capacidades para programação paralela em plataformas heterogêneas usando CPUs e GPUs. Destaca o uso de OpenCL para otimização de aplicações em diversas áreas, como jogos, simulações científicas e processamento de dados, e explica conceitos fundamentais associados à sua arquitetura e modelos de execução. Além disso, aborda como OpenCL se integra com outras tecnologias para maximizar o aproveitamento do poder computacional disponível.


















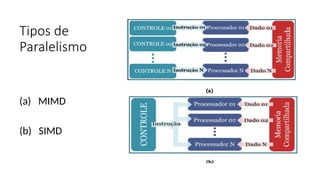
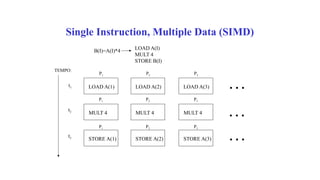
![SIMD - Single Instruction Multiple Data
•A idéia é que podemos adicionar os arrays A=[1,2,3,4]
e B=[5,6,7,8] para obter o array S=[6, 8, 10, 12] .
•Para isso, tem que haver quatro unidades aritméticas
no trabalho, mas todos podem compartilhar a mesma
instrução (aqui, "add").](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-20-320.jpg)









![OpenCL
• Neste contexto, surge OpenCL, criada pela Apple [Apple Inc. 2009] e padronizada
pelo Khronos Group [Khronos Group 2010a].
• Apple Inc. (2009). OpenCL Programming Guide for Mac OS X.
http: //developer.apple.com/mac/library/documentation/
Performance/Conceptual/OpenCL_MacProgGuide/Introduction/ Introduction.html.
• Khronos Group (2010a). OpenCL - The open standard for parallel programming of
heterogeneous systems. http://www.khronos.org/opencl/.](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-33-320.jpg)

![Código Sequencial em C
void ArrayDiff(const int* a,
const int* b, int* c, int n)
{
for (int i = 0; i < n; ++i)
{
c[i] = a[i] - b[i];
}
}](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-35-320.jpg)
![Código em OpenCL
__kernel void ArrayDiff(
__global const int* a,
__global const int* b,
__global int* c)
{
int id = get_global_id(0);
c[id] = a[id] - b[id];
}](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-36-320.jpg)








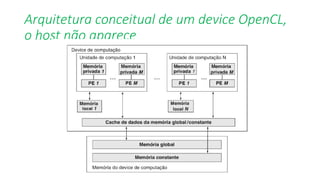
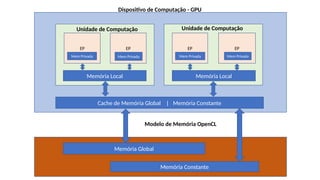






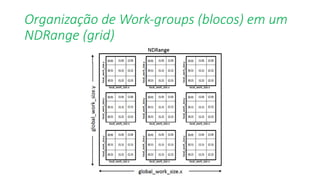



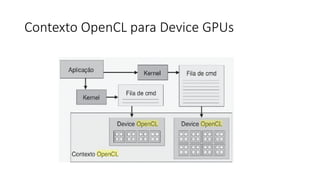













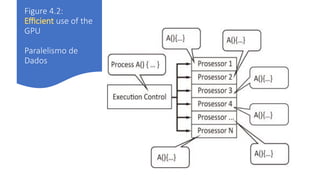

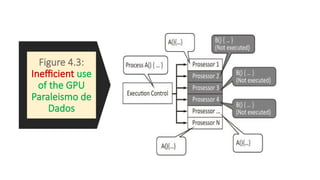











![List 4.8:
Data parallel model- kernel dataParallel.cl
1. __kernel void dataParallel(__global float* A, __global float* B,
__global float* C)
2.{
3. int base = 4*get_global_id(0);
4. C[base+0] = A[base+0] + B[base+0];
5. C[base+1] = A[base+1] - B[base+1];
6. C[base+2] = A[base+2] * B[base+2];
7. C[base+3] = A[base+3] / B[base+3];
8.}](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-93-320.jpg)




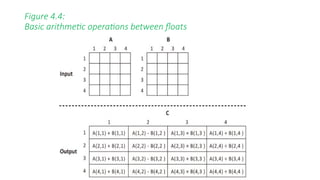
![Exemplo – Figura 4.5
• Neste exemplo, o work-item global é multiplicado por 4 e armazenado
na variável "base".
• Esse valor é usado para decidir qual elemento da matriz A e B é
processado.
1. C[base+0] = A[base+0] + B[base+0];
2. C[base+1] = A[base+1] - B[base+1];
3. C[base+2] = A[base+2] * B[base+2];
4. C[base+3] = A[base+3] / B[base+3];](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-98-320.jpg)




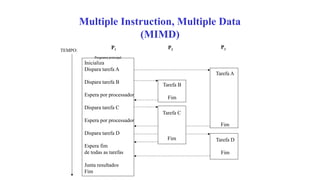
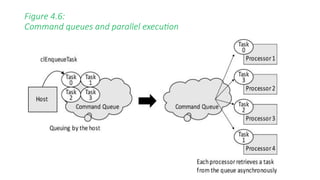
![The source code for the task parallel
model
• Neste modelo, diferentes kernels podem ser executados em paralelo.
• Note que diferentes kernels são implementados para cada uma das 4 operações
aritméticas.
1. /* Execute OpenCL kernel as task parallel */
2. for (i=0; i < 4; i++) {
3. ret = clEnqueueTask(command_queue, kernel[i], 0, NULL, NULL);
4. }
• O segmento de código acima enfileira os 4 kernels.](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-103-320.jpg)







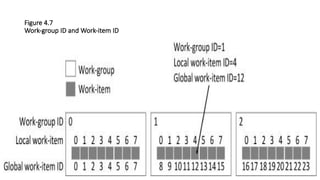
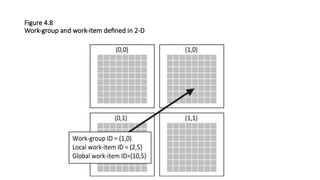

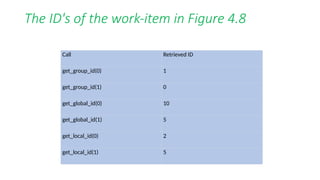






![/* Variáveis diversas da aplicação */
/* ponteiros para inteiros */
int* hostA;
int* hostB;
int* hostC;
/* The dimensions of the NDRange are specified as an N-element array of type size_t, where
N represents the number of dimensions used to describe the work-item being created. */
/* In the vector addition example, our data will be one-dimensional and assuming that there are
1024 elements, the size can be specified as a one-, two-, or three-dimensional vector. The host code
to specify an ND Range for 1024 elements is as follows:
size_t indexSpaceSize[3] = {1024, 1, 1}; */
size_t globalSize[1] = { ARRAY_LENGTH };
int i;](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-123-320.jpg)
![/* Código-fonte do kernel */
const char* source =
"__kernel void ArrayDiff(
__global const int* a,
__global const int* b,
__global int* c)
{
int id = get_global_id(0);
c[id] = a[id] - b[id];
}";](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-124-320.jpg)






















![Inicialização dos arrays no host
for (i = 0; i < ARRAY_LENGTH; ++i)
{
hostA[i] = rand() % 101 - 50;
hostB[i] = rand() % 101 - 50;
}](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-147-320.jpg)














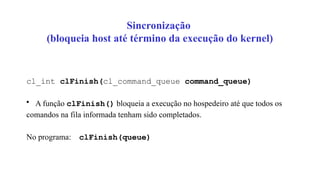




![Impressão dos resultados na saída padrão
for (i = 0; i < ARRAY_LENGTH; ++i)
printf("%d - %d = %dn", hostA[i], hostB[i],
hostC[i]);](https://image.slidesharecdn.com/apresentacaoopencl-240825155635-6d06c684/85/Apresentacao-da-linguagem-de-programa-opencp-com-comparacao-167-320.jpg)
























![[Pereira ic'2011] explorando o paralelismo no nível de threads](https://cdn.slidesharecdn.com/ss_thumbnails/pereiraic2011explorandooparalelismononveldethreads-111008083559-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





